S-ar putea să vă placă și
- Minería de Datos: Guía de Minería de Datos para Principiantes, que Incluye Aplicaciones para Negocios, Técnicas de Minería de Datos, Conceptos y MásDe la EverandMinería de Datos: Guía de Minería de Datos para Principiantes, que Incluye Aplicaciones para Negocios, Técnicas de Minería de Datos, Conceptos y MásEvaluare: 4.5 din 5 stele4.5/5 (4)
- BIG DATA - Técnicas, herramientas y aplicacionesDe la EverandBIG DATA - Técnicas, herramientas y aplicacionesEvaluare: 2 din 5 stele2/5 (1)
- Guia de Preguntas Big DataDocument10 paginiGuia de Preguntas Big DataFanny GarciaÎncă nu există evaluări
- Big BataDocument10 paginiBig Batavalentina martinezÎncă nu există evaluări
- Ta2 LogísticaDocument12 paginiTa2 LogísticaPaola EvangelistaÎncă nu există evaluări
- Big DataDocument2 paginiBig DataLuis HernándezÎncă nu există evaluări
- Tema Inv. #2Document9 paginiTema Inv. #2Adriana FloresÎncă nu există evaluări
- Big Data Grupo 6Document12 paginiBig Data Grupo 6Juan QuinchiguangoÎncă nu există evaluări
- A12 Investigación Big Data Grupo 6Document17 paginiA12 Investigación Big Data Grupo 6Samuel ArguetaÎncă nu există evaluări
- Big DataDocument3 paginiBig DataKevin GonzalezÎncă nu există evaluări
- Guia de Preguntas Big Data y OmnicanalDocument4 paginiGuia de Preguntas Big Data y OmnicanalFanny GarciaÎncă nu există evaluări
- Capitulo 6 Big DataDocument45 paginiCapitulo 6 Big DataSebastian RodríguezÎncă nu există evaluări
- Mineria de Datos y Big DataDocument6 paginiMineria de Datos y Big DataHolman SanabriaÎncă nu există evaluări
- Big Data, Una Realidad Que Está Cambiando Nuestra Vida - MasScienceDocument6 paginiBig Data, Una Realidad Que Está Cambiando Nuestra Vida - MasScienceGambito Chuarliecads TrrereÎncă nu există evaluări
- Big Data en Pocas PalabrasDocument20 paginiBig Data en Pocas PalabrasEdward CarrascalÎncă nu există evaluări
- Macrodatos - BigQuery Frank OtoroncoDocument10 paginiMacrodatos - BigQuery Frank OtoroncoCristian alexsander nieto MartínezÎncă nu există evaluări
- Apuntes Unidad 2 Industria 4Document12 paginiApuntes Unidad 2 Industria 4Aleinad RodríguezÎncă nu există evaluări
- Seguridad y Control en Big Data PDFDocument15 paginiSeguridad y Control en Big Data PDFstanley1972Încă nu există evaluări
- Big DataDocument2 paginiBig DataCarmen GonzalesÎncă nu există evaluări
- Proyecto IntegradorDocument5 paginiProyecto Integradorsaavedracardozaadriana01Încă nu există evaluări
- Introduccion Analitica de DatosDocument10 paginiIntroduccion Analitica de DatosDavid EscobarÎncă nu există evaluări
- Exposicion BIG DATADocument16 paginiExposicion BIG DATAKAREN ANDREA RINCON RODRIGUEZÎncă nu există evaluări
- Abel Jimenez Guia Sobre Big Data y OmnicanalDocument8 paginiAbel Jimenez Guia Sobre Big Data y OmnicanalAbelAlexanderJimenezCastroÎncă nu există evaluări
- Big Data - Resumen Primer ParcialDocument28 paginiBig Data - Resumen Primer ParcialAnonymous yuNUL3Încă nu există evaluări
- Equipo #7 A12Document16 paginiEquipo #7 A12Samuel ArguetaÎncă nu există evaluări
- Introduccion Analitica de DatosDocument10 paginiIntroduccion Analitica de DatosDavid EscobarÎncă nu există evaluări
- Big Data ImprimirDocument3 paginiBig Data ImprimirMelissa Garcia cortijoÎncă nu există evaluări
- Evidencia 1 - Big Data AvanceDocument4 paginiEvidencia 1 - Big Data Avancefiorella de los milagros vasques yamunaqueÎncă nu există evaluări
- Documento de Apoyo - Fundamentos Del Big DataDocument15 paginiDocumento de Apoyo - Fundamentos Del Big DataADRIAN DAVID ROSADO GUERRAÎncă nu există evaluări
- InvestigacionDocument34 paginiInvestigacionROBERTO CARLOS RODRIGUEZ MERIDAÎncă nu există evaluări
- Seguridad y Control en Big DataDocument15 paginiSeguridad y Control en Big DataLuis Gonzalez AlarconÎncă nu există evaluări
- Cómo Construir Un Plan de Data Governance en Big DataDocument4 paginiCómo Construir Un Plan de Data Governance en Big DataMónica DiazÎncă nu există evaluări
- Big DataDocument3 paginiBig DataLeonel AmayaÎncă nu există evaluări
- PowerData Big DataDocument22 paginiPowerData Big DataJefferson Quispe PinaresÎncă nu există evaluări
- Tarea 4 Tecnología Aplicada A Los Negocios CompletaDocument12 paginiTarea 4 Tecnología Aplicada A Los Negocios CompletaFaudy GomezÎncă nu există evaluări
- Big DataDocument6 paginiBig DataBrayan Vargas CalcinaÎncă nu există evaluări
- Big DataDocument6 paginiBig DataJesús DíazÎncă nu există evaluări
- Introducing A Big Data. Sanchez Obando Alan DanielDocument4 paginiIntroducing A Big Data. Sanchez Obando Alan DanielAlan SanchezÎncă nu există evaluări
- A15 LagrDocument14 paginiA15 LagrLuis angel GonzalezÎncă nu există evaluări
- P1-Big DataDocument10 paginiP1-Big DataIRENE DOMINGUEZ LAFUENTEÎncă nu există evaluări
- Presentación1 TecDocument8 paginiPresentación1 TecHugo MalpicaÎncă nu există evaluări
- 1 y 2 - Fundamentos y Estructura Tecnologica de BIG DATADocument50 pagini1 y 2 - Fundamentos y Estructura Tecnologica de BIG DATAOrlando SotoÎncă nu există evaluări
- Big Data WordDocument9 paginiBig Data WordPamela QuintoÎncă nu există evaluări
- Introducción Al Big DataDocument25 paginiIntroducción Al Big DataJosé Roberto GutiérrezÎncă nu există evaluări
- Big Data - Trabajo GrupalDocument14 paginiBig Data - Trabajo GrupalJANARA ASLEHY GARCIA FUENTESÎncă nu există evaluări
- Aa1 - Big DataDocument19 paginiAa1 - Big DataJOSE LUIS NUÑEZ SOTOÎncă nu există evaluări
- Big DataDocument3 paginiBig DataSamantha De La BarreraÎncă nu există evaluări
- El Papel Del Big Data en La Transformación Digital Lec1Document4 paginiEl Papel Del Big Data en La Transformación Digital Lec1CristhianTrujilloÎncă nu există evaluări
- Cuadro Comparativo Big DataDocument1 paginăCuadro Comparativo Big DataMONICA ARIAS MENDEZÎncă nu există evaluări
- Guia Big Data AEPD-IsMS ForumDocument40 paginiGuia Big Data AEPD-IsMS ForumdfjarÎncă nu există evaluări
- Universidad Nacional Mayor de San Marcos: Base de Datos: BIG DATADocument22 paginiUniversidad Nacional Mayor de San Marcos: Base de Datos: BIG DATADiego Alcides Carrión RamosÎncă nu există evaluări
- Minería de Datos y Aplicaciones: Fernando Virseda Benito Javier Román CarrilloDocument8 paginiMinería de Datos y Aplicaciones: Fernando Virseda Benito Javier Román CarrilloDan MejiaÎncă nu există evaluări
- Big Data EnsayoDocument29 paginiBig Data EnsayoxXPredatorXxÎncă nu există evaluări
- Big Data Hagamos Hablar A Los DatosDocument2 paginiBig Data Hagamos Hablar A Los DatosValeria MassonÎncă nu există evaluări
- 003 Big DataDocument7 pagini003 Big DataOscarCastilloOrosÎncă nu există evaluări
- InteligenciaNegocios Tema 12Document8 paginiInteligenciaNegocios Tema 12JOSE IGNACIO YANEZ FREIREÎncă nu există evaluări
- Big Data ModelamientoDocument16 paginiBig Data ModelamientoJHASMIN JHENNIFER ARANDA CRISTOBALÎncă nu există evaluări
- Guia Codigo de Buenas Practicas Proyectos de Big DataDocument40 paginiGuia Codigo de Buenas Practicas Proyectos de Big Datafbolanosr7256Încă nu există evaluări
- Entregable 1Document5 paginiEntregable 1Luis Vi llamar malvaezÎncă nu există evaluări
- A14 DGRDocument5 paginiA14 DGRXime RangelÎncă nu există evaluări
- Tipos de Razon Social en Empresas - Gestion Contable y FinancieraDocument17 paginiTipos de Razon Social en Empresas - Gestion Contable y FinancieraEDGAR DANIEL ROLON CARRILLOÎncă nu există evaluări
- Aplicación de Los Patrones de Diseño de Software - Patrones de Diseño de SoftwareDocument37 paginiAplicación de Los Patrones de Diseño de Software - Patrones de Diseño de SoftwareEDGAR DANIEL ROLON CARRILLOÎncă nu există evaluări
- Taller de Repaso - Gestion Contable y FinancieraDocument2 paginiTaller de Repaso - Gestion Contable y FinancieraEDGAR DANIEL ROLON CARRILLOÎncă nu există evaluări
- MaestriaEducatronica PDFDocument9 paginiMaestriaEducatronica PDFEDGAR DANIEL ROLON CARRILLOÎncă nu există evaluări
- ExamenResuelto Olimpiada Quimica 2015 PDFDocument7 paginiExamenResuelto Olimpiada Quimica 2015 PDFEDGAR DANIEL ROLON CARRILLOÎncă nu există evaluări
- Actividad 6 - Nuevas TecnologiasDocument1 paginăActividad 6 - Nuevas TecnologiasEDGAR DANIEL ROLON CARRILLOÎncă nu există evaluări
- Matriz DofaDocument4 paginiMatriz DofaEDGAR DANIEL ROLON CARRILLOÎncă nu există evaluări
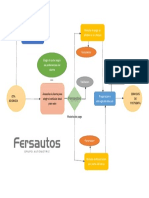
- Diagrama BPMN - FersautosDocument1 paginăDiagrama BPMN - FersautosEDGAR DANIEL ROLON CARRILLOÎncă nu există evaluări
- Actividad 4 - Nuevas TecnologiasDocument1 paginăActividad 4 - Nuevas TecnologiasEDGAR DANIEL ROLON CARRILLOÎncă nu există evaluări
- Que Es El Modelo de Proceso de NegocioDocument7 paginiQue Es El Modelo de Proceso de NegocioEDGAR DANIEL ROLON CARRILLOÎncă nu există evaluări
- Fisica Electrica Taller 1Document2 paginiFisica Electrica Taller 1EDGAR DANIEL ROLON CARRILLOÎncă nu există evaluări
- Métodos Numéricos: F (X) 9.36 21.963 X +16.2965 XDocument1 paginăMétodos Numéricos: F (X) 9.36 21.963 X +16.2965 XEDGAR DANIEL ROLON CARRILLOÎncă nu există evaluări
- Caso IDocument7 paginiCaso ILee HansonÎncă nu există evaluări
- 2021 590-125 Sistemas Electrotécnicos y Automáticos-1Document10 pagini2021 590-125 Sistemas Electrotécnicos y Automáticos-1Alfonso Martos TorresÎncă nu există evaluări
- TF Edificios Grupo7Document162 paginiTF Edificios Grupo7MERLY JOAMELY PEÑA HUERTASÎncă nu există evaluări
- Brochure EsavDoc DigitalDocument8 paginiBrochure EsavDoc DigitalCarlos ArceÎncă nu există evaluări
- Catalogo MacroledDocument79 paginiCatalogo MacroledCompras Fuertesvientos0% (1)
- Laboratorio #6 - Determinación de Sílice en CementoDocument13 paginiLaboratorio #6 - Determinación de Sílice en CementoPAMELA GABRIELA PACHO HUANACUNIÎncă nu există evaluări
- Distribuidor Oro 2018 BDocument64 paginiDistribuidor Oro 2018 BMargarita Hernandez VargasÎncă nu există evaluări
- Colonia HormigasDocument4 paginiColonia HormigasReynaldo HurtadoÎncă nu există evaluări
- Triptico Ing. MaaterialesDocument3 paginiTriptico Ing. MaaterialesJesus Armando Damian SiesquenÎncă nu există evaluări
- Lagg 1M PDFDocument2 paginiLagg 1M PDFlimbert_Încă nu există evaluări
- Ejemplo G68Document4 paginiEjemplo G68Abinadab Ahumada RuelasÎncă nu există evaluări
- 4 Respuestas p110 PDFDocument1 pagină4 Respuestas p110 PDFJR VegaÎncă nu există evaluări
- Catalogo Muebles-Casa Creative-Febrero 2023 - CompressedDocument175 paginiCatalogo Muebles-Casa Creative-Febrero 2023 - Compressedhxh75vtkdbÎncă nu există evaluări
- Predimensionamiento de Vigas y Losa AligeradaDocument4 paginiPredimensionamiento de Vigas y Losa AligeradaAxcell Leonardo Barrenechea RamosÎncă nu există evaluări
- Carta CDocument4 paginiCarta CSergioLopezBarriosÎncă nu există evaluări
- Practica EvaporacionDocument21 paginiPractica EvaporacionMelissa Veneros RicharteÎncă nu există evaluări
- Domina Los Punteros Con Formato ANY - PROGRAMACIÓN SIEMENSDocument7 paginiDomina Los Punteros Con Formato ANY - PROGRAMACIÓN SIEMENSaÎncă nu există evaluări
- FDS Dynatrans AC SAE 30-01 PDFDocument8 paginiFDS Dynatrans AC SAE 30-01 PDFGerardo Pizarro NaveasÎncă nu există evaluări
- Funcionamiento Del Sistema de Abastecimiento Urbano Del Estado LaraDocument3 paginiFuncionamiento Del Sistema de Abastecimiento Urbano Del Estado LaraStephany DiasÎncă nu există evaluări
- Silabo Sistema de Soporte A DecisionesDocument4 paginiSilabo Sistema de Soporte A DecisionesJavier Alberto Manrique QuiñonezÎncă nu există evaluări
- Datos de CaliddaDocument54 paginiDatos de CaliddavirtualcyberÎncă nu există evaluări
- Concursos Pmex Tri 05-03-2024Document1 paginăConcursos Pmex Tri 05-03-2024yazminconygriegaÎncă nu există evaluări
- Business Plan McKinseyDocument33 paginiBusiness Plan McKinseyChristian Gonzalez Carrasco100% (1)
- Tesis El PeñonDocument49 paginiTesis El PeñonJuanSebastianBenavidesÎncă nu există evaluări
- NT935 Ed16 R1.7 EsDocument30 paginiNT935 Ed16 R1.7 EsAbraham TorresÎncă nu există evaluări
- 2wire para ShareazaDocument5 pagini2wire para Shareazasobera44Încă nu există evaluări
- Ejercicios de Las Leyes de FaradayDocument5 paginiEjercicios de Las Leyes de FaradayIrene HinostrozaÎncă nu există evaluări
- MSDS N2Document6 paginiMSDS N2JohanDuitamaÎncă nu există evaluări
- Manual de Operacion y MantenimientoDocument2 paginiManual de Operacion y MantenimientoYIMY YANQUEÎncă nu există evaluări
- PFC Anexo 2Document210 paginiPFC Anexo 2jefferson77valienteÎncă nu există evaluări