S-ar putea să vă placă și
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- The Literary Vs The Literal - The Narration of Magical Practices, Texts, and Their Practitioners in Setne I and II Compared With The So-Called Demotic and Greek Magical PapyriDocument30 paginiThe Literary Vs The Literal - The Narration of Magical Practices, Texts, and Their Practitioners in Setne I and II Compared With The So-Called Demotic and Greek Magical Papyritahuti696Încă nu există evaluări
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Transduction of The Geomagnetic Field As Evidenced From Alpha-Band Activity in The Human BrainDocument23 paginiTransduction of The Geomagnetic Field As Evidenced From Alpha-Band Activity in The Human Braintahuti696Încă nu există evaluări
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- Rapid Expert Consultation On The Effectiveness of Fabric Masks For The COVID-19 Pandemic (April 8, 2020) PDFDocument9 paginiRapid Expert Consultation On The Effectiveness of Fabric Masks For The COVID-19 Pandemic (April 8, 2020) PDFtahuti696Încă nu există evaluări
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- Pi Is 0092867420310084Document46 paginiPi Is 0092867420310084Analia E. De LucaÎncă nu există evaluări
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- Heather Zwickey, PHD - Important Clarifications Regarding Covid-19 and Natural Medicine - Dispelling Myths and MisconceptionsDocument9 paginiHeather Zwickey, PHD - Important Clarifications Regarding Covid-19 and Natural Medicine - Dispelling Myths and Misconceptionstahuti696Încă nu există evaluări
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Rita Lucarelli - The Magician As A Literary Figure in Ancient Egyptian TextsDocument9 paginiRita Lucarelli - The Magician As A Literary Figure in Ancient Egyptian Textstahuti696Încă nu există evaluări
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Women and Pain - White Paper 051518 - FNL - WebDocument17 paginiWomen and Pain - White Paper 051518 - FNL - Webtahuti696Încă nu există evaluări
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Rapid Expert Consultation On The Effectiveness of Fabric Masks For The COVID-19 Pandemic (April 8, 2020) PDFDocument9 paginiRapid Expert Consultation On The Effectiveness of Fabric Masks For The COVID-19 Pandemic (April 8, 2020) PDFtahuti696Încă nu există evaluări
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- How To Sanitize N95 Masks For Reuse - NIH StudyDocument2 paginiHow To Sanitize N95 Masks For Reuse - NIH Studytahuti696Încă nu există evaluări
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Radionics ManualDocument24 paginiRadionics Manualnovak1805201295% (42)
- Terry Riley - Obsessed and Passionate About All Music - NewMusicBox PDFDocument34 paginiTerry Riley - Obsessed and Passionate About All Music - NewMusicBox PDFtahuti696Încă nu există evaluări
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- Vitamin D Supplementation Could Possibly Improve Clinical Outcomes of Patients Infected With Coronavirus-2019 (Covid-2019) (Letter)Document6 paginiVitamin D Supplementation Could Possibly Improve Clinical Outcomes of Patients Infected With Coronavirus-2019 (Covid-2019) (Letter)tahuti696Încă nu există evaluări
- Terry Riley - Obsessed and Passionate About All Music - NewMusicBox PDFDocument34 paginiTerry Riley - Obsessed and Passionate About All Music - NewMusicBox PDFtahuti696Încă nu există evaluări
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- A Prayer To Sekhmet (Under Regulus), Translated by E.A. ST GeorgeDocument1 paginăA Prayer To Sekhmet (Under Regulus), Translated by E.A. ST Georgetahuti696Încă nu există evaluări
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- Hahnemann's First Provings - Peter MorrellDocument21 paginiHahnemann's First Provings - Peter Morrelltahuti696Încă nu există evaluări
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- MattiodaCompleteManual PDFDocument252 paginiMattiodaCompleteManual PDFdanobikwelu_scribdÎncă nu există evaluări
- Towards A Theory of Tantra-EcologyDocument8 paginiTowards A Theory of Tantra-Ecologytahuti696Încă nu există evaluări
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Women, Health, and Healing in Early Modern EuropeDocument18 paginiWomen, Health, and Healing in Early Modern Europetahuti696Încă nu există evaluări
- Wooster Beach and The Early Eclectics (Berman)Document10 paginiWooster Beach and The Early Eclectics (Berman)tahuti696Încă nu există evaluări
- Ozone in Medicine - The Low-Dose Ozone Concept-Guidelines and Treatment StrategiesDocument18 paginiOzone in Medicine - The Low-Dose Ozone Concept-Guidelines and Treatment Strategiestahuti696100% (1)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Yantra and Cakra in Tantric MeditationDocument22 paginiYantra and Cakra in Tantric Meditationtahuti696100% (1)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Afterlife of A Dream and The Ritual System of The Epidaurian AsklepieionDocument19 paginiThe Afterlife of A Dream and The Ritual System of The Epidaurian Asklepieiontahuti696Încă nu există evaluări
- Conceptual Blending Theory, Reverse Amnesia', and The Study of TantraDocument17 paginiConceptual Blending Theory, Reverse Amnesia', and The Study of Tantratahuti696Încă nu există evaluări
- Mormon Contributions To ChiropracticDocument3 paginiMormon Contributions To Chiropractictahuti696Încă nu există evaluări
- Ecopsychology and The Psychedelic Experience (2013)Document149 paginiEcopsychology and The Psychedelic Experience (2013)tahuti696100% (1)
- Religious Experience and Ecological Participation - Animism, Nature Connectedness and FairiesDocument6 paginiReligious Experience and Ecological Participation - Animism, Nature Connectedness and Fairiestahuti696Încă nu există evaluări
- Science and Magic in Ge Hong's "Baopu-Zi Nei Pian" - Evgueni A. TortchinovDocument7 paginiScience and Magic in Ge Hong's "Baopu-Zi Nei Pian" - Evgueni A. Tortchinovtahuti696Încă nu există evaluări
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Black Asclepius, White ImhotepDocument7 paginiBlack Asclepius, White Imhoteptahuti696Încă nu există evaluări
- Using EmergenceDocument9 paginiUsing EmergenceNick WildingÎncă nu există evaluări
- Imhotep and Medicine - A ReevaluationDocument3 paginiImhotep and Medicine - A Reevaluationtahuti696Încă nu există evaluări
- 1974 - Roncaglia - The Reduction of Complex LabourDocument12 pagini1974 - Roncaglia - The Reduction of Complex LabourRichardÎncă nu există evaluări
- The Neuroscience of Helmholtz and The Theories of Johannes Muèller Part 2: Sensation and PerceptionDocument22 paginiThe Neuroscience of Helmholtz and The Theories of Johannes Muèller Part 2: Sensation and PerceptionCrystal JenningsÎncă nu există evaluări
- Kimura K.K. (KKK) : Can This Customer Be Saved? - Group D13Document6 paginiKimura K.K. (KKK) : Can This Customer Be Saved? - Group D13Mayuresh GaikarÎncă nu există evaluări
- 2022 Summer Question Paper (Msbte Study Resources)Document4 pagini2022 Summer Question Paper (Msbte Study Resources)Ganesh GopalÎncă nu există evaluări
- Grimm (2015) WisdomDocument17 paginiGrimm (2015) WisdomBruce WayneÎncă nu există evaluări
- Review Rachna WasteDocument9 paginiReview Rachna WasteSanjeet DuhanÎncă nu există evaluări
- Routine (27th April)Document1 paginăRoutine (27th April)SoumitÎncă nu există evaluări
- Rules and Fallacies For Categorical SyllogismsDocument5 paginiRules and Fallacies For Categorical SyllogismsFatima Ismael PortacioÎncă nu există evaluări
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- ARCASIA Students Design Competition TORDocument4 paginiARCASIA Students Design Competition TORDeena McgeeÎncă nu există evaluări
- U2 LO An Invitation To A Job Interview Reading - Pre-Intermediate A2 British CounciDocument6 paginiU2 LO An Invitation To A Job Interview Reading - Pre-Intermediate A2 British CounciELVIN MANUEL CONDOR CERVANTESÎncă nu există evaluări
- Agenda - Meeting SLC (LT) - 27.06.2014 PDFDocument27 paginiAgenda - Meeting SLC (LT) - 27.06.2014 PDFharshal1223Încă nu există evaluări
- 3.15.E.V25 Pneumatic Control Valves DN125-150-EnDocument3 pagini3.15.E.V25 Pneumatic Control Valves DN125-150-EnlesonspkÎncă nu există evaluări
- Non-Emulsifying Agent W54Document12 paginiNon-Emulsifying Agent W54Pranav DubeyÎncă nu există evaluări
- Backward Forward PropogationDocument19 paginiBackward Forward PropogationConrad WaluddeÎncă nu există evaluări
- Burn Tests On FibresDocument2 paginiBurn Tests On Fibresapi-32133818100% (1)
- Creative LibrarianDocument13 paginiCreative LibrarianulorÎncă nu există evaluări
- Retirement 01Document2 paginiRetirement 01Nonema Casera JuarezÎncă nu există evaluări
- 37270a QUERCUS GBDocument6 pagini37270a QUERCUS GBMocanu Romeo-CristianÎncă nu există evaluări
- Lifecycle of A Butterfly Unit Lesson PlanDocument11 paginiLifecycle of A Butterfly Unit Lesson Planapi-645067057Încă nu există evaluări
- Ch.1 Essential Concepts: 1.1 What and How? What Is Heat Transfer?Document151 paginiCh.1 Essential Concepts: 1.1 What and How? What Is Heat Transfer?samuel KwonÎncă nu există evaluări
- TIB Bwpluginrestjson 2.1.0 ReadmeDocument2 paginiTIB Bwpluginrestjson 2.1.0 ReadmemarcmariehenriÎncă nu există evaluări
- 13 SK Kader Pendamping PGSDocument61 pagini13 SK Kader Pendamping PGSrachman ramadhanaÎncă nu există evaluări
- 2SA1016Document4 pagini2SA1016catalina maryÎncă nu există evaluări
- 22-28 August 2009Document16 pagini22-28 August 2009pratidinÎncă nu există evaluări
- Workplace Risk Assessment PDFDocument14 paginiWorkplace Risk Assessment PDFSyarul NizamzÎncă nu există evaluări
- Ge 6 Art Appreciationmodule 1Document9 paginiGe 6 Art Appreciationmodule 1Nicky Balberona AyrosoÎncă nu există evaluări
- Pre Intermediate Talking ShopDocument4 paginiPre Intermediate Talking ShopSindy LiÎncă nu există evaluări
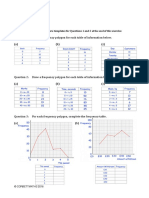
- Frequency Polygons pdf3Document7 paginiFrequency Polygons pdf3Nevine El shendidyÎncă nu există evaluări
- Thesis StoryboardDocument5 paginiThesis StoryboardJill Brown100% (2)
- Feasibility and Optimization of Dissimilar Laser Welding ComponentsDocument366 paginiFeasibility and Optimization of Dissimilar Laser Welding Componentskaliappan45490Încă nu există evaluări
- When the Body Says No by Gabor Maté: Key Takeaways, Summary & AnalysisDe la EverandWhen the Body Says No by Gabor Maté: Key Takeaways, Summary & AnalysisEvaluare: 3.5 din 5 stele3.5/5 (2)
- The Molecule of More: How a Single Chemical in Your Brain Drives Love, Sex, and Creativity--and Will Determine the Fate of the Human RaceDe la EverandThe Molecule of More: How a Single Chemical in Your Brain Drives Love, Sex, and Creativity--and Will Determine the Fate of the Human RaceEvaluare: 4.5 din 5 stele4.5/5 (516)
- Alex & Me: How a Scientist and a Parrot Discovered a Hidden World of Animal Intelligence—and Formed a Deep Bond in the ProcessDe la EverandAlex & Me: How a Scientist and a Parrot Discovered a Hidden World of Animal Intelligence—and Formed a Deep Bond in the ProcessÎncă nu există evaluări
- Tales from Both Sides of the Brain: A Life in NeuroscienceDe la EverandTales from Both Sides of the Brain: A Life in NeuroscienceEvaluare: 3 din 5 stele3/5 (18)
- Dark Matter and the Dinosaurs: The Astounding Interconnectedness of the UniverseDe la EverandDark Matter and the Dinosaurs: The Astounding Interconnectedness of the UniverseEvaluare: 3.5 din 5 stele3.5/5 (69)
- Gut: the new and revised Sunday Times bestsellerDe la EverandGut: the new and revised Sunday Times bestsellerEvaluare: 4 din 5 stele4/5 (392)
- Why We Die: The New Science of Aging and the Quest for ImmortalityDe la EverandWhy We Die: The New Science of Aging and the Quest for ImmortalityEvaluare: 4 din 5 stele4/5 (3)
- A Brief History of Intelligence: Evolution, AI, and the Five Breakthroughs That Made Our BrainsDe la EverandA Brief History of Intelligence: Evolution, AI, and the Five Breakthroughs That Made Our BrainsEvaluare: 4.5 din 5 stele4.5/5 (6)
- Gut: The Inside Story of Our Body's Most Underrated Organ (Revised Edition)De la EverandGut: The Inside Story of Our Body's Most Underrated Organ (Revised Edition)Evaluare: 4 din 5 stele4/5 (378)