S-ar putea să vă placă și
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5795)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Tcps 2 Final WebDocument218 paginiTcps 2 Final WebBornaGhannadiÎncă nu există evaluări
- 1 SMDocument9 pagini1 SMSelly ManaluÎncă nu există evaluări
- Lab 18 - Images of Concave and Convex Mirrors 1Document4 paginiLab 18 - Images of Concave and Convex Mirrors 1api-458764744Încă nu există evaluări
- Brandi Jones-5e-Lesson-Plan 2Document3 paginiBrandi Jones-5e-Lesson-Plan 2api-491136095Încă nu există evaluări
- IRJES 2017 Vol. 1 Special Issue 2 English Full Paper 038Document6 paginiIRJES 2017 Vol. 1 Special Issue 2 English Full Paper 038liew wei keongÎncă nu există evaluări
- PlagarisimDocument2 paginiPlagarisimabdullah0336.juttÎncă nu există evaluări
- ESM Module1 GE3 TCWDocument12 paginiESM Module1 GE3 TCWDeserie Aguilar DugangÎncă nu există evaluări
- Normality in The Residual - Hossain Academy NoteDocument2 paginiNormality in The Residual - Hossain Academy NoteAbdullah KhatibÎncă nu există evaluări
- Solarbotics Wheel Watcher Encoder ManualDocument10 paginiSolarbotics Wheel Watcher Encoder ManualYash SharmaÎncă nu există evaluări
- Leadership Competencies Paper 2Document5 paginiLeadership Competencies Paper 2api-297379255Încă nu există evaluări
- Collaborative Planning Template W CaptionDocument5 paginiCollaborative Planning Template W Captionapi-297728751Încă nu există evaluări
- Stepping Stones Grade 4 ScopeDocument2 paginiStepping Stones Grade 4 ScopeGretchen BensonÎncă nu există evaluări
- The Structure of Deception: Validation of The Lying Profile QuestionnaireDocument16 paginiThe Structure of Deception: Validation of The Lying Profile QuestionnaireNancy DrewÎncă nu există evaluări
- Sample Test Paper 2012 NucleusDocument14 paginiSample Test Paper 2012 NucleusVikramÎncă nu există evaluări
- Manage Your Nude PhotosDocument14 paginiManage Your Nude PhotosRick80% (5)
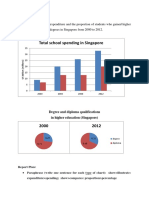
- Total School Spending in Singapore: Task 1 020219Document6 paginiTotal School Spending in Singapore: Task 1 020219viper_4554Încă nu există evaluări
- 1300 Rev01Document15 pagini1300 Rev01Manuel AltamiranoÎncă nu există evaluări
- KRAWIEC, Representations of Monastic Clothing in Late AntiquityDocument27 paginiKRAWIEC, Representations of Monastic Clothing in Late AntiquityDejan MitreaÎncă nu există evaluări
- Prospectus For Admission Into Postgraduate Programs at BUET April-2013Document6 paginiProspectus For Admission Into Postgraduate Programs at BUET April-2013missilemissionÎncă nu există evaluări
- Fidelizer Pro User GuideDocument12 paginiFidelizer Pro User GuidempptritanÎncă nu există evaluări
- EC861Document10 paginiEC861damaiÎncă nu există evaluări
- Biology FileDocument10 paginiBiology FileMichael KorsÎncă nu există evaluări
- SWAY GuideDocument16 paginiSWAY Guide63456 touristaÎncă nu există evaluări
- Журнал JournalistDocument36 paginiЖурнал JournalistSofia SorochinskaiaÎncă nu există evaluări
- Purposive Comm. Group 6 PPT Concise Vers.Document77 paginiPurposive Comm. Group 6 PPT Concise Vers.rovicrosales1Încă nu există evaluări
- 1981 Albus - Brains, Behavior, and RoboticsDocument362 pagini1981 Albus - Brains, Behavior, and RoboticsmarkmcwilliamsÎncă nu există evaluări
- Chris Barnes UEFA Presentation Nov 2015Document47 paginiChris Barnes UEFA Presentation Nov 2015muller.patrik1Încă nu există evaluări
- Marine BiomesDocument27 paginiMarine BiomesJe Ssica100% (1)
- LearnEnglish Reading B1 A Conference ProgrammeDocument4 paginiLearnEnglish Reading B1 A Conference ProgrammeAylen DaianaÎncă nu există evaluări
- HCI Accross Border PaperDocument5 paginiHCI Accross Border PaperWaleed RiazÎncă nu există evaluări