S-ar putea să vă placă și
- Virata 007Document27 paginiVirata 007Ginu Rodavia Dela TorreÎncă nu există evaluări
- Carbon Monoxide (CO) Concentration Monitoring System: Krizzia May L. GuimpolDocument38 paginiCarbon Monoxide (CO) Concentration Monitoring System: Krizzia May L. GuimpolGinu Rodavia Dela TorreÎncă nu există evaluări
- ThesisDocument31 paginiThesisGinu Rodavia Dela TorreÎncă nu există evaluări
- Design of Active Filter For 5Khz, 10Khz and 20KhzDocument19 paginiDesign of Active Filter For 5Khz, 10Khz and 20KhzGinu Rodavia Dela TorreÎncă nu există evaluări
- An Introduction To Bluetooth TechnologyDocument43 paginiAn Introduction To Bluetooth TechnologyGinu Rodavia Dela TorreÎncă nu există evaluări
- Rikka CommsDocument7 paginiRikka CommsGinu Rodavia Dela TorreÎncă nu există evaluări
- Motherboard DetectorDocument28 paginiMotherboard DetectorGinu Rodavia Dela TorreÎncă nu există evaluări
- Estallo Thesis Final DefenseDocument23 paginiEstallo Thesis Final DefenseGinu Rodavia Dela TorreÎncă nu există evaluări
- Pothole FillerDocument37 paginiPothole FillerGinu Rodavia Dela TorreÎncă nu există evaluări
- Development of Pothole Detection and Filler Using Arduino Mega 2560Document48 paginiDevelopment of Pothole Detection and Filler Using Arduino Mega 2560Ginu Rodavia Dela TorreÎncă nu există evaluări
- Bluetooth DelatorreDocument11 paginiBluetooth DelatorreGinu Rodavia Dela TorreÎncă nu există evaluări
- Narrative Report On Educational TourDocument7 paginiNarrative Report On Educational TourGinu Rodavia Dela TorreÎncă nu există evaluări
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5795)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Circuito PCB Control Pedal V3 TerminadoDocument1 paginăCircuito PCB Control Pedal V3 TerminadoMarcelo PereiraÎncă nu există evaluări
- Features: 833H - 1A - F - CDocument3 paginiFeatures: 833H - 1A - F - CDaniboy1994Încă nu există evaluări
- An Analysis of The Ejector-Ram-Rocket EngineDocument9 paginiAn Analysis of The Ejector-Ram-Rocket Enginefundamental_aeroÎncă nu există evaluări
- Forklift Operator Evaluation Form: Operator Behaviors Rating Comments Pre-Use InspectionDocument2 paginiForklift Operator Evaluation Form: Operator Behaviors Rating Comments Pre-Use InspectionXionÎncă nu există evaluări
- Status Profile Creation and Assignment To An Order Type in SAP PPDocument7 paginiStatus Profile Creation and Assignment To An Order Type in SAP PPHemant UNICHEMLLPÎncă nu există evaluări
- CE 411 Lecture 03 - Moment AreaDocument27 paginiCE 411 Lecture 03 - Moment AreaNophiÎncă nu există evaluări
- Simple and Compound Gear TrainDocument2 paginiSimple and Compound Gear TrainHendri Yoga SaputraÎncă nu există evaluări
- 165T-5 Parts ListDocument26 pagini165T-5 Parts ListJorge Luis Galezo MuñozÎncă nu există evaluări
- p2714 Opel 6t45Document5 paginip2714 Opel 6t45Валентин ДÎncă nu există evaluări
- DFM54 EngDocument2 paginiDFM54 EngAnonymous KWO434Încă nu există evaluări
- 1996 Club Car DS Golf Cart Owner's ManualDocument48 pagini1996 Club Car DS Golf Cart Owner's Manualdriver33b60% (5)
- Electrical SubstationsDocument16 paginiElectrical SubstationsEngr Syed Numan ShahÎncă nu există evaluări
- Electrical Panel Data MSC PG: NO Panel Desc Panel CodeDocument6 paginiElectrical Panel Data MSC PG: NO Panel Desc Panel CodeAjeng AyuÎncă nu există evaluări
- BEC198 (Finals)Document180 paginiBEC198 (Finals)Lorenz BerroyaÎncă nu există evaluări
- SA Flight Instructors Training ProceduresDocument371 paginiSA Flight Instructors Training ProceduresGuilioÎncă nu există evaluări
- CS 303e, Assignment #10: Practice Reading and Fixing Code Due: Sunday, April 14, 2019 Points: 20Document2 paginiCS 303e, Assignment #10: Practice Reading and Fixing Code Due: Sunday, April 14, 2019 Points: 20Anonymous pZ2FXUycÎncă nu există evaluări
- Strength of Materials Basics and Equations - Mechanics of Materials - Engineers EdgeDocument6 paginiStrength of Materials Basics and Equations - Mechanics of Materials - Engineers EdgeansarÎncă nu există evaluări
- Op Amp TesterDocument2 paginiOp Amp TesterPhay KhamÎncă nu există evaluări
- Mainframe Vol-II Version 1.2Document246 paginiMainframe Vol-II Version 1.2Nikunj Agarwal100% (1)
- F4 Search Help To Select More Than One Column ValueDocument4 paginiF4 Search Help To Select More Than One Column ValueRicky DasÎncă nu există evaluări
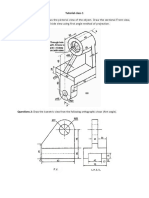
- Tutorial Class 1 Questions 1Document2 paginiTutorial Class 1 Questions 1Bố Quỳnh ChiÎncă nu există evaluări
- Astm F 30 - 96 R02 - RJMWDocument5 paginiAstm F 30 - 96 R02 - RJMWphaindikaÎncă nu există evaluări
- Internet Intranet ExtranetDocument28 paginiInternet Intranet ExtranetAmeya Patil100% (1)
- 031 - Btech - 08 Sem PDFDocument163 pagini031 - Btech - 08 Sem PDFtushant_juneja3470Încă nu există evaluări
- Digital Indicating Controller: Bcs2, Bcr2, Bcd2Document10 paginiDigital Indicating Controller: Bcs2, Bcr2, Bcd2Bui TAN HIEPÎncă nu există evaluări
- Host Interface Manual - U411 PDFDocument52 paginiHost Interface Manual - U411 PDFValentin Ghencea50% (2)
- APP157 CoP For Site Supervision 2009 202109Document92 paginiAPP157 CoP For Site Supervision 2009 202109Alex LeungÎncă nu există evaluări
- REE Copy PDFDocument9 paginiREE Copy PDFJake ZozobradoÎncă nu există evaluări
- Raft TheoryDocument37 paginiRaft Theorymuktha mukuÎncă nu există evaluări
- Stainless Steel: Presented By, Dr. Pragati Jain 1 YearDocument68 paginiStainless Steel: Presented By, Dr. Pragati Jain 1 YearSneha JoshiÎncă nu există evaluări