Documente Academic
Documente Profesional
Documente Cultură
Ecnm Us Ii PDF
Încărcat de
Paul IonutTitlu original
Drepturi de autor
Formate disponibile
Partajați acest document
Partajați sau inserați document
Vi se pare util acest document?
Este necorespunzător acest conținut?
Raportați acest documentDrepturi de autor:
Formate disponibile
Ecnm Us Ii PDF
Încărcat de
Paul IonutDrepturi de autor:
Formate disponibile
Unitatea de studiu 2.
REGRESIA LINIARĂ SIMPLĂ
Cuprins unitate de studiu
2.1 Tipuri regresie
2.2 Interpretarea geometrică şi statistică a regresiei
2.3 Modelul econometric de regresie liniară simplă
Obiective
- prezentarea tipurilor de regresie în econometrie
- analiza statistică şi geometrică a regresiei
- prezentarea modelului de regresie liniară simplă: componente, estimarea şi testarea
parametrilor, testarea modelului
Competenţe
- însuşirea conceptului de regresie
- formarea abilităţilor teoretice şi practice de construire a unui model de regresie liniară
simplă
- deprinderea de a construi un model liniar simplu cu date de la nivelul economiei României
- însuşirea cunoştinţelor şi deprinderilor de utilizare a unui soft statistic pentru modelare
Termen mediu: 4 h
Bibliografie selectivă
1. Bourbonnais, R., Économétrie, Dunod, Paris, 2000
2. Jemna, D.V., Econometrie, Editura Sedcom Libris, Iaşi, 2009
3. Gujarati, D.N., Basic econometrics, McGraw-Hill, New York, 1995
4. Ionescu, H.M., Introducere în statistica matematică, Editura Didactică şi
Pedagogică, Bucureşti, 1962
5. Maddala, G.S., Introduction to Econometrics, John Wiley & Sons, 2001
14 Regresia liniară simplă
2.1. Tipuri de regresie
Legăturile dintre variabilele statistice pot fi clasificate în mai multe categorii, după
următoarele criterii: momentul la care se referă, tipul de dependenţă dintre variabile, numărul
variabilelor, tipul (forma) legăturii etc.
Modele de moment şi dinamice
Modelul de moment, numit şi model static, este modelul econometric în care legătura dintre
variabile se referă la acelaşi moment sau la aceeaşi perioadă de timp. Pentru construirea
acestor modele se utilizează date din anchete de moment, cum ar fi sondajele statistice,
recensămintele sau alte cercetări de moment.
Modelul dinamic este modelul econometric construit pe baza seriilor de timp. Factorul timp
apare în model prin precizarea momentelor sau a intervalelor de timp la care se referă datele.
Există şi modele în care timpul apare ca o variabilă independentă, exprimând trendul seriei de
timp.
Modele deterministe şi stochastice
Dependenţa dintre variabile poate fi:
- deterministă sau funcţională (matematică). Asemenea modele sunt mai rar întâlnite, pentru
că presupun că între variabile există o legătură de tipul yi f ( xi ) , adică variabila dependentă
este explicată în totalitate de variabilele independente din model. Modelele funcţionale sunt
întâlnite în domeniul ştiinţelor naturii, pe când în ştiinţele sociale se utilizează mai frecvent
modelele probabiliste.
- stochastică sau probabilistă. În aceste modele, pentru o valoare a variabilei independente,
există mai multe valori ale variabilei dependente, determinate probabilistic. În modelele
stochastice, variabila dependentă este influenţată şi de o serie de factori care nu apar explicit
în model, dar sunt sintetizaţi printr-o variabilă aleatoare numită variabilă reziduală. Modelul
stochastic este de forma:
yi f ( xi ) i .
Modele simple şi multiple
Dacă în modelul de regresie apare o singură variabilă independentă, regresia se numeşte
simplă. Un exemplu de model simplu este modelul care exprimă dependenţa consumului de
preţ: C f ( P ) . Aceste modele sunt întâlnite mai rar în economie, deoarece un fenomen
depinde, de regulă, de mai mulţi factori de influenţă. Dacă se alege totuşi un factor
determinant, ceilalţi factori pot fi consideraţi ca fiind avuţi în vedere prin variabila reziduală.
Dacă în model apar cel puţin două variabile independente, regresia se numeşte multiplă.
Modelul are forma: Y f ( X 1 , X 2 ) , iar variabila dependentă este explicată prin influenţa
cumulată a factorilor care apar în model.
Econometrie – Dănuţ JEMNA
Regresia liniară simplă 15
Modele liniare şi neliniare
Modelul liniar este modelul în care relaţia dintre variabile este una de proporţionalitate,
legătura dintre variabile fiind descrisă de o funcţie liniară. De exemplu, modelele
Y 0 1 X şi Y 0 1 X 1 2 X 2 sunt modele liniare.
Modelul neliniar este modelul în care legătura dintre variabile este explicată de o funcţie
neliniară. Exemple:
Y 0 1 ln X , ln Y 0 1 X , Y 0 X 11 etc.
2.2. Interpretarea geometrică şi statistică a regresiei
Interpretarea geometrică
Locul geometric al mediilor condiţionate ale variabilei dependente, pentru valori fixate ale
variabilei independente, reprezintă o linie poligonală sau o curbă (linia de regresie, pentru caz
discret, sau curba de regresie, pentru caz continuu).
Analiza dependenţei legăturii dintre cele două variabile se poate realiza pe baza unei judecăţi
statistice elementare: tipul dependenţei dintre cele două variabile sau modul în care variabila
independentă o influenţează pe cea dependentă este sugerat de forma curbei sau liniei de
regresie statistică, construită pe baza mediilor condiţionate, calculate cu ajutorul datelor
disponibile.
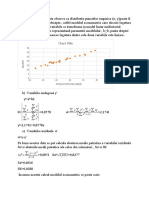
De exemplu, dacă linia de regresie statistică se apropie de o dreaptă, datele sugerează un tip
de dependenţă liniară între variabilele studiate (figura 1).
6.00
5.00
Value profit
4.00
3.00
2.00
60.00 70.00 80.00 90.00 100.00
ch_publicit
Figura 1. Linia de regresie statistică a lui Y în raport cu X
b. Interpretarea statistică
Conform teoriei probabilităţilor şi statisticii matematice, regresia este o medie condiţionată
definită pe o distribuţie bi- sau multidimensională. În cazul unei legături dintre două variabile,
regresia este definită prin aplicaţia:
Econometrie – Dănuţ JEMNA
16 Regresia liniară simplă
M ( Y / X xi ) f ( xi ) sau M ( Y / X ) f ( x )
Pentru cazul liniar, regresia sau media condiţionată este o funcţie liniară:
M ( Y / X ) 0 1 X , unde 0, 1 sunt parametrii modelului, iar X este variabila
independentă, considerată nestochastică.
În consecinţă, regresia liniară este:
yi M ( Y / X xi ) 0 1 xi .
2.3. Modelul econometric de regresie liniară simplă
1. Prezentarea modelului
În cazul regresiei liniare simple, modelul are următoarea expresie:
yi 0 1 xi i sau
Y 0 1 X ,
iar media condiţionată este:
M ( Y / X xi ) 0 1 xi .
Componentele modelului
Modelul econometric liniar simplu include două componente: una deterministă şi una
stochastică.
Componenta deterministă este reprezentată de media condiţionată:
M ( Y / X xi ) 0 1 xi .
În această componentă apare variabila independentă, care este o variabilă observabilă din
punct de vedere statistic, şi parametrii modelului, care sunt constante reale.
Componenta aleatoare este reprezentată de variabila aleatoare numită eroare sau reziduu,
notată cu . Natura acestei variabile este legată de următoarele probleme care însoţesc
procesul de modelare: natura fenomenului studiat, specificarea modelului, erorile de
măsurare1.
În modelul econometric, i sunt variabile aleatoare construite pentru fiecare repartiţie
condiţionată de forma Yi X xi .
2. Parametrii modelului
În modelul de regresie liniară simplă, yi 0 1 xi i , există doi parametri: 0 şi 1 .
Aceştia se mai numesc şi coeficienţi de regresie.
1 G.S. Maddala, Introduction to econometrics, John Wiley and Sons, 2001, p. 64
Econometrie – Dănuţ JEMNA
Regresia liniară simplă 17
- 0 este constanta sau termenul liber (intercept) şi indică valoarea medie a variabilei
dependente Y atunci când variabila independentă X ia valoarea zero. Este ordonata la origine a
dreptei de regresie sau intersecţia dreptei cu axa OY. În unele modele, acest parametru poate
să lipsească, caz în care dreapta trece prin origine.
- 1 (slope) indică variaţia absolută medie a variabilei dependente la o variaţie absolută cu o
unitate a variabilei independente. Cu alte cuvinte, 1 arată răspunsul variabilei Y la o creştere
sau scădere cu o unitate a variabilei X.
dY Y
1 , unde Y 0 1 X .
dX X
Răspunsul variabilei dependente poate fi în acelaşi sens ( 1 0 ), ceea ce indică o legătură
directă sau pozitivă între variabile (de exemplu, dacă X creşte cu o unitate, Y creşte în medie
cu 1 ) sau poate fi în sens contrar ( 1 0 ), adică între variabile există o legătură inversă.
Dacă 1 0 , între cele două variabile nu există o legătură de tip liniar.
yx 0 1 x
0 1
0 X
Figura 2. Linia de regresie sau media condiţionată
Ipotezele clasice ale modelului de regresie
Modelarea econometrică implică anumite condiţii sau ipoteze asupra celor două componente
ale modelului, ipoteze care vor fi prezentate în continuare. Ipotezele acestui model se împart
în două categorii şi privesc cele două componente ale modelului: componenta deterministă şi
componenta aleatoare.
Ipoteze cu privire la variabilele independente
- variabila independentă X este observabilă (nestochastică);
- lipsa coliniarităţii variabilelor independente – între variabilele factoriale nu există o legătură
liniară (în cazul regresiei multiple);
- variabila independentă are o dispersie finită şi este posibil de determinat.
Econometrie – Dănuţ JEMNA
18 Regresia liniară simplă
Ipoteze cu privire la variabila aleatoare eroare
- eroarea medie este nulă: M ( i ) 0 .
Cu alte cuvinte, în medie, modelul este bine specificat, adică factorii neincluşi explicit în
model nu afectează sistematic valoarea medie a variabilei dependente. Altfel spus, această
ipoteză presupune că valoarea aşteptată, sperată, a erorii la nivelul repartiţiilor condiţionate de
tipul Yi X xi este egală cu zero (figura 3.3).
- ipoteza de homoscedasticitate: V ( i ) M ( i2 ) 2 .
Această ipoteză presupune că varianţa erorii este constantă la nivelul repartiţiilor condiţionate
de tipul Yi X xi . Repartiţiile variabilei reziduale pentru fiecare repartiţie condiţionată sunt
prezentate în figura 3.3.
- ipoteza de normalitate a erorilor: i ~ N( 0, 2 ) .
La nivelul fiecărei repartiţii condiţionate, variabila eroare urmează o lege de repartiţie
normală.
- ipoteza de necorelare a erorilor: cov( i , j ) 0 sau erorile nu se influenţează reciproc, sunt
independente.
- lipsa corelaţiei dintre variabila independentă şi variabila eroare, cov( i , xi ) 0 .
Dacă se admite ipoteza i ~ N( 0, 2 ) , atunci variabila dependentă este o variabilă aleatoare
normal distribuită de forma: Y ~ N( 0 1 X ; 2 ) .
Y
yx 0 1 x
0 x1 x2 xi X
Figura 3. Repartiţiile erorilor la nivelul repartiţiilor condiţionate
3. Estimarea parametrilor modelului
În practică, de obicei, nu se dispune de date decât de la nivelul unui eşantion de volum n. Pe
baza acestor date se realizează estimarea parametrilor modelului de regresie.
Econometrie – Dănuţ JEMNA
Regresia liniară simplă 19
Pentru modelul yi 0 1 xi i , la nivelul unui eşantion se obţine ecuaţia pe baza
estimatorilor:
yi ˆ 0 ˆ 1 xi ˆ i sau
yi ŷi ˆ i ,
unde ŷ ˆ ˆ x estimează media condiţionată M(Y/X).
i 0 1 i
Din relaţiile de mai sus, rezultă ˆ i yi ŷi sau ˆ i yi ˆ 0 ˆ 1 xi . Cu alte cuvinte, dacă se
dispune de un set de date statistice obţinute prin sondaj, se pot calcula erorile estimate ale
modelului de regresie ca diferenţe dintre valorile empirice şi cele estimate cu ajutorul
modelului pentru variabila dependentă.
Determinarea estimatorilor prin Metoda celor mai mici pătrate
Potrivit metodei celor mai mici pătrate, estimatorii parametrilor modelului de regresie verifică
condiţia:
ˆ i2 min sau ( yi ˆ 0 ˆ 1xi )2 min .
i i
Prin metoda celor mai mici pătrate, estimatorii parametrilor modelului de regresie liniară
simplă se obţin rezolvând problema de optim:
S yi ˆ 0 ˆ 1 xi )2 min .
i
Soluţia se obţine prin respectarea a două condiţii: de extrem şi de minim, pentru aplicaţia
S S( ˆ 0 , ˆ 1 ) .
Condiţia de extrem presupune ecuaţiile:
ˆ , ˆ )
S (
0 1
0 2 ( yi ˆ 0 ˆ 1 xi )( 1 ) 0
ˆ
0 i
ˆ ˆ sau
S ( 0 , 1 ) 0 2 ( yi ˆ 0 ˆ 1 xi )( xi ) 0
i
ˆ 1
Rezultă:
( yi ˆ 0 ˆ 1 xi ) 0
i
xi ( yi ˆ 0 ˆ 1 xi ) 0
i
sau
nˆ 0 ˆ 1 xi yi
i i
ˆ ˆ
0 xi 1 xi yi xi
2
i i i
Rezolvarea sistemului conduce la următoarele relaţii ale estimatorilor:
Econometrie – Dănuţ JEMNA
20 Regresia liniară simplă
n xi yi xi yi
ˆ 1 i i i
sau
n xi2 ( xi )2
i i
( yi ŷ )( xi x ) côv( X ,Y )
ˆ 1 i
.
( xi x ) 2
V( X )
i
ˆ 0 ŷ ˆ 1 x .
Proprietăţile estimatorilor ˆ 0 , ˆ 1
a. Proprietatea de nedeplasare
Proprietatea de nedeplasare a estimatorilor parametrilor modelului de regresie se
demonstrează în condiţiile respectării ipotezei că variabila X este nestochastică şi în baza
proprietăţii că variabilele aleatoare yi urmează aceeaşi lege de repartiţie, adică:
yi ~ N( 0 1 xi , 2 ) .
Se demonstrează că: M ( ˆ ) şi M ( ˆ ) , ceea ce indică faptul că estimatorii
0 0 1 1
obţinuţi prin metoda celor mai mici pătrate sunt nedeplasaţi.
b. Proprietatea de normalitate
Dacă admitem ipoteza că i ~ N( 0, 2 ) , estimatorii ˆ 0 , ˆ 1 , care sunt combinaţii liniare de
variabile normal distribuite, sunt normal repartizaţi. Parametrii acestor repartiţii sunt
prezentaţi mai jos.
M ( ˆ 0 ) 0 , M ( ˆ 1 ) 1 ,
2
V ( ˆ 1 ) ,
( xi x )2
i
ˆ 2 1 x2
V ( 0 ) 2
.
n ( xi x )
i
În concluzie, rezultă următoarele repartiţii ale estimatorilor:
ˆ
1 ~ N 1 ,
2
2
sau ˆ 1 ~ N 1 , 2ˆ1 ,
i ( x x )
i
ˆ 2 1
0 ~ N 0 ,
x2
2
sau ˆ 0 ~ N 0 , 2ˆ0 .
n ( xi x )
i
Econometrie – Dănuţ JEMNA
Regresia liniară simplă 21
c. Proprietatea de convergenţă
Estimatorii ˆ 0 , ˆ 1 sunt convergenţi, adică pentru un volum al eşantionului suficient de mare
şirurile estimatorilor converg în probabilitate către parametrii 0 , 1 . Au loc relaţiile:
ˆ 0 nN p
0 ,
ˆ 1 nN p
1 .
d. Proprietatea de eficienţă
Estimatorul ̂ 1 este eficient pentru parametrul 1 , adică, dintre toţi estimatorii posibili, ̂ 1
are varianţa cea mai mică.
Se poate arăta că un estimator nedeplasat al dispersiei erorilor este dat prin relaţia:
ˆ i2 ( yi ˆ 0 ˆ 1 xi )2
ˆ 2 i
i
, iar
n2 n2
ˆ i2
M ( ˆ 2 ) M i ,
2
n 2
Considerăm relaţia de descompunere a variaţiei totale a variabile dependente, în condiţiile
existenţei legături liniare cu variabila independentă:
( yi y )2 ( 0 1 xi y )2 ( yi 0 1 xi )2 sau
i i i
VT VE VR .
Vom nota prin ˆ i2 ( yi ˆ 0 ˆ 1 xi )2 V̂R , adică estimatorul variaţiei reziduale.
i i
Dezvoltând relaţia de mai sus, se poate scrie:
V̂R ( yi ŷ )2 ˆ 12 ( xi x )2 2ˆ 1 ( xi x )( yi ŷ ) , unde
i i i
V̂T ( yi ŷ ) este estimatorul variaţiei totale.
2
Rezultă:
V̂R V̂T ˆ 12 ( xi x )2 2ˆ 1 ( xi x )( yi ŷ ) , iar
i i
( yi ŷ )( xi x ) côv( X ,Y )
ˆ 1 i
, de unde rezultă:
( xi x ) 2
V( X )
i
V̂R V̂T ˆ 1 ( xi x )( yi ŷ ) , iar
i
Econometrie – Dănuţ JEMNA
22 Regresia liniară simplă
V̂E ˆ 1 ( xi x )( yi ŷ ) , care este estimatorul variaţiei explicate.
i
Obţinem rezultatul:
V̂T V̂E V̂R .
Estimarea punctuală şi prin interval de încredere a parametrilor modelului
a. Estimarea punctuală
În baza proprietăţilor de nedeplasare şi convergenţă, parametrii modelului de regresie se
estimează punctual considerând estimaţiile calculate la nivelul unui eşantion reprezentativ
extras din populaţia de referinţă, pe baza relaţiilor:
n xi yi xi yi
b1 i i i
şi
n xi2 ( xi )2
i i
b0 y b1 x .
x i y i
x , y
i i
n n
reprezintă mediile variabilelor X, Y calculate la nivelul eşantionului.
b. Estimarea prin interval de încredere a parametrilor 0 , 1
La baza procedeului de estimare prin interval de încredere stau legile normale de repartiţie a
estimatorilor ˆ 0 , ˆ 1 . Astfel, dacă se consideră estimatorii standardizaţi, obţinem statisticile:
ˆ 1 1 ˆ 0
~ N( 0, 1 ) , 0 ~ N ( 0 , 1 ) , respectiv
ˆ 1
ˆ 0
ˆ 1 1 ˆ 0
~ t( n 2 ) , 0 ~ t( n 2 ) ,
ˆ ˆ 1
ˆ ˆ 0
dacă se utilizează estimatorii abaterilor standard ale estimatorilor.
Conform proprietăţilor repartiţiei Student, pentru un nivel de încredere (1-) fixat, intervalul
de încredere pentru parametrul 1 se determină pe baza relaţiei:
ˆ
P 1 1
t / 2 1 .
ˆ ˆ
1
Rezultă:
P( ˆ 1 t / 2ˆ ˆ 1 ˆ 1 t / 2ˆ ˆ ) 1 , unde
1 1
ˆ 2
ˆ ˆ , iar
1
( xi x )2
i
Econometrie – Dănuţ JEMNA
Regresia liniară simplă 23
ˆ i2 ( yi ˆ 0 ˆ 1 xi )2 V̂R
ˆ 2 i
i
sau ˆ 2 .
n2 n2 n2
Cu alte cuvinte, pentru un nivel de încredere egal cu (1-), limitele intervalului de încredere
pentru parametrul 1 sunt:
ˆ t ˆ ˆ .
1 /2 1
Analog, pentru parametrul 0 , intervalul de încredere este:
ˆ t ˆ ˆ .
0 /2 0
Pe baza datelor de la nivelul unui eşantion, se calculează un interval de încredere cu ajutorul
estimaţiilor. Se obţin intervalele:
b1 t / 2 sˆ , respectiv b0 t / 2 sˆ .
1 0
Estimaţiile pentru abaterile standard ale estimatorilor sunt:
( yi b0 b1 xi )2s2
sˆ i
,
1
( n 2 ) ( xi x )2 ( xi x )2
i i
1 x2
sˆ s 2 ( ) , iar
0
n ( xi x )2
i
( yi b0 b1 xi )2
s i
este estimaţia parametrului .
(n2)
Dacă notăm cu ei yi b0 b1 xi estimaţiile erorilor, estimaţia parametrului devine:
ei2
s i
.
(n2)
Pentru componentele variaţiei, se obţin următoarele estimaţii:
TSS ( yi y )2 (Total Sum of Squares);
i
ESS ( b0 b1 xi y )2 (Explained Sum of Squares);
i
RSS ( yi b0 b1 xi )2 ei (Residual Sum of Squares);
2
i i
TSS = ESS + RSS.
Econometrie – Dănuţ JEMNA
24 Regresia liniară simplă
Exemplu
Considerăm datele cu privire la repartiţia unei populaţii de 50 firme după profitul realizat
(variabila dependentă Y, exprimată în sute milioane lei) şi cheltuielile cu publicitatea
(variabila independentă X, exprimată în milioane lei).
Parametrii modelului liniar de regresie sunt estimaţi punctual şi prin interval de încredere cu
ajutorul programului SPSS, după cum urmează:
Coefficientsa
Uns tandardized Standardized
Coefficients Coefficients 95% Confidence Interval for B
Model B Std. Error Beta Lower Bound Upper Bound
1 (Cons tant) -3.951 1.795 -7.561 -.342
cheltuieli cu publicitatea .100 .022 .551 .056 .143
a. Dependent Variable: profitul
Modelul estimat pentru cele două variabile este de forma:
y 3,95 0 ,1x .
Valoarea pozitivă a estimaţiei parametrului 1 indică o legătură directă între cheltuielile cu
publicitatea şi profitul firmei. Valorile estimaţiilor arată că în cazul lipsei cheltuielilor (X = 0)
firma pierde 3,95 sute milioane lei, iar la o creştere a cheltuielilor cu publicitatea de 1 milion
lei, profitul mediu al firmei creşte cu 0,1 sute milioane lei.
Intervalele de încredere pentru cei doi parametri au următoarea interpretare: cu un nivel de
încredere de 95%, valoarea parametrului 0 este acoperită de intervalul
(-7,56 ; -0,34), iar a parametrului 1 , de intervalul (0,056 ; 0,143).
4. Indicatori de corelaţie
a. Coeficientul de corelaţie
Coeficientul de corelaţie teoretic este un parametru definit prin relaţia:
cov( X ,Y )
sau
V ( X )V ( Y )
N xi yi xi yi
i i i
,
2 2
N xi ( xi ) N yi ( yi )
2 2
i i i i
unde: 1 1 .
Coeficientul de corelaţie măsoară intensitatea legăturii dintre cele două variabile.
Dacă valoarea parametrului se apropie de unu, între variabile există o legătură intensă sau
puternică. Legătura este slabă dacă coeficientul are o valoare aproape de zero. Se consideră
Econometrie – Dănuţ JEMNA
Regresia liniară simplă 25
semnificativă intensitatea legăturii dintre două variabile dacă 0 ,7 . Semnul coeficientului
indică sensul legăturii dintre variabile.
Observaţie
O altă relaţie pentru coeficientul de corelaţie se poate construi ţinând cont de relaţia
coeficientului de regresie 1 :
V( X )
1 .
V(Y )
Estimarea coeficientului de corelaţie
Pentru acest parametru, se poate construi un estimator pe baza relaţiilor de mai sus:
V( X )
ˆ ˆ 1 .
V̂ ( Y )
O estimaţie a coeficientului de corelaţie se obţine la nivelul unui eşantion, pe baza relaţiei:
s x2
r b1 .
s y2
Observaţie
Dacă se realizează o standardizare a variabilelor X, Y, atunci estimatorul coeficientului de
corelaţie pentru aceste variabile este identic cu cel al coeficientului de regresie 1 .
b. Raportul de determinaţie şi raportul de corelaţie
Raportul de determinaţie
Raportul de determinaţie este un parametru care se calculează pe baza valorilor reale (yi) şi a
valorilor teoretice ( yxi 0 1 xi ), valori calculate cu ajutorul modelului de regresie pentru
variabila dependentă.
Raportul de determinaţie măsoară cât din variaţia totală a variabilei dependente este explicat
de modelul de regresie:
( yx i
y )2
VE V
2 i
1 R , unde: 0 2 1 .
( yi y ) 2
VT VT
i
Exprimată în procente, valoarea raportului de determinaţie arată cât la sută din variaţia
variabilei dependente este determinată de variaţia variabilei independente.
Estimarea raportului de determinaţie
La nivelul unui selecţii de volum n, raportul de determinaţie este estimat pe baza relaţiei de
descompunere a estimatorului variaţiei totale:
Econometrie – Dănuţ JEMNA
26 Regresia liniară simplă
( yi ŷ )2 ( ŷi ŷ )2 ( yi ŷi )2 sau
i i i
V̂T V̂E V̂R
Observaţie
Deoarece variabila dependentă urmează o lege de repartiţie normală, de parametri
( 0 1 X , 2 ), pentru variabilele de mai sus se pot construi variabile cu legi de repartiţie
cunoscute:
V̂T ~ 2 ( n 1 ),
V̂E ~ 2 ( k 1 ),
V̂R ~ 2 ( n k ),
unde k este numărul de parametri incluşi în model. Pentru modelul liniar simplu, k=1.
Estimatorul raportului de determinaţie se defineşte ca raport între estimatorul variaţiei
explicate şi estimatorul variaţiei totale. În aceste condiţii, se poate scrie relaţia:
V̂ V̂
ˆ 2 E 1 R .
V̂T V̂T
O estimaţie a raportului de determinaţie se obţine prin relaţia:
2
( b0 b1 xi y )2 ESS RSS
R i 1 .
( yi y )2
TSS TSS
i
Observaţie
Pentru modelul liniar simplu, au loc relaţiile:
2 2 , r 2 R2 .
Raportul de corelaţie
Indicatorul 2 se numeşte raport de corelaţie şi măsoară intensitatea legăturii dintre
cele două variabile.
Raportul de corelaţie respectă condiţia: 0 1 . Estimaţia raportului de corelaţie se notează
cu R.
Exemplu
Pentru repartiţia unei populaţii de 50 firme după profitul realizat (variabila dependentă Y,
exprimată în sute milioane lei) şi cheltuielile cu publicitatea (variabila independentă X,
exprimată în milioane lei), estimaţiile pentru raportul de corelaţie şi pentru raportul de
determinaţie, calculate în SPSS, sunt:
Econometrie – Dănuţ JEMNA
Regresia liniară simplă 27
Model Summ ary
Model R R Square
1 .551a .304
a. Predictors: (Constant), chel tuieli cu publ icitatea
Valoarea raportului de determinaţie arată că 30,4% din variaţia variabilei dependente este
explicată de variaţia variabilei independente inclusă în model. Deoarece legătura dintre
variabile este una directă, estimaţia coeficientului de corelaţie este egală cu cea a
coeficientului de corelaţie, r=R=0,55, ceea ce indică o legătură de intensitate medie între cele
două variabile.
5. Testarea parametrilor şi a modelului de regresie
Testarea parametrilor modelului de regresie, precum şi a modelului de regresie se realizează
după schema clasică a unui procedeu de testare, ale cărei etape sunt precizate în continuare.
Etapele procesului testării unei ipoteze statistice sunt:
1. formularea ipotezelor (ipoteza nulă şi ipoteza alternativă);
2. alegerea pragului de semnificaţie sau a limitei erorii de speţa întâi (eroarea de a
respinge ipoteza nulă în condiţiile în care aceasta este adevărată);
3. alegerea statisticii test adecvate, care, în condiţiile acceptării ipotezei nule, are o lege
de repartiţie specificată;
4. determinarea unei valori teoretice a testului, în funcţie de legea de repartiţie şi de
pragul de semnificaţie ales;
5. calcularea unei valori a statisticii test pe baza datelor de la nivelul unui eşantion;
6. aplicarea regulii de decizie de acceptare sau de respingere a ipotezei nule (care în
esenţă constă în compararea valorii calculate a testului cu cea teoretică).
Regula de decizie cu privire la acceptarea sau respingerea ipotezei nule se poate lua în două
moduri: prin compararea valorii calculate a testului cu valoarea teoretică sau prin compararea
semnificaţiei testului cu pragul de semnificaţie.
Valoarea teoretică se citeşte pentru un prag de semnificaţie ales şi pentru o statistică cu legea
de repartiţie cunoscută. Pentru legea Student şi un prag de semnificaţie , valoarea din tabele
( t ,n ) are proprietatea: P( t t ,n ) .
Calculul exact al nivelului de semnificaţie, p-value sau Sig
Probabilitatea calculată, asociată valorii calculate a testului, a primit numele de semnificaţie a
testului şi este notată cu p-value sau Sig. Pentru o statistică Student, Sig t este probabilitatea
cu care se acceptă ipoteza nulă şi este dată de relaţia:
Sig t P( t tcalc ) .
Utilizând tabela Student, pentru o valoare calculată egală cu 3,49, un eşantion de volum egal
cu 40, Sig t este: P( t 3,49 ) 0 ,0015.
Econometrie – Dănuţ JEMNA
28 Regresia liniară simplă
Decizia pe baza semnificaţiei testului presupune următoarele două situaţii:
- dacă semnificaţia testului este mai mare sau egală decât pragul de semnificaţie, Sigt , se
acceptă ipoteza nulă, cu o probabilitate egală cu (1-);
- dacă Sigt , se respinge ipoteza nulă, cu probabilitatea (1-).
Testarea parametrilor modelului
Parametrii modelului de regresie liniară se testează cu ajutorul testului Student sau al testului
t. Vom exemplifica etapele testării pentru parametrul 1 .
Testul t
Considerăm un test bilateral, cu următoarele etape:
1. Formularea ipotezelor
H 0 : 1 0 (între cele două variabile nu există o legătură liniară);
H 1 : 1 0 (între variabile există o legătură de tip liniar).
2. Alegerea pragului de semnificaţie
De regulă, se ia valoarea 0,05 (în SPSS, aceasta este valoarea implicită, dar poate fi
modificată de utilizator).
3. Alegerea statisticii test
ˆ 1 1
Se alege statistica Student t .
ˆ ˆ 1
4. Determinarea valorii teoretice a testului
Dacă se acceptă ipoteza nulă, statistica test este:
ˆ
t 1 ~ t( n 2 ) , unde
ˆ ˆ 1
( yi ˆ 0 ˆ 1 xi )2
ˆ ˆ i
.
1
( n 2 ) ( xi x )2
i
Pentru pragul de semnificaţie stabilit şi cunoscând legea de repartiţie a statisticii test, pentru
n-2 grade de libertate, se citeşte din tabela Student valoarea teoretică t . Se alege /2
;n 2
2
deoarece testul este bilateral (figura 3.5), iar zonele de respingere sunt delimitate de valorile
t şi t .
;n 2 ;n 2
2 2
De exemplu, pentru un prag de semnificaţie de 0,05 şi un eşantion de volum n=150, din
tabele se citeşte valoarea t0 ,025;148 1,96 .
Econometrie – Dănuţ JEMNA
Regresia liniară simplă 29
t 0 t
;n 2 ;n 2
2 2
Figura 4. Valorile teoretice ale statisticii Student pentru un nivel de încredere de ( 1 )
5. Determinarea valorii calculate a testului
La nivelul unui eşantion se obţine o estimaţie a statisticii test:
b b1 b1
tcalc 1 .
sˆ i 0 1i
( y b b x )2
e
2
1 i
i i
( n 2 ) ( xi x )2 ( n 2 ) ( xi x )2
i i
6. Luarea deciziei
Regula de decizie, pe baza valorii calculate a testului, este următoarea:
- dacă tcalc [ t , t ] , se acceptă H0 cu o probabilitate egală cu (1-);
;n 2 ;n 2
2 2
- dacă nu se realizează această condiţie, se respinge ipoteza nulă, cu probabilitatea (1-).
Dacă se ţine cont de semnificaţia testului, regula de decizie este următoarea:
- dacă Sigt , se acceptă ipoteza nulă.
- dacă Sigt , se respinge H0.
Exemplu
Pentru repartiţia unei populaţii de 50 firme după profitul realizat (variabila dependentă Y,
exprimată în sute milioane lei) şi cheltuielile cu publicitatea (variabila independentă X,
exprimată în milioane lei), testarea parametrilor este realizată în SPSS pe baza rezultatelor din
tabelul de mai jos.
Coefficientsa
Standardized
Uns tandardized Coefficients Coefficients
Model B Std. Error Beta t Sig.
1 (Cons tant) -3.951 1.795 -2.201 .033
cheltuieli cu publicitatea .100 .022 .551 4.540 .000
a. Dependent Variable: profitul
Econometrie – Dănuţ JEMNA
30 Regresia liniară simplă
Valoarea calculată a testului Student, pentru fiecare parametru, se obţine prin relaţia
b
tcalc i , i 0 ,1 .
sˆ
i
În tabelul de mai sus, estimaţiile parametrilor modelului de regresie se găsesc în coloana a
doua (valorile lui B din coloana Unstandardized Coefficients), iar estimaţiile abaterii standard
a estimatorului se află în coloana a treia (valorile Std. Error).
Din datele tabelului de mai sus, valoarea calculată a testului, prezentată în coloana a cincea
(coloana t), se obţine prin raportul dintre valorile coloanei a doua şi a treia. De exemplu,
pentru parametrul 1 , valoarea statisticii test este:
0 ,1
tcalc 4 ,54 .
0 ,022
În coloana a patra (valoarea lui Beta), este calculată estimaţia coeficientului de regresie în
cazul standardizării variabilelor din model. Valoarea coeficientului de regresie este identică,
în acest caz, cu cea a coeficientului de corelaţie (r=0,551).
În ultima coloană a tabelului sunt prezentate valorile calculate ale probabilităţilor cu care se
obţin cele două estimaţii ale parametrilor (Sig t).
Aplicând regula de decizie prin compararea pragului de semnificaţie cu valoarea Sig t, se ia
decizia de a respinge ipoteza nulă cu o probabilitate de 95% pentru fiecare parametru în parte.
În consecinţă, se consideră că parametrii estimaţi sunt semnificativ diferiţi de zero, ceea ce
este echivalent cu a spune că între cele două variabile există o legătură de tip liniar.
Testarea modelului de regresie
Modelul de regresie se testează cu ajutorul testului Fisher. Este un test asupra semnificaţiei
modelului de regresie utilizat.
În acest caz, ipoteza nulă se formulează asupra ambilor parametri ai modelului:
H 0 : 0 0 , 1 0 (modelul nu este semnificativ);
H 1 : 0 0 , 1 0 (modelul explică semnificativ legătura dintre variabile).
Statistica Fisher se construieşte pe baza procedeului de descompunere a variaţiei totale a
variabilei dependente (VT) în două componente: variaţia explicată (VE) şi variaţia reziduală
(VR). Utilizând estimatorii componentelor variaţiei, se construieşte statistica:
V̂E
V̂ n k
F k 1 E ~ ( k 1,n k ) ,
V̂R V̂R k 1
nk
care urmează o lege de repartiţie Fisher, determinată de parametrii: k, numărul parametrilor
din model (pentru modelul liniar simplu k=2) şi n, volumul eşantionului.
Econometrie – Dănuţ JEMNA
Regresia liniară simplă 31
Pentru un prag de semnificaţie fixat, se citeşte valoarea teoretică F ;k 1;n k .
F ;k 1;n k
0
Figura 5. Valoarea teoretică a statisticii Fisher pentru un nivel de încredere de ( 1 )
Valoarea calculată a statisticii Fisher este:
ESS
( b0 b1 xi y )2 n k
Fcalc k 1 i .
RSS ( yi b0 b1 xi )2 k 1
nk i
Decizia se ia prin compararea valorii calculate a testului cu valoarea din tabela Fisher:
- dacă Fcalc F ;k 1;n k , se respinge ipoteza nulă;
- dacă Fcalc F ;k 1;n k , se acceptă ipoteza nulă, cu probabilitatea ( 1 ).
Exemplu
Modelul de regresie estimat pe baza datelor privind repartiţia unei populaţii de 50 firme după
profitul realizat (variabila dependentă Y, exprimată în sute milioane lei) şi cheltuielile cu
publicitatea (variabila independentă X, exprimată în milioane lei).este testat cu ajutorul
testului Fisher, conform datelor din tabelul de mai jos.
ANOVAb
Sum of
Model Squares df Mean Square F Sig.
1 Regres sion 51.021 1 51.021 20.935 .000 a
Res idual 116.979 48 2.437
Total 168.000 49
a. Predictors: (Cons tant), cheltuieli cu publicitatea
b. Dependent Variable: profitul
În tabelul ANOVA, realizat cu ajutorul programului SPSS, sunt prezentate estimaţiile
variaţiei, pe cele două componente (coloana 2, Sum of Squares), precum şi estimaţiile
varianţelor (coloana 4, Mean Squares), obţinute prin raportarea acestora la numărul de grade
de libertate (coloana 3, df).
Econometrie – Dănuţ JEMNA
32 Regresia liniară simplă
Componentele variaţiei:
- variaţia explicată estimată este 51,021 (Explained Sum of Squares sau Regression Sum of
Squares);
- variaţia reziduală estimată este 116,979 (Residual Sum of Squares);
- variaţia totală estimată, suma celor două precedente, este 168 (Total Sum of Squares);
Gradele de libertate asociate:
k – 1 = 1;
n – k = 48;
n – 1 = 49;
n = 50.
Varianţa estimată a erorilor este:
( yi b0 b1 xi )2
116 ,979
s2 i 2 ,437 .
n2 50 2
Valoarea statisticii Fisher este:
ESS
51,021
Fcalc k 1 20,935 .
RSS 2 ,437
nk
Valoarea ridicată a statisticii este determinată de valoarea scăzută a estimaţiei varianţei
erorilor, ceea ce înseamnă că modelul este valid sau este semnificativ pentru a explica
legătura dintre cele două variabile.
În condiţiile discutate, decizia cu privire la ipoteza nulă este evidentă, aşa cum o arată şi
valoarea semnificaţiei testului: Sig F = 0,0 < 0,05. Adică, cu o probabilitate de 95%, se
respinge ipoteza nulă sau ipoteza că modelul nu este adecvat realităţii studiate.
6. Testarea indicatorilor de corelaţie
a. Testarea coeficientului de corelaţie
1. Ipoteze
H 0 : 0 (între variabile nu există o legătură semnificativă);
H 1 : 0 (variabilele sunt corelate semnificativ).
2. Pragul de semnificaţie ( 0 ,05 )
3. Testul statistic
Se utilizează statistica Student, care în condiţiile acceptării ipotezei nule este:
Econometrie – Dănuţ JEMNA
Regresia liniară simplă 33
ˆ
t ~ t( n 2 ) .
1 ˆ 2
n2
4. Valorile teoretice din tabela Student
Pentru un test bilateral, se citeşte valoarea t / 2 ; n 2 .
5. Valoarea calculată a testului
La nivelul unui eşantion, se calculează:
r
tcalc .
1 r2
n2
6. Decizia
- dacă tcalc [ t / 2 ;n 2 , t / 2 ;n 2 ] , se acceptă H0 cu o probabilitate egală cu (1-);
- dacă nu se realizează această condiţie, se respinge ipoteza nulă, cu probabilitatea (1-).
b. Testarea raportului de corelaţie
Demersul testării este prezentat prin etapele de mai jos.
- Se formulează ipotezele:
H 0 : 0 între variabile nu există o legătură semnificativă);
H1 : 0 (variabilele sunt corelate semnificativ).
- Se alege pragul de semnificaţie .
- Se utilizează o statistică Fisher, care are următoarea expresie:
ˆ 2 n k
F ,
1 ˆ 2 k 1
care urmează o lege de repartiţie Fisher de k-1 şi n-k grade de libertate.
- Se citeşte valoarea teoretică F ;k 1;nk din tabela lui Fisher, pentru un prag de semnificaţie
stabilit şi pentru k-1, respectiv (n-k) grade de libertate.
- Se obţine valoarea calculată a testului:
R2 nk
Fcalc 2
,
1 R k 1
unde R2 este raportul de determinaţie calculat la nivelul unui eşantion.
Econometrie – Dănuţ JEMNA
34 Regresia liniară simplă
- Se ia decizia pe baza următoarei reguli: dacă Fcalc F ;k 1;n k , se respinge ipoteza H0. În
funcţie de semnificaţia testului, dacă SigF < , se respinge H0, cu o probabilitate egală cu 1-
.
Observaţie
Testul Fisher utilizat pentru testarea modelului este identic cu cel folosit la testarea raportului
de corelaţie:
ESS n k R2 n k
Fcalc . La baza acestei egalităţi stau relaţiile:
RSS k 1 1 R 2 k 1
ESS
R2 , TSS ESS RSS .
TSS
Econometrie – Dănuţ JEMNA
Regresia liniară simplă 35
Test2
1. În modelul de regresie liniară simplă, parametrul reprezintă:
a) ordonata la origine
b) nivelul mediu al variabilei dependente dacă variabila independentă ia valoarea 1
c) variaţia absolută medie a variabilei dependente la o variaţie absolută cu o unitate a
variabilei independente
d) panta dreptei de regresie
2. Pentru un model de regresie liniară simplă, coeficientul de corelaţie este identic cu panta
dreptei de regresie dacă:
a) valorile variabilei dependente sunt mai mari decât cele ale variabilei independente
b) valorile celor două variabile sunt standardizate
c) valorile celor două variabile sunt diferite
3. Coeficientul de determinaţie arată:
a) gradul de intensitate a legăturii dintre două variabile
b) ponderea variaţie variabilei dependente explicate de variaţia variabilei independente
c) egalitatea mediilor a două populaţii
4. Pentru variabilele nivelul salariului ($) şi numărul de ani de studii (ani) s-a obţinut rezultatul de mai
jos.
Correlations
Educational
Level (years ) Current Salary
Educational Level (years ) Pears on Correlation 1 ,661**
Sig. (2-tailed) ,000
N 474 474
Current Salary Pears on Correlation ,661** 1
Sig. (2-tailed) ,000
N 474 474
**. Correlation is s ignificant at the 0.01 level (2-tailed).
Valoarea calculată a testului Student care verifică ipoteza existenţei unei legături dintre cele două
variabile este:
a) 11,99
b) 19,11
c) 33,2
5. Pentru variabilele nivelul salariului ($) şi numărul de ani de studii (ani) s-a obţinut rezultatul de mai
jos.
Coefficients
Uns tandardi zed Standardized
Coeffi ci ents Coeffi ci ents
B Std. Error Beta t Sig.
Educati onal Level (years) 3909.907 204.547 .661 19.115 .000
(Cons tant) -18331.2 2821.912 -6.496 .000
Este valabilă interpretarea:
2 Răspunsuri la teste: 1 – c,d; 2 – b; 3 – a,b; 4 – c; 5 – b,c; 6 – a,b; 7 – a,c
Econometrie – Dănuţ JEMNA
36 Regresia liniară simplă
a) la o creştere cu 1 an a numărului de ani de studii, nivelul salariului scade în medie cu
18331,2$
b) la o creştere cu 1 an a numărului de ani de studii, nivelul salariului creşte în medie cu
3909,9$
c) cu o încredere de 95%, se respinge ipoteza că numărul de ani de studii nu are o influenţă
semnificativă asupra salariului
d) cu o eroare de 5%, se acceptă ipoteza că între cele două variabile analizate nu există nici o
legătură
6. Pentru variabilele nivelul salariului ($) şi numărul de ani de studii (ani) s-a obţinut rezultatul de mai
jos.
Correlations
Educational
Level (years ) Current Salary
Educational Level (years ) Pears on Correlation 1 ,661**
Sig. (2-tailed) ,000
N 474 474
Current Salary Pears on Correlation ,661** 1
Sig. (2-tailed) ,000
N 474 474
**. Correlation is s ignificant at the 0.01 level (2-tailed).
Este valabilă interpretarea:
a) coeficientul de corelaţie dintre cele două variabile este semnificativ statistic
b) cu o probabilitate de 95%, se respinge ipoteza că salariul nu este influenţat de nivelul de
educaţie
c) semnificaţia testului este 0,661
7. Pentru variabilele nivelul salariului ($) şi numărul de ani de studii (ani) s-a obţinut rezultatul de mai
jos.
Coefficients
Uns tandardi zed Standardized
Coeffi ci ents Coeffi ci ents
B Std. Error Beta t Sig.
Educati onal Level (years) 3909.907 204.547 .661 19.115 .000
(Cons tant) -18331.2 2821.912 -6.496 .000
Este valabilă interpretarea:
a) valoarea 0,661 este estimaţia coeficientului de corelaţie
b) cu o probabilitate de 95%, se acceptă că valoare 0,661 este nesemnificativă
c) valoarea 0,661 este panta de regresie pentru modelul cu variabile standardizate
Econometrie – Dănuţ JEMNA
S-ar putea să vă placă și
- Ajustarea LiniaraDocument6 paginiAjustarea LiniaraAlina GheorgheÎncă nu există evaluări
- 1 7 Econometrie 1Document249 pagini1 7 Econometrie 1Nicoleta AlexandreanuÎncă nu există evaluări
- Curs Statistica ASEDocument13 paginiCurs Statistica ASEciprian24Încă nu există evaluări
- PRF Versus SRFDocument5 paginiPRF Versus SRFDoina ColtaÎncă nu există evaluări
- Remedial Econometrie FINAL-2Document38 paginiRemedial Econometrie FINAL-2Cristi Mitrea0% (4)
- Tema 2 Teoria Corelatiei PDFDocument25 paginiTema 2 Teoria Corelatiei PDFAlexandraBaciuÎncă nu există evaluări
- Curs5 IPOTEZEDocument82 paginiCurs5 IPOTEZECătălin MogoşÎncă nu există evaluări
- Regresia MultifactorialaDocument21 paginiRegresia Multifactorialacrinam90Încă nu există evaluări
- Regresie MultiplaDocument8 paginiRegresie MultiplaLuiza AlexandraÎncă nu există evaluări
- Curs EconometrieDocument66 paginiCurs EconometrieAndrei AgapeÎncă nu există evaluări
- Carte Grile EconometrieDocument42 paginiCarte Grile EconometrieŞtefiuc AndreeaÎncă nu există evaluări
- Cursuri ST 1-5Document153 paginiCursuri ST 1-5Axel PosiiÎncă nu există evaluări
- Ex6 HeteroscedasticitateDocument8 paginiEx6 HeteroscedasticitateAndreea StefanÎncă nu există evaluări
- NDocument47 paginiNdianaurecheÎncă nu există evaluări
- Curs 4 EconometrieDocument33 paginiCurs 4 Econometrieandreeamada119006Încă nu există evaluări
- Tema EconometrieDocument5 paginiTema EconometrieMihaela CapugiuÎncă nu există evaluări
- Continutul Social-Economic Al FinantelorDocument4 paginiContinutul Social-Economic Al FinantelorLilianaÎncă nu există evaluări
- Seminar 5 Econometrie CSIE SpataruDocument7 paginiSeminar 5 Econometrie CSIE SpataruEvi Eliza CondeescuÎncă nu există evaluări
- Introducere În Analiza Seriilor de TimpDocument32 paginiIntroducere În Analiza Seriilor de TimpAna JumaraÎncă nu există evaluări
- Grile Partial EconometrieDocument15 paginiGrile Partial EconometrieMihaela IzmanÎncă nu există evaluări
- EconometrieDocument15 paginiEconometrieDidy DianaÎncă nu există evaluări
- Econometrie Subiecte Pentru ExamenDocument5 paginiEconometrie Subiecte Pentru ExamenOana RaduÎncă nu există evaluări
- Referat Econometrie (AutoRecovered)Document6 paginiReferat Econometrie (AutoRecovered)alinaÎncă nu există evaluări
- Tema 1 EconometrieDocument25 paginiTema 1 EconometrieRaduAlexandruDragoniciÎncă nu există evaluări
- Capitolul 3. Modelul de Regresie Liniara MultiplaDocument6 paginiCapitolul 3. Modelul de Regresie Liniara MultiplaAmihaesii CosminÎncă nu există evaluări
- Previziune ExamenDocument5 paginiPreviziune ExamenMarius BolintiruÎncă nu există evaluări
- Seminar4 Econometrie (23.10.2017)Document6 paginiSeminar4 Econometrie (23.10.2017)Lila YamanÎncă nu există evaluări
- Statistica 221116 230043Document73 paginiStatistica 221116 230043Lorena TuranscheÎncă nu există evaluări
- Autocorelatia ErorilorDocument15 paginiAutocorelatia ErorilorMariana CaramanÎncă nu există evaluări
- C8 DummyDocument19 paginiC8 DummyDreaam WizÎncă nu există evaluări
- Proiect Econometrie Andra Buică FinaaalDocument11 paginiProiect Econometrie Andra Buică FinaaalClaudiu HartonÎncă nu există evaluări
- Ecoonometrie Grile FuratDocument11 paginiEcoonometrie Grile FuratVlada JitariucÎncă nu există evaluări
- Curs10 Econometrie Ip Med HomoscDocument42 paginiCurs10 Econometrie Ip Med HomoscMatei Stefan VladÎncă nu există evaluări
- Curs 8 - 9 Validarea Modelului de RegresieDocument27 paginiCurs 8 - 9 Validarea Modelului de RegresieMarius StancuÎncă nu există evaluări
- Finante, Suport de Curs, 9 Si 11Document6 paginiFinante, Suport de Curs, 9 Si 11Georgiana CrăciunÎncă nu există evaluări
- Grile EconometrieDocument28 paginiGrile EconometrieDorina DorinaÎncă nu există evaluări
- Academia de Studii EconomiceDocument16 paginiAcademia de Studii EconomiceAlexandra Laura SustacÎncă nu există evaluări
- Regresie Liniara DEPI-IIIB-LAB PDFDocument5 paginiRegresie Liniara DEPI-IIIB-LAB PDFAndreeaÎncă nu există evaluări
- Seminar VI BaltiDocument4 paginiSeminar VI BaltiValeria GÎncă nu există evaluări
- Proiect Model Liniar UnifactorialDocument14 paginiProiect Model Liniar UnifactorialAlina MateiaseviciÎncă nu există evaluări
- 8 1curs EconometrieDocument29 pagini8 1curs EconometrieRoxana BargaoanuÎncă nu există evaluări
- Test 1 EconometrieDocument2 paginiTest 1 EconometrieNina CebotariÎncă nu există evaluări
- 9 Regr CorelatieDocument21 pagini9 Regr CorelatiePetronela MusteataÎncă nu există evaluări
- Ui 6 Circuitul Economic de Ansamblu, 7 Venit, Consum Si InvestitiiDocument24 paginiUi 6 Circuitul Economic de Ansamblu, 7 Venit, Consum Si InvestitiiStefanescu MirceaÎncă nu există evaluări
- EConometrieDocument15 paginiEConometrieCristea ClaudiaÎncă nu există evaluări
- Recapitulare Neliniar - IpotezeDocument10 paginiRecapitulare Neliniar - IpotezeSpatari AdrianÎncă nu există evaluări
- StatisticăDocument13 paginiStatisticămaxim100% (1)
- Cig Id 2021-2022Document10 paginiCig Id 2021-2022Georgiana Elena PopescuÎncă nu există evaluări
- Compressed DaddyDocument1.803 paginiCompressed DaddyVlad Alexandru GuritaÎncă nu există evaluări
- Proiect EconometrieDocument12 paginiProiect Econometriesergiu2SÎncă nu există evaluări
- Econometrie Anul 2Document3 paginiEconometrie Anul 2Gheorghita AjitariteiÎncă nu există evaluări
- Indicatorii EconomiciDocument48 paginiIndicatorii EconomiciAndrei CorladeÎncă nu există evaluări
- Grile Econometrie 1Document157 paginiGrile Econometrie 1Andra StoleruÎncă nu există evaluări
- Econometrie Avansata PDFDocument140 paginiEconometrie Avansata PDFMădă CionilăÎncă nu există evaluări
- 0 Cuprins PDFDocument6 pagini0 Cuprins PDFIonut GamuleaÎncă nu există evaluări
- Alin Marius ANDRIEŞ LUCRARE BUNA PENTRU LICENTADocument48 paginiAlin Marius ANDRIEŞ LUCRARE BUNA PENTRU LICENTADiordiev IuliaÎncă nu există evaluări
- Curs5 Econometrie RLM (I)Document25 paginiCurs5 Econometrie RLM (I)AdinaFraierÎncă nu există evaluări
- Regresie Liniara Simpla US2Document22 paginiRegresie Liniara Simpla US2DumitrascuBogdanÎncă nu există evaluări
- Analiza Econometrica A Unui Model Liniar - Din M. ADocument48 paginiAnaliza Econometrica A Unui Model Liniar - Din M. AAlexe Bogdan100% (1)
- Modelul de Regresie Liniara SimplaDocument15 paginiModelul de Regresie Liniara SimplaDeea Andreea100% (1)
- Finante IntreprindereDocument5 paginiFinante IntreprinderePaul IonutÎncă nu există evaluări
- Proiect Management Id MNG Cig FBDocument1 paginăProiect Management Id MNG Cig FBPaul IonutÎncă nu există evaluări
- 2019 TC 1. Exemplificarea Principiilor Si Uzantelor Utilizate Ȋn Activitatea Bancară - PTB Id PDFDocument8 pagini2019 TC 1. Exemplificarea Principiilor Si Uzantelor Utilizate Ȋn Activitatea Bancară - PTB Id PDFPaul IonutÎncă nu există evaluări
- Pret PsihologicDocument6 paginiPret PsihologicPaul IonutÎncă nu există evaluări
- GRILE Ifme Anul 3 Semestrul 1 1 1Document45 paginiGRILE Ifme Anul 3 Semestrul 1 1 1Pricob Ioan0% (1)
- Grile MK PDFDocument23 paginiGrile MK PDFPaul IonutÎncă nu există evaluări
- Licenta SPE 2013 GrileDocument69 paginiLicenta SPE 2013 GrileRaluca GiurgiteanuÎncă nu există evaluări