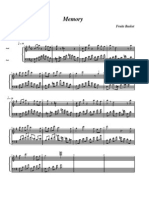
S-ar putea să vă placă și
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (120)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- Types of WomanDocument16 paginiTypes of Womanveerendra75% (4)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Earth Pressure At-Rest PDFDocument7 paginiEarth Pressure At-Rest PDFvpb literaturaÎncă nu există evaluări
- Sample Behavioral Interview QuestionsDocument3 paginiSample Behavioral Interview QuestionssanthoshvÎncă nu există evaluări
- Discourse Analysis: Understanding How We Understand.: Ey WordDocument7 paginiDiscourse Analysis: Understanding How We Understand.: Ey WordTommy NickelsonÎncă nu există evaluări
- Synonyms & Antonyms - T Đ NG Nghĩa Trái NghĩaDocument25 paginiSynonyms & Antonyms - T Đ NG Nghĩa Trái NghĩaDiep NguyenÎncă nu există evaluări
- Exercise of English LanguageDocument2 paginiExercise of English LanguageErspnÎncă nu există evaluări
- Paranthropology Vol 3 No 3Document70 paginiParanthropology Vol 3 No 3George ZafeiriouÎncă nu există evaluări
- Pts English Kelas XDocument6 paginiPts English Kelas XindahÎncă nu există evaluări
- Technical Report No. 1/12, February 2012 Jackknifing The Ridge Regression Estimator: A Revisit Mansi Khurana, Yogendra P. Chaubey and Shalini ChandraDocument22 paginiTechnical Report No. 1/12, February 2012 Jackknifing The Ridge Regression Estimator: A Revisit Mansi Khurana, Yogendra P. Chaubey and Shalini ChandraRatna YuniartiÎncă nu există evaluări
- Gary Molander Syllabus 2014Document3 paginiGary Molander Syllabus 2014AlexGeorgeÎncă nu există evaluări
- Construction Manual California PDFDocument956 paginiConstruction Manual California PDFAlexander Ponce VelardeÎncă nu există evaluări
- Sample Intern PropDocument7 paginiSample Intern PropmaxshawonÎncă nu există evaluări
- Barrier Free EnvironmentDocument15 paginiBarrier Free EnvironmentRavi Chandra100% (2)
- A Dynamic Model For Automotive Engine Control AnalysisDocument7 paginiA Dynamic Model For Automotive Engine Control Analysisekitani6817Încă nu există evaluări
- Peranan Dan Tanggungjawab PPPDocument19 paginiPeranan Dan Tanggungjawab PPPAcillz M. HaizanÎncă nu există evaluări
- Fruits Basket - MemoryDocument1 paginăFruits Basket - Memorywane10132100% (1)
- STIers Meeting Industry ProfessionalsDocument4 paginiSTIers Meeting Industry ProfessionalsAdrian Reloj VillanuevaÎncă nu există evaluări
- 432 HZ - Unearthing The Truth Behind Nature's FrequencyDocument6 pagini432 HZ - Unearthing The Truth Behind Nature's FrequencyShiv KeskarÎncă nu există evaluări
- Business Decision MakingDocument5 paginiBusiness Decision MakingShafiya CaderÎncă nu există evaluări
- APO Overview Training - PPDSDocument22 paginiAPO Overview Training - PPDSVijay HajnalkerÎncă nu există evaluări
- P1 88thminutesDocument42 paginiP1 88thminutesVaishnavi JayakumarÎncă nu există evaluări
- Conceptualizing Teacher Professional LearningDocument33 paginiConceptualizing Teacher Professional LearningPaula Reis Kasmirski100% (1)
- Taylor Linker ResumeDocument2 paginiTaylor Linker ResumeTaylor LinkerÎncă nu există evaluări
- Al Maps Ulas PDFDocument3 paginiAl Maps Ulas PDFMaycol FernandoÎncă nu există evaluări
- CT Analyzer Whats New V4 52 ENUDocument6 paginiCT Analyzer Whats New V4 52 ENUSivakumar NatarajanÎncă nu există evaluări
- فص یروئت Queuining TheoryDocument47 paginiفص یروئت Queuining Theorycampal123Încă nu există evaluări
- Exp#4-Gas TurbineDocument9 paginiExp#4-Gas TurbineLilo17xiÎncă nu există evaluări
- Chemistry Chemical EngineeringDocument124 paginiChemistry Chemical Engineeringjrobs314Încă nu există evaluări
- Low Power VLSI Circuits and Systems Prof. Ajit Pal Department of Computer Science and Engineering Indian Institute of Technology, KharagpurDocument22 paginiLow Power VLSI Circuits and Systems Prof. Ajit Pal Department of Computer Science and Engineering Indian Institute of Technology, KharagpurDebashish PalÎncă nu există evaluări
- UgvDocument24 paginiUgvAbhishek MatÎncă nu există evaluări