S-ar putea să vă placă și
- Assignment 3Document6 paginiAssignment 3Ray GuoÎncă nu există evaluări
- Assignment 5Document8 paginiAssignment 5Ray GuoÎncă nu există evaluări
- Assignment 8Document6 paginiAssignment 8Ray GuoÎncă nu există evaluări
- Assignment 4Document4 paginiAssignment 4Ray GuoÎncă nu există evaluări
- Assignment 6Document9 paginiAssignment 6Ray GuoÎncă nu există evaluări
- Isye HW2Document10 paginiIsye HW2Kevin FongÎncă nu există evaluări
- 02 Visualize SlidesDocument92 pagini02 Visualize Slidesandy kcÎncă nu există evaluări
- Task 1Document9 paginiTask 1Dương Vũ MinhÎncă nu există evaluări
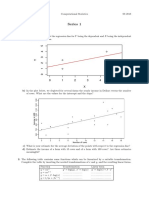
- Series 1Document2 paginiSeries 1Sangwoo KimÎncă nu există evaluări
- PSPDocument45 paginiPSPadeem MirÎncă nu există evaluări
- Chi-Square: Example ProblemDocument7 paginiChi-Square: Example ProblemZsa ChuÎncă nu există evaluări
- Gap AnalysisDocument27 paginiGap AnalysisSindy Martinez CallejasÎncă nu există evaluări
- Metanalisis Con RDocument8 paginiMetanalisis Con RHéctor W Moreno QÎncă nu există evaluări
- Lab 4 Classification v.0Document5 paginiLab 4 Classification v.0rusoÎncă nu există evaluări
- Final Project - Regression ModelsDocument35 paginiFinal Project - Regression ModelsCaio Henrique Konyosi Miyashiro100% (1)
- Calculus AnswersDocument21 paginiCalculus AnswersNamita Razdan100% (1)
- Lecture 3Document90 paginiLecture 3Ruben KempterÎncă nu există evaluări
- Session 13 - Wednesday 19th OctoberDocument37 paginiSession 13 - Wednesday 19th OctoberSana SoomroÎncă nu există evaluări
- Geom HistogramDocument4 paginiGeom HistogramShivani SharmaÎncă nu există evaluări
- Lecture08 CaiDocument20 paginiLecture08 CaiWilliam Sin Chau WaiÎncă nu există evaluări
- Introduction To Matlab: AppendixDocument12 paginiIntroduction To Matlab: Appendixtdk13Încă nu există evaluări
- Matrix Math Packages User's GuideDocument10 paginiMatrix Math Packages User's GuideemillianoÎncă nu există evaluări
- VII Pearson RDocument4 paginiVII Pearson RJamaica AntonioÎncă nu există evaluări
- Matrix Math Packages User's GuideDocument10 paginiMatrix Math Packages User's GuideemillianoÎncă nu există evaluări
- Final AssignmentDocument4 paginiFinal AssignmentTalha TariqÎncă nu există evaluări
- R Regression CommandsDocument5 paginiR Regression CommandsHaritha AtluriÎncă nu există evaluări
- Curve Fitting - Lecturers - 2Document21 paginiCurve Fitting - Lecturers - 2Girma JankaÎncă nu există evaluări
- NA Lab 9Document12 paginiNA Lab 9Fahad kamranÎncă nu există evaluări
- CappstoneDocument2 paginiCappstoneAnkita MishraÎncă nu există evaluări
- Meyers Risk Aversion OptimizationDocument25 paginiMeyers Risk Aversion OptimizationAdnan KamalÎncă nu există evaluări
- Statistische Auswertung WiederfindungsfunktionDocument7 paginiStatistische Auswertung WiederfindungsfunktionMichael HuberÎncă nu există evaluări
- Tutorial Implementación Computacional de Modelos Matemáticos para Planificación de Operaciones - Jupyter NotebookDocument10 paginiTutorial Implementación Computacional de Modelos Matemáticos para Planificación de Operaciones - Jupyter NotebookAlejandro SepúlvedaÎncă nu există evaluări
- wk3 Prog Assign Collinear Points PDFDocument3 paginiwk3 Prog Assign Collinear Points PDFMax YadlovskiyÎncă nu există evaluări
- HW6 SolutionDocument10 paginiHW6 Solutionrita901112Încă nu există evaluări
- Statistics Chapter3Document60 paginiStatistics Chapter3Zhiye Tang100% (1)
- Unit 4 - Linear RegressionDocument52 paginiUnit 4 - Linear RegressionshinjoÎncă nu există evaluări
- Basic Simulation Lab File 2Document40 paginiBasic Simulation Lab File 2test 1831Încă nu există evaluări
- Fan CovaDocument18 paginiFan CovaJose Camilo Diaz GranadosÎncă nu există evaluări
- 4503 Rc158 010d Machinelearning 1Document6 pagini4503 Rc158 010d Machinelearning 1AhsanAnisÎncă nu există evaluări
- Fashion MNIST-6Document10 paginiFashion MNIST-6akif barbaros dikmenÎncă nu există evaluări
- Predicting Used Car PricesDocument7 paginiPredicting Used Car PricesDipak MaliÎncă nu există evaluări
- LinearRegression AnnotatedDocument116 paginiLinearRegression Annotatedmr robotÎncă nu există evaluări
- Exercises QuestionDocument30 paginiExercises QuestionAgalievÎncă nu există evaluări
- Sturm Liou Ville 3Document6 paginiSturm Liou Ville 3imran5705074Încă nu există evaluări
- Predicting Used Car PricesDocument7 paginiPredicting Used Car PricesDipak MaliÎncă nu există evaluări
- Metodos Numericos HW4Document11 paginiMetodos Numericos HW4WalterRadoVillalobosÎncă nu există evaluări
- Rstudio Study Notes For PA 20181126Document6 paginiRstudio Study Notes For PA 20181126Trong Nghia VuÎncă nu există evaluări
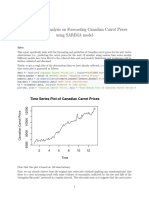
- TimeSeries SARIMADocument15 paginiTimeSeries SARIMAHofidisÎncă nu există evaluări
- Day1 PPTDocument26 paginiDay1 PPTvinitÎncă nu există evaluări
- BS Atkt QBDocument13 paginiBS Atkt QBReuben DsouzaÎncă nu există evaluări
- Lab Geo StatisticsDocument8 paginiLab Geo StatisticsErdiApatay100% (1)
- C MathDocument7 paginiC MathSanyamkumar HansdahÎncă nu există evaluări
- AnalytixLabs - Linear Regression - 1623137749089Document41 paginiAnalytixLabs - Linear Regression - 1623137749089Sarthak SharmaÎncă nu există evaluări
- Linear Regression: Machine LearningDocument9 paginiLinear Regression: Machine LearningVivek ThotaÎncă nu există evaluări
- DIRECT Optimization Algorithm User GuideDocument14 paginiDIRECT Optimization Algorithm User GuideMostafa MangalÎncă nu există evaluări
- Komputasi Statistik: Pertemuan XDocument22 paginiKomputasi Statistik: Pertemuan XDwi Satria FirmansyahÎncă nu există evaluări
- Mathematical Modeling 4th Edition Meerschaert Solutions ManualDocument18 paginiMathematical Modeling 4th Edition Meerschaert Solutions ManualKylieWilsonkpzrg100% (14)
- Functions in MATLAB: X 2.75 y X 2 + 5 X + 7 y 2.8313e+001Document21 paginiFunctions in MATLAB: X 2.75 y X 2 + 5 X + 7 y 2.8313e+001Rafflesia KhanÎncă nu există evaluări
- Simple Linear Regression in RDocument17 paginiSimple Linear Regression in RGianni GorgoglioneÎncă nu există evaluări
- C Program To Find Transpose of A MatrixDocument1 paginăC Program To Find Transpose of A MatrixVishwas ShuklaÎncă nu există evaluări
- Renault Megane2 PDFDocument14 paginiRenault Megane2 PDFMelinte Lucian GeorgeÎncă nu există evaluări
- Form Rekap TC Pos 03Document44 paginiForm Rekap TC Pos 03Wahyoeddin NoerÎncă nu există evaluări
- EC7 Wiring Diagram 20091020 - EN PDFDocument238 paginiEC7 Wiring Diagram 20091020 - EN PDFMiguel A. CastillonÎncă nu există evaluări
- Introduction To Automotive TechnologyDocument11 paginiIntroduction To Automotive TechnologyBalaraman100% (1)
- Vios InteriorDocument122 paginiVios Interiorang6632Încă nu există evaluări
- Transport English. Answer Key1Document48 paginiTransport English. Answer Key1Jogi Nero100% (1)
- Assignment No 1 Classification of Cars Submitted by Muhammad Hamza (18au07) Submitted To Engr Farhan Ijaz Subject Appraisal & Evolution of Used CarsDocument9 paginiAssignment No 1 Classification of Cars Submitted by Muhammad Hamza (18au07) Submitted To Engr Farhan Ijaz Subject Appraisal & Evolution of Used Carsahmad razaÎncă nu există evaluări
- Auto AssemblyDocument2 paginiAuto AssemblySujan MondalÎncă nu există evaluări
- 01 - Venugopal - Individual AssignmentDocument9 pagini01 - Venugopal - Individual AssignmentPrasanth VngÎncă nu există evaluări
- Let Talk About Sport and TransportDocument3 paginiLet Talk About Sport and TransportBlack AutumnÎncă nu există evaluări
- Te Automotive WorksheetsDocument36 paginiTe Automotive WorksheetsMarcio Noe0% (1)
- Automotive Engineering Dissertation IdeasDocument7 paginiAutomotive Engineering Dissertation IdeasPaperWritersCollegeCanada100% (1)
- Examen ControlDocument46 paginiExamen ControlRamiro RiosÎncă nu există evaluări
- Mazda 323/protege 1995-98Document22 paginiMazda 323/protege 1995-98Jhay Mello100% (1)
- Me6602 - Automobile Engineering: Unit I - Vehicle Structure and EnginesDocument65 paginiMe6602 - Automobile Engineering: Unit I - Vehicle Structure and Enginesadnan bin sultanÎncă nu există evaluări
- Excel Course Part 3 - FormulaDocument372 paginiExcel Course Part 3 - FormulaArnab BhattacharyaÎncă nu există evaluări
- Procedura Roll Up Down Geamuri VWDocument11 paginiProcedura Roll Up Down Geamuri VWMarincu SorinÎncă nu există evaluări
- Automotive TechnologyDocument11 paginiAutomotive TechnologyDhasarathan Krishnan100% (9)
- Lighting PDFDocument204 paginiLighting PDFkikokadola100% (1)
- Unturned Item CodesDocument11 paginiUnturned Item CodesEray KırcaÎncă nu există evaluări
- Auto FinancingDocument62 paginiAuto Financingharshul_777880Încă nu există evaluări
- Glossary For Automotive DesignDocument7 paginiGlossary For Automotive DesignNitin SharmaÎncă nu există evaluări
- Sinclair's Impala Parts Catalog 2012Document76 paginiSinclair's Impala Parts Catalog 2012Mark Sinclair100% (1)
- Types of Cars: 2 6.most Common Gearbox Problems That May Lead To Unnecessary RepairlDocument12 paginiTypes of Cars: 2 6.most Common Gearbox Problems That May Lead To Unnecessary RepairlVishal SahaniÎncă nu există evaluări
- Honda GALANTDocument14 paginiHonda GALANTposlovni2Încă nu există evaluări
- Assignment 2.1Document19 paginiAssignment 2.1Jasmine SebastianÎncă nu există evaluări
- 1963 Ford GalaxieDocument190 pagini1963 Ford GalaxieLuis100% (1)
- GROUP 1 REPORT - Auto Assembly (LP Case)Document3 paginiGROUP 1 REPORT - Auto Assembly (LP Case)Butch TuanÎncă nu există evaluări
- Amortyzatory 2008Document199 paginiAmortyzatory 2008Adam ChmurakÎncă nu există evaluări
- Peugeot 408 Press Info EnglishDocument19 paginiPeugeot 408 Press Info Englishanthonykylim100% (1)
- How to Build a Car: The Autobiography of the World’s Greatest Formula 1 DesignerDe la EverandHow to Build a Car: The Autobiography of the World’s Greatest Formula 1 DesignerEvaluare: 4.5 din 5 stele4.5/5 (54)
- Faster: How a Jewish Driver, an American Heiress, and a Legendary Car Beat Hitler's BestDe la EverandFaster: How a Jewish Driver, an American Heiress, and a Legendary Car Beat Hitler's BestEvaluare: 4 din 5 stele4/5 (28)
- Automotive Electronic Diagnostics (Course 1)De la EverandAutomotive Electronic Diagnostics (Course 1)Evaluare: 5 din 5 stele5/5 (6)
- ANSYS Workbench 2023 R2: A Tutorial Approach, 6th EditionDe la EverandANSYS Workbench 2023 R2: A Tutorial Approach, 6th EditionÎncă nu există evaluări
- Powder Coating: A How-to Guide for Automotive, Motorcycle, and Bicycle PartsDe la EverandPowder Coating: A How-to Guide for Automotive, Motorcycle, and Bicycle PartsEvaluare: 4.5 din 5 stele4.5/5 (17)
- Competition Engine Building: Advanced Engine Design and Assembly TechniquesDe la EverandCompetition Engine Building: Advanced Engine Design and Assembly TechniquesEvaluare: 4.5 din 5 stele4.5/5 (7)
- Weld Like a Pro: Beginning to Advanced TechniquesDe la EverandWeld Like a Pro: Beginning to Advanced TechniquesEvaluare: 4.5 din 5 stele4.5/5 (6)
- Tips On How to Build a Street Legal Motorized Bicycle; (That Will Save You a Lot of Aggravation and Money)De la EverandTips On How to Build a Street Legal Motorized Bicycle; (That Will Save You a Lot of Aggravation and Money)Încă nu există evaluări
- Modern Engine Blueprinting Techniques: A Practical Guide to Precision Engine BlueprintingDe la EverandModern Engine Blueprinting Techniques: A Practical Guide to Precision Engine BlueprintingEvaluare: 4.5 din 5 stele4.5/5 (9)
- Small Engines and Outdoor Power Equipment: A Care & Repair Guide for: Lawn Mowers, Snowblowers & Small Gas-Powered ImplementsDe la EverandSmall Engines and Outdoor Power Equipment: A Care & Repair Guide for: Lawn Mowers, Snowblowers & Small Gas-Powered ImplementsÎncă nu există evaluări
- CDL Study Guide 2024-2025: Everything You Need to Know to Pass the Commercial Driver’s License Exam on your First Attempt, with the Most Complete and Up-to-Date Practice Tests - New VersionDe la EverandCDL Study Guide 2024-2025: Everything You Need to Know to Pass the Commercial Driver’s License Exam on your First Attempt, with the Most Complete and Up-to-Date Practice Tests - New VersionEvaluare: 5 din 5 stele5/5 (2)
- How to Fabricate Automotive Fiberglass & Carbon Fiber PartsDe la EverandHow to Fabricate Automotive Fiberglass & Carbon Fiber PartsEvaluare: 5 din 5 stele5/5 (4)
- Allison Transmissions: How to Rebuild & Modify: How to Rebuild & ModifyDe la EverandAllison Transmissions: How to Rebuild & Modify: How to Rebuild & ModifyEvaluare: 5 din 5 stele5/5 (1)
- Automotive Machining: A Guide to Boring, Decking, Honing & MoreDe la EverandAutomotive Machining: A Guide to Boring, Decking, Honing & MoreEvaluare: 4.5 din 5 stele4.5/5 (11)
- OBD-I and OBD-II: A Complete Guide to Diagnosis, Repair, and Emissions ComplianceDe la EverandOBD-I and OBD-II: A Complete Guide to Diagnosis, Repair, and Emissions ComplianceÎncă nu există evaluări
- Data Acquisition from HD Vehicles Using J1939 CAN BusDe la EverandData Acquisition from HD Vehicles Using J1939 CAN BusÎncă nu există evaluări
- The Official Highway Code: DVSA Safe Driving for Life SeriesDe la EverandThe Official Highway Code: DVSA Safe Driving for Life SeriesEvaluare: 3.5 din 5 stele3.5/5 (25)
- Troubleshooting and Repair of Diesel EnginesDe la EverandTroubleshooting and Repair of Diesel EnginesEvaluare: 1.5 din 5 stele1.5/5 (2)
- The RVer's Bible (Revised and Updated): Everything You Need to Know About Choosing, Using, and Enjoying Your RVDe la EverandThe RVer's Bible (Revised and Updated): Everything You Need to Know About Choosing, Using, and Enjoying Your RVEvaluare: 5 din 5 stele5/5 (2)
- Why We Drive: Toward a Philosophy of the Open RoadDe la EverandWhy We Drive: Toward a Philosophy of the Open RoadEvaluare: 4.5 din 5 stele4.5/5 (21)
- Ford AOD Transmissions: Rebuilding and Modifying the AOD, AODE and 4R70WDe la EverandFord AOD Transmissions: Rebuilding and Modifying the AOD, AODE and 4R70WEvaluare: 4.5 din 5 stele4.5/5 (6)
- Why We Drive: Toward a Philosophy of the Open RoadDe la EverandWhy We Drive: Toward a Philosophy of the Open RoadEvaluare: 4 din 5 stele4/5 (6)
- Massey Ferguson 35 Tractor: Workshop Service ManualDe la EverandMassey Ferguson 35 Tractor: Workshop Service ManualEvaluare: 5 din 5 stele5/5 (4)