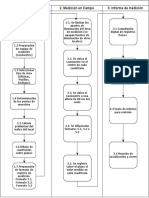
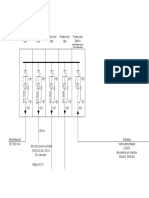
S-ar putea să vă placă și
- 23-Estimacion de Recursos Surpac - v2Document149 pagini23-Estimacion de Recursos Surpac - v2Aru Arte En Aros de Papel100% (1)
- Tarea 2 AnaliticaDocument5 paginiTarea 2 AnaliticaAdriana María Villavicencio Jara100% (1)
- Archivo 2Document13 paginiArchivo 2filibertoÎncă nu există evaluări
- Parcial - Escenario 4 - BLOQUE VACACIONAL-TEORICO-PRACTICO - VIRTUAL - SIMULACIÓN - (GRUPO V01)Document10 paginiParcial - Escenario 4 - BLOQUE VACACIONAL-TEORICO-PRACTICO - VIRTUAL - SIMULACIÓN - (GRUPO V01)Victor veraÎncă nu există evaluări
- Comandos de RDocument4 paginiComandos de RCristianÎncă nu există evaluări
- Examen 2Document5 paginiExamen 2zeonfer32Încă nu există evaluări
- Lab 1Document10 paginiLab 1Victor HenostrozaÎncă nu există evaluări
- Info Ayuda R StudioDocument9 paginiInfo Ayuda R StudioChristian Kevin TomaláÎncă nu există evaluări
- Mii522 Ent S3Document10 paginiMii522 Ent S3antonioÎncă nu există evaluări
- CluDocument8 paginiCluEdwin Johny Asnate SalazarÎncă nu există evaluări
- EstadisticaDocument47 paginiEstadisticaDEIVID STEWART RAMIREZ CASTILLOÎncă nu există evaluări
- Codigo LogitDocument4 paginiCodigo LogitDiego ArmandoÎncă nu există evaluări
- Tarea 4 Metodos NumericosDocument7 paginiTarea 4 Metodos NumericossergiomendezgzalezÎncă nu există evaluări
- Programación NET III: Profesora: Esther Lozano Candia Alumno: Erik Francisco Malagón Perrusquía. Matrícula:AL13503788Document11 paginiProgramación NET III: Profesora: Esther Lozano Candia Alumno: Erik Francisco Malagón Perrusquía. Matrícula:AL13503788jorgealberto154Încă nu există evaluări
- AlgoritmoDocument10 paginiAlgoritmoDIANA SAMUDIOÎncă nu există evaluări
- AlgoritmoDocument10 paginiAlgoritmoLEYDY SAMUDIOÎncă nu există evaluări
- ArreglosDocument15 paginiArreglosDiomarcy Paoly Peñaloza CarmonaÎncă nu există evaluări
- Practica Calificada Tercera Unidad - BDDDocument14 paginiPractica Calificada Tercera Unidad - BDDROMULO GERARDO SANCHEZ ISMODESÎncă nu există evaluări
- Tema1 PresentacionDocument18 paginiTema1 PresentacionJerselin Milagros Caceres EspejoÎncă nu există evaluări
- Clase R PrimeraDocument12 paginiClase R PrimeraAlexiaÎncă nu există evaluări
- Guía de Manejo de Rstudio 2021Document3 paginiGuía de Manejo de Rstudio 2021Miguel SalasÎncă nu există evaluări
- ACTIVIDAD DE APRENDIZAJE Practicas de R - Nro1Document9 paginiACTIVIDAD DE APRENDIZAJE Practicas de R - Nro1Deivid ZambranoÎncă nu există evaluări
- Practica 3 EstadIstica Descriptiva RDocument7 paginiPractica 3 EstadIstica Descriptiva ROswaldo ZamoraÎncă nu există evaluări
- R Tema1Document27 paginiR Tema1israel morales100% (2)
- Estadística Descriptiva Con RDocument4 paginiEstadística Descriptiva Con RLuisa Fernanda Gutierrez JaramilloÎncă nu există evaluări
- Actividad de Aprendizaje 2Document14 paginiActividad de Aprendizaje 2Jorge GarciaÎncă nu există evaluări
- N5FpsbSoxY5Uiiv - o8NxmBLxk4D0zMpr-Una de Las HerramientasDocument10 paginiN5FpsbSoxY5Uiiv - o8NxmBLxk4D0zMpr-Una de Las Herramientasviviana carolina trujilloÎncă nu există evaluări
- Analitica MetodosDocument13 paginiAnalitica MetodosPatrick Bustos MiteÎncă nu există evaluări
- Python, SAP2000 y Estructuras v3Document18 paginiPython, SAP2000 y Estructuras v3EDY JEFFERSON ERAZO TITOÎncă nu există evaluări
- 01 Introduccion HeapsDocument17 pagini01 Introduccion Heapsagordillo28Încă nu există evaluări
- Cambio Climatico 1035 SorataDocument17 paginiCambio Climatico 1035 Soratapablo zambranaÎncă nu există evaluări
- Practica de Laboratorio # 2 Big Data Proyecto de Aprendizaje Automático en PythonDocument13 paginiPractica de Laboratorio # 2 Big Data Proyecto de Aprendizaje Automático en PythonLeidy Lorena Valderrama CerqueraÎncă nu există evaluări
- Clase 1 - Uso Del R - BDocument14 paginiClase 1 - Uso Del R - BArminda Angulo CalderónÎncă nu există evaluări
- Introducción A RDocument35 paginiIntroducción A RSantiago Ramirez Santa100% (1)
- R ConsoleDocument12 paginiR ConsoleLauraÎncă nu există evaluări
- Teim Sesion 001 Latex en RStudio 16 17 PDFDocument69 paginiTeim Sesion 001 Latex en RStudio 16 17 PDFÓscar Aragón RodríguezÎncă nu există evaluări
- Fundamentos de RDocument44 paginiFundamentos de RMijin28Încă nu există evaluări
- Lab 06 Caso Integrador Trees-1Document5 paginiLab 06 Caso Integrador Trees-1Mendoza Quispe Luis JorgeÎncă nu există evaluări
- Herrera María Cbceesta U2 t2Document11 paginiHerrera María Cbceesta U2 t2Maria Jose Herrera VarelaÎncă nu există evaluări
- Una Aplicacion en 3 CapasDocument83 paginiUna Aplicacion en 3 CapasAlberto Moreno CuevaÎncă nu există evaluări
- Lab09a - Sarmiento Sumaran Alberto JavierDocument27 paginiLab09a - Sarmiento Sumaran Alberto JavierJavier SarmientoÎncă nu există evaluări
- Ciencia de Datos - Práctico - 06 - Almacenamiento en SQLiteDocument8 paginiCiencia de Datos - Práctico - 06 - Almacenamiento en SQLiteGabriel CamposÎncă nu există evaluări
- Grupo #3 TrabED1Document19 paginiGrupo #3 TrabED1ZUMOARIKUÎncă nu există evaluări
- Workclass 6 318350Document7 paginiWorkclass 6 318350Genesis Roxanna Mogrovejo AndradeÎncă nu există evaluări
- Practica 5Document8 paginiPractica 5Victor Jose Castro PinÎncă nu există evaluări
- Caret Tutorial 13Document7 paginiCaret Tutorial 13Sofia Saiz AvilaÎncă nu există evaluări
- Regresion LogisticaDocument40 paginiRegresion LogisticaOrlando SotoÎncă nu există evaluări
- Rogelio Notas RDocument116 paginiRogelio Notas Rmach_ecÎncă nu există evaluări
- Aprendizaje SupervisadoDocument6 paginiAprendizaje SupervisadoesuarezserranoÎncă nu există evaluări
- Lab 02 2022-2Document4 paginiLab 02 2022-2David Josef Vasquez PerezÎncă nu există evaluări
- Bi MateriaDocument18 paginiBi MateriaCarlos SteveÎncă nu există evaluări
- Estadística AplicadaDocument7 paginiEstadística AplicadaLogÎncă nu există evaluări
- PC2 InformeDocument17 paginiPC2 InformeMIGUEL ANGEL LESCANO AVALOSÎncă nu există evaluări
- 5.1 Arquitectura Cliente Servidor - SQLServerDocument27 pagini5.1 Arquitectura Cliente Servidor - SQLServerJuan Carlos Medina ArribasplataÎncă nu există evaluări
- R Sesión3Document45 paginiR Sesión3Servicios de Salud Pública Ciudad de MéxicoÎncă nu există evaluări
- Formato - Entrega - Tarea 6 - Chacaguasay Guaman Blanca-1Document13 paginiFormato - Entrega - Tarea 6 - Chacaguasay Guaman Blanca-1Blanquita ChacaguasayÎncă nu există evaluări
- ¿Cómo Leer - Guardar Información en R - Máxima FormaciónDocument9 pagini¿Cómo Leer - Guardar Información en R - Máxima FormaciónJuan EstebanÎncă nu există evaluări
- Script Logistic ADocument1 paginăScript Logistic ADante Palacios ValdiviezoÎncă nu există evaluări
- Bases de Datos Desde JavaDocument27 paginiBases de Datos Desde Javaana sanchezÎncă nu există evaluări
- Introduccion R-10 PDFDocument13 paginiIntroduccion R-10 PDFLuis ZamudioÎncă nu există evaluări
- UntitledDocument36 paginiUntitledShampier Moises Sierra VenturaÎncă nu există evaluări
- Análisis de datos con Power Bi, R-Rstudio y KnimeDe la EverandAnálisis de datos con Power Bi, R-Rstudio y KnimeÎncă nu există evaluări
- Diagrama Sin Título - DrawioDocument1 paginăDiagrama Sin Título - DrawiojdmarinÎncă nu există evaluări
- MIo TDocument6 paginiMIo TjdmarinÎncă nu există evaluări
- Unifilar Apique 2Document1 paginăUnifilar Apique 2jdmarinÎncă nu există evaluări
- 15.5 Presupuesto LuisaDocument400 pagini15.5 Presupuesto LuisajdmarinÎncă nu există evaluări
- CONDICIONES GENERALES CONTRATACIÓN v022020 PDFDocument36 paginiCONDICIONES GENERALES CONTRATACIÓN v022020 PDFjdmarinÎncă nu există evaluări
- PlanocableadoPNN PlanoDocument1 paginăPlanocableadoPNN PlanojdmarinÎncă nu există evaluări
- Ficha Técnica TC Exterior 17.5KV BCS-11EDocument1 paginăFicha Técnica TC Exterior 17.5KV BCS-11EjdmarinÎncă nu există evaluări
- Plantilla Estudio Tecnico de Puesta en ServicioDocument8 paginiPlantilla Estudio Tecnico de Puesta en ServiciojdmarinÎncă nu există evaluări
- monitoreo.gndelectronics.comDocument2 paginimonitoreo.gndelectronics.comjdmarinÎncă nu există evaluări
- Libro SolarDocument18 paginiLibro SolarjdmarinÎncă nu există evaluări
- CD 89971Document2 paginiCD 89971ALVAROÎncă nu există evaluări
- Cultivo CannabisDocument13 paginiCultivo CannabisjdmarinÎncă nu există evaluări
- Reactancias 2020 PDFDocument2 paginiReactancias 2020 PDFjdmarinÎncă nu există evaluări
- Plantilla Estudio Tecnico de Puesta en ServicioDocument8 paginiPlantilla Estudio Tecnico de Puesta en ServiciojdmarinÎncă nu există evaluări
- Decreto 497 Del 27 de Marzo de 2020 PDFDocument1 paginăDecreto 497 Del 27 de Marzo de 2020 PDFduvierÎncă nu există evaluări
- Presentacion Celema - Portafolio Lanzamientos 2022Document65 paginiPresentacion Celema - Portafolio Lanzamientos 2022jdmarinÎncă nu există evaluări
- Portafolio de Servicios GamacoDocument8 paginiPortafolio de Servicios GamacojdmarinÎncă nu există evaluări
- Proyecto Final de HidrologíaDocument44 paginiProyecto Final de HidrologíaSteven RestrepoÎncă nu există evaluări
- Propuesta de Un Sistema de Gestión Tecnológica para El Apoyo de La Pequeña y Mediana Industria en El SalvadorDocument932 paginiPropuesta de Un Sistema de Gestión Tecnológica para El Apoyo de La Pequeña y Mediana Industria en El SalvadorJosé Luis Montalván MartínezÎncă nu există evaluări
- La Determinación de La Vida Útil de Los Productos AlimenticiosDocument12 paginiLa Determinación de La Vida Útil de Los Productos AlimenticiosYéssica MaryrosyÎncă nu există evaluări
- Observación EstructuradaDocument4 paginiObservación Estructuradaceeci mÎncă nu există evaluări
- Tarea 2 Jesús DíazDocument4 paginiTarea 2 Jesús Díazyisus.konerÎncă nu există evaluări
- SEMANA 02 Distribución de FrecuenciasDocument17 paginiSEMANA 02 Distribución de FrecuenciasJavier SolísÎncă nu există evaluări
- Prueba Piloto-Grupo 2Document17 paginiPrueba Piloto-Grupo 2JhòÓnas AArrazolaÎncă nu există evaluări
- Practica 2 - Tamaño de Muestra-Grupo 2Document7 paginiPractica 2 - Tamaño de Muestra-Grupo 2María Elena Liñan Blas100% (1)
- Correa Cañar Evelyn Juleysi - Neira Cueva Cristhian XavierDocument9 paginiCorrea Cañar Evelyn Juleysi - Neira Cueva Cristhian XavierLeiver Leon GarciaÎncă nu există evaluări
- 4218 - Completo - Estadistica para Psicologia - AtarDocument64 pagini4218 - Completo - Estadistica para Psicologia - AtarJuan Pablo Soto AbarcaÎncă nu există evaluări
- Ejercicios Estadistica ViernesDocument1 paginăEjercicios Estadistica ViernesYolanda Sarao BaezaÎncă nu există evaluări
- Ddi Documentation Spanish 671 PDFDocument1.450 paginiDdi Documentation Spanish 671 PDFJhimy Ruiz ParedesÎncă nu există evaluări
- A1 EjerciciosDocument18 paginiA1 EjerciciosRaziel StaÎncă nu există evaluări
- Cuaderno de Trabajo de Probabilidad y Estadistica - 033252 PDFDocument136 paginiCuaderno de Trabajo de Probabilidad y Estadistica - 033252 PDFGermán ReyesÎncă nu există evaluări
- Metodologia ESPAC 2022Document56 paginiMetodologia ESPAC 2022ANA ESTEFANIA TOMALA HERRERAÎncă nu există evaluări
- LECTURA 10 MuestreoDocument22 paginiLECTURA 10 MuestreoMIRIAN ROSMERY CASTAÑEDA PÉREZÎncă nu există evaluări
- Guía de Actividades y Rúbrica de Evaluación - Fase 4 - Pruebas No ParametricasDocument16 paginiGuía de Actividades y Rúbrica de Evaluación - Fase 4 - Pruebas No ParametricasCindy RequenaÎncă nu există evaluări
- S4 MuestreoDocument48 paginiS4 MuestreoMarianella vega castroÎncă nu există evaluări
- Proyecto BofedalDocument6 paginiProyecto Bofedaljose amezquitaÎncă nu există evaluări
- Ejercicios Propuestos Sobre MEDIDAS de TDocument7 paginiEjercicios Propuestos Sobre MEDIDAS de TMaria del Carmen0% (1)
- Clase 2 Inferencia Estadistica Parte 2 Teorema Del Límite CentralDocument10 paginiClase 2 Inferencia Estadistica Parte 2 Teorema Del Límite CentralBenja DueryÎncă nu există evaluări
- Construye-Tevaluacion DiagnosticaDocument5 paginiConstruye-Tevaluacion DiagnosticaAntonio SanchezÎncă nu există evaluări
- 2010 Matematicas 68 13Document24 pagini2010 Matematicas 68 13kudasai_sugoiÎncă nu există evaluări
- Casos - Examen - Abierto (1) EstadisticaDocument9 paginiCasos - Examen - Abierto (1) EstadisticaEdgar Ricardo SHÎncă nu există evaluări
- Puican Siancas Valeria - PRACTICA 2 TERMINOLOGÍADocument2 paginiPuican Siancas Valeria - PRACTICA 2 TERMINOLOGÍAValeria PuicanÎncă nu există evaluări
- Estudio de Análisis de Fertilidad de SuelosDocument14 paginiEstudio de Análisis de Fertilidad de SuelosroyÎncă nu există evaluări
- Probabilidades y EstadisticasDocument10 paginiProbabilidades y EstadisticasDaniela MoranÎncă nu există evaluări
- Fases de InvestigacionDocument31 paginiFases de InvestigacionSara GarzaÎncă nu există evaluări
- Evidencia - 3 (2) (Autoguardado)Document4 paginiEvidencia - 3 (2) (Autoguardado)Diego Marcel Aguilar reynosoÎncă nu există evaluări