S-ar putea să vă placă și
- Quick SortDocument1 paginăQuick SortLeonardo MatteraÎncă nu există evaluări
- ShellDocument1 paginăShellLeonardo MatteraÎncă nu există evaluări
- Mas Python en CastellanoDocument1 paginăMas Python en CastellanoLeonardo MatteraÎncă nu există evaluări
- Propietario de Windows - RegDocument1 paginăPropietario de Windows - RegLeonardo MatteraÎncă nu există evaluări
- P0 PropuestaDocument10 paginiP0 PropuestaLeonardo MatteraÎncă nu există evaluări
- 37 DB Design - Conceptual DesignDocument24 pagini37 DB Design - Conceptual DesignLeonardo MatteraÎncă nu există evaluări
- C en UnitDocument7 paginiC en UnitLeonardo MatteraÎncă nu există evaluări
- CurriculumDocument4 paginiCurriculumLeonardo MatteraÎncă nu există evaluări
- CurriculumDocument4 paginiCurriculumLeonardo MatteraÎncă nu există evaluări
- Error SQLDocument1 paginăError SQLLeonardo MatteraÎncă nu există evaluări
- Activar Visual Studio 2008 en Windows 7 y Superiores Sin DesinstalarloDocument3 paginiActivar Visual Studio 2008 en Windows 7 y Superiores Sin DesinstalarloLeonardo MatteraÎncă nu există evaluări
- EjerciciosDocument102 paginiEjerciciosLeonardo MatteraÎncă nu există evaluări
- 39 DB DesignDocument27 pagini39 DB DesignloquiÎncă nu există evaluări
- Visual Studio 2005 y Visual Studio 2008Document1 paginăVisual Studio 2005 y Visual Studio 2008Leonardo MatteraÎncă nu există evaluări
- Casos 2020Document12 paginiCasos 2020Leonardo MatteraÎncă nu există evaluări
- Presupuesto 2020Document5 paginiPresupuesto 2020Leonardo MatteraÎncă nu există evaluări
- Arquitectura 2020Document3 paginiArquitectura 2020Leonardo MatteraÎncă nu există evaluări
- Ficha 2019-2020Document10 paginiFicha 2019-2020Leonardo MatteraÎncă nu există evaluări
- Proyectos 2020Document4 paginiProyectos 2020Leonardo MatteraÎncă nu există evaluări
- Prototipo 2020Document2 paginiPrototipo 2020Leonardo MatteraÎncă nu există evaluări
- PX SchedulingDocument46 paginiPX SchedulingAndres ZxerÎncă nu există evaluări
- Propuesta 2020Document3 paginiPropuesta 2020Leonardo MatteraÎncă nu există evaluări
- HX MetaheuristicsDocument19 paginiHX MetaheuristicsLeonardo MatteraÎncă nu există evaluări
- TrabajosDocument3 paginiTrabajosLeonardo MatteraÎncă nu există evaluări
- A6 GamesDocument18 paginiA6 GamesLeonardo MatteraÎncă nu există evaluări
- MatlabDocument32 paginiMatlabCarlos Andres DiazÎncă nu există evaluări
- P1 Planning PDFDocument38 paginiP1 Planning PDFLeonardo MatteraÎncă nu există evaluări
- A4 Uninformed SearchDocument36 paginiA4 Uninformed SearchLeonardo MatteraÎncă nu există evaluări
- A5 Heuristic SearchDocument18 paginiA5 Heuristic SearchKarla Barajas PérezÎncă nu există evaluări
- P9 PDDLDocument19 paginiP9 PDDLLeonardo MatteraÎncă nu există evaluări
- Paralelo D SorayaRecalde PDFDocument5 paginiParalelo D SorayaRecalde PDFSory RecaldeÎncă nu există evaluări
- Adsl 2021Document49 paginiAdsl 2021Kevin Ascue ContrerasÎncă nu există evaluări
- 01 Introduction To GCP Es-419 PDFDocument19 pagini01 Introduction To GCP Es-419 PDFVictor Hugo MoralesÎncă nu există evaluări
- SI01 Guiada. - Hardware de Un Sistema Informático.Document60 paginiSI01 Guiada. - Hardware de Un Sistema Informático.DiegoÎncă nu există evaluări
- Tramite DocumentarioDocument2 paginiTramite DocumentarioDiego diaz chota100% (1)
- Olagarro Bat Garajean: Testua Irakurri Eta Ulermen Galderak ErantzunDocument6 paginiOlagarro Bat Garajean: Testua Irakurri Eta Ulermen Galderak ErantzunManex EtxeberriaÎncă nu există evaluări
- Catalogo Genius 8Document14 paginiCatalogo Genius 8icaroblueÎncă nu există evaluări
- Cap 21 Arquitectura de Sistemas de SeguridadDocument43 paginiCap 21 Arquitectura de Sistemas de SeguridadLAZARTE MELEAN DULISETHÎncă nu există evaluări
- Taco Coayla Renzo PDFDocument183 paginiTaco Coayla Renzo PDFGabriel SardonÎncă nu există evaluări
- Tema 2 Canalizaciones y CableadosDocument20 paginiTema 2 Canalizaciones y Cableadosguadala72hotmail.comÎncă nu există evaluări
- BDD 2022-02 U3-01 NormalizacionDocument16 paginiBDD 2022-02 U3-01 NormalizacionHarry ZuritaÎncă nu există evaluări
- Redes de transmisión de datos: conceptos y componentesDocument11 paginiRedes de transmisión de datos: conceptos y componentesMaxwell AlfredoÎncă nu există evaluări
- Sesión 10 - Sistemas Empresariales de GTI ERP CRM SCM CMIDocument22 paginiSesión 10 - Sistemas Empresariales de GTI ERP CRM SCM CMIKatja Janeth Ruiz MaravíÎncă nu există evaluări
- Documento de Alejandro Rodríguez?Document6 paginiDocumento de Alejandro Rodríguez?-borja LOL-Încă nu există evaluări
- Tipos de Averías en Equipos InformáticosDocument14 paginiTipos de Averías en Equipos InformáticosCarlos CastroÎncă nu există evaluări
- Certificación Teldat de Iniciación (CTI) : © Teldat, S.A. - Todos Los Derechos ReservadosDocument138 paginiCertificación Teldat de Iniciación (CTI) : © Teldat, S.A. - Todos Los Derechos ReservadosAngel MuñozÎncă nu există evaluări
- Como Crear Paginas Web Con HTMLDocument7 paginiComo Crear Paginas Web Con HTMLFausto Valencia SantamaríaÎncă nu există evaluări
- Actividad 7 - Arquitectura Del OrdenadorDocument4 paginiActividad 7 - Arquitectura Del OrdenadorCarlota Cabeza ReyÎncă nu există evaluări
- Integración facturas electrónicas Perú v13Document87 paginiIntegración facturas electrónicas Perú v13grs030391Încă nu există evaluări
- Taller Control Enlace de DatosDocument4 paginiTaller Control Enlace de Datosjankarlos viedaÎncă nu există evaluări
- Ejemplo Dictamen de La Auditoria 2017Document4 paginiEjemplo Dictamen de La Auditoria 2017mauriciopatinoÎncă nu există evaluări
- Manual AITBDocument7 paginiManual AITBedwin veraÎncă nu există evaluări
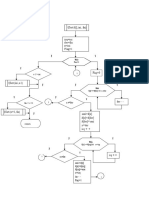
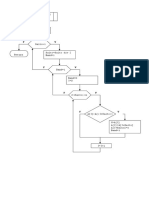
- OrdenRapidaAlgoritmosDocument8 paginiOrdenRapidaAlgoritmosAdrián NúñezÎncă nu există evaluări
- Listas Doblemente EnlazadasDocument11 paginiListas Doblemente EnlazadasHeectoorAlonsoo100% (1)
- Componentes hardware PCDocument4 paginiComponentes hardware PCLic Madelin De la RosaÎncă nu există evaluări
- IP y Puertos Plataforma EPCOM GPSDocument1 paginăIP y Puertos Plataforma EPCOM GPSMarco GonzalezÎncă nu există evaluări
- Ordenar BD ExcelDocument14 paginiOrdenar BD ExcelMilagros Galán BalderaÎncă nu există evaluări
- Paradigmas de ProgramaciónDocument10 paginiParadigmas de ProgramaciónKevvyReyesVasquezÎncă nu există evaluări
- SIMATIC S71200 Manual de SistemaDocument352 paginiSIMATIC S71200 Manual de SistemaJuan MontufarÎncă nu există evaluări
- Reglamento-Ingreso-2023 UNCDocument3 paginiReglamento-Ingreso-2023 UNCLuciana GonzalesÎncă nu există evaluări