S-ar putea să vă placă și
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Log Start4Document1 paginăLog Start4M ZanganaÎncă nu există evaluări
- Log Start4Document1 paginăLog Start4M ZanganaÎncă nu există evaluări
- Standard Test Method For Density, Relative Density (Specific Gravity)Document5 paginiStandard Test Method For Density, Relative Density (Specific Gravity)Mahmood YounsÎncă nu există evaluări
- Mahmood Younis M.Ali 2. Muhammed Abs M.Ali 3. Zaytun Ihsan 4. Veyan Ismail 5. HannaDocument6 paginiMahmood Younis M.Ali 2. Muhammed Abs M.Ali 3. Zaytun Ihsan 4. Veyan Ismail 5. HannaM ZanganaÎncă nu există evaluări
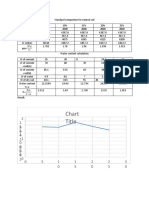
- Chart TitleDocument1 paginăChart TitleM ZanganaÎncă nu există evaluări
- Log Start4Document1 paginăLog Start4M ZanganaÎncă nu există evaluări
- Reinforced Concrete Design: (8th Edition)Document1 paginăReinforced Concrete Design: (8th Edition)M ZanganaÎncă nu există evaluări
- Reinforced Concrete Design: (8th Edition)Document1 paginăReinforced Concrete Design: (8th Edition)M ZanganaÎncă nu există evaluări
- A Report On Truss BridgesDocument16 paginiA Report On Truss BridgesAzaz Ahmed89% (9)
- Reinforced Concrete Design: (8th Edition)Document1 paginăReinforced Concrete Design: (8th Edition)M ZanganaÎncă nu există evaluări
- Autodesk MayaDocument1 paginăAutodesk MayaEnteng Lawrence PinedaÎncă nu există evaluări
- ReportDocument1 paginăReportM ZanganaÎncă nu există evaluări
- Mahmood Younis Muhammed (A) ....Document15 paginiMahmood Younis Muhammed (A) ....M ZanganaÎncă nu există evaluări
- Mahmood Younis Muhammed (A) ....Document15 paginiMahmood Younis Muhammed (A) ....M ZanganaÎncă nu există evaluări
- Generic Array Logic (GAL) (GAL)Document7 paginiGeneric Array Logic (GAL) (GAL)M ZanganaÎncă nu există evaluări
- "Border Irrigation'': University of Kirkuk - College of Engineering Civil Department - Third Stage ADocument9 pagini"Border Irrigation'': University of Kirkuk - College of Engineering Civil Department - Third Stage AM ZanganaÎncă nu există evaluări
- Triaxial Shear Behavior of A Cement-Treated Sand and Gravel MixtureDocument15 paginiTriaxial Shear Behavior of A Cement-Treated Sand and Gravel MixtureM ZanganaÎncă nu există evaluări
- Mahmood Younis Muhammed (A) ....Document15 paginiMahmood Younis Muhammed (A) ....M ZanganaÎncă nu există evaluări
- Triaxial Shear Behavior of A Cement-Treated Sand and Gravel MixtureDocument15 paginiTriaxial Shear Behavior of A Cement-Treated Sand and Gravel MixtureM ZanganaÎncă nu există evaluări
- (A) محمود يونس محمدعليDocument15 pagini(A) محمود يونس محمدعليM ZanganaÎncă nu există evaluări
- Engineering Numerical AnalysisDocument70 paginiEngineering Numerical AnalysisM Zangana100% (1)
- Mahmood Younis Muhammed (A) .Document25 paginiMahmood Younis Muhammed (A) .M ZanganaÎncă nu există evaluări
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- What Motivates Consumers To Review A Product Online? A Study of The Product-Specific Antecedents of Online Movie ReviewsDocument6 paginiWhat Motivates Consumers To Review A Product Online? A Study of The Product-Specific Antecedents of Online Movie ReviewsJason VelazquezÎncă nu există evaluări
- Manual Crystal BallDocument414 paginiManual Crystal Ballcarloshilario100% (1)
- BinomialDocument9 paginiBinomialdeivy ardilaÎncă nu există evaluări
- Biodiversity RDocument85 paginiBiodiversity RrosnimadhuÎncă nu există evaluări
- Probability - Probabilition Distribution Notes by Kristin KuterDocument105 paginiProbability - Probabilition Distribution Notes by Kristin Kutermayank jindalÎncă nu există evaluări
- 2546 PDFDocument2 pagini2546 PDFTessaÎncă nu există evaluări
- Risk Assessment Model For Railway Passengers On A Crowded PlatformDocument8 paginiRisk Assessment Model For Railway Passengers On A Crowded Platformanas syazwanÎncă nu există evaluări
- Short-Term Actuarial Mathematics Exam-October 2018Document8 paginiShort-Term Actuarial Mathematics Exam-October 2018Bryan ChengÎncă nu există evaluări
- PracticeDocument77 paginiPracticeKiyan RoyÎncă nu există evaluări
- PPT3 - Statistical Models in SimulationDocument38 paginiPPT3 - Statistical Models in SimulationRizky AmandaÎncă nu există evaluări
- Safety-Based Left-Turn Phasing Decisions For Signalized IntersectionsDocument7 paginiSafety-Based Left-Turn Phasing Decisions For Signalized Intersectionsamelinda jocelinÎncă nu există evaluări
- Structure of University Examination Question Paper (Total Marks: 70:: Time: 3 Hours)Document39 paginiStructure of University Examination Question Paper (Total Marks: 70:: Time: 3 Hours)chthakorÎncă nu există evaluări
- 2.5 the Negative Binomial Distribution 習題Document2 pagini2.5 the Negative Binomial Distribution 習題sandywu930510Încă nu există evaluări
- MaherDocument10 paginiMaherdrb7907Încă nu există evaluări
- Discrete Random VariablesDocument15 paginiDiscrete Random VariableskentigernkÎncă nu există evaluări
- Discrete Probability ModelsDocument19 paginiDiscrete Probability Modelsrashi jainÎncă nu există evaluări
- STA222 Week7Document14 paginiSTA222 Week7Kimondo KingÎncă nu există evaluări
- Random Processes Ma1254Document17 paginiRandom Processes Ma1254Surya Kumar MaranÎncă nu există evaluări
- GSL ManualDocument589 paginiGSL ManualDebankur DasÎncă nu există evaluări
- Calibration of A Jump Di FussionDocument28 paginiCalibration of A Jump Di Fussionmirando93Încă nu există evaluări
- Count Data Models in SASDocument12 paginiCount Data Models in SASAlvaro ZapataÎncă nu există evaluări
- Solution Manual For Introduction To Statistical Quality Control 7th Ed - Douglas MontgomeryDocument20 paginiSolution Manual For Introduction To Statistical Quality Control 7th Ed - Douglas MontgomeryMohammed Saad0% (3)
- Orange Data Mining - Random DataDocument8 paginiOrange Data Mining - Random DataWilhelminaÎncă nu există evaluări
- Intermittent Demand Forecasting Context Methods and Applications 1St Edition Aris A Syntetos Full ChapterDocument67 paginiIntermittent Demand Forecasting Context Methods and Applications 1St Edition Aris A Syntetos Full Chapterfrank.hayes323Încă nu există evaluări
- Are Zero Inflated Distributions Compulsory in The Presence of Zero InflationDocument4 paginiAre Zero Inflated Distributions Compulsory in The Presence of Zero InflationInternational Journal of Innovative Science and Research TechnologyÎncă nu există evaluări
- Research Methods in Economics Part II STATDocument350 paginiResearch Methods in Economics Part II STATsimbiroÎncă nu există evaluări
- Discrete Random Variables and Probability DistributionsDocument56 paginiDiscrete Random Variables and Probability DistributionsBui Tien DatÎncă nu există evaluări
- Stat 509 NotesDocument195 paginiStat 509 NotesJon100% (1)
- MTH262 - Statistics & Probability Theory by Dr. Riffat JabeenDocument5 paginiMTH262 - Statistics & Probability Theory by Dr. Riffat JabeenUsama Butt0% (1)
- Complete Business Statistics-Chapter 3Document9 paginiComplete Business Statistics-Chapter 3krishnadeep_gupta401840% (5)