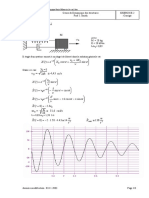
S-ar putea să vă placă și
- Recueil D'exercices en Traitement Du Signal Janvier 2019Document27 paginiRecueil D'exercices en Traitement Du Signal Janvier 2019Yassmina100% (3)
- Chapitre 2Document13 paginiChapitre 2Mohamed EL hadegÎncă nu există evaluări
- 2 Regret 1Document15 pagini2 Regret 1Ignée FleurÎncă nu există evaluări
- Klubprepa Extrait 7305Document2 paginiKlubprepa Extrait 7305chaddad abdllahÎncă nu există evaluări
- 3 BoltzmannDocument12 pagini3 BoltzmannIgnée FleurÎncă nu există evaluări
- Tous Les TDsDocument45 paginiTous Les TDsAnonymous OBqZaPGN5Încă nu există evaluări
- Correction TD 3Document5 paginiCorrection TD 3عبداللهبنزنوÎncă nu există evaluări
- TD6 PS Cor 13Document5 paginiTD6 PS Cor 13soniaÎncă nu există evaluări
- TP 5 MODELISATION DE Lâ ™ACTION Dâ ™UN RESSORTDocument2 paginiTP 5 MODELISATION DE Lâ ™ACTION Dâ ™UN RESSORTAmi NaÎncă nu există evaluări
- Concours Blanc 9Document5 paginiConcours Blanc 9Abena Bala Marc-LoïcÎncă nu există evaluări
- PH5 (Oscillations Mécaniques Libres)Document13 paginiPH5 (Oscillations Mécaniques Libres)Seif Souid87% (30)
- TP TS 1Document6 paginiTP TS 1sele16748Încă nu există evaluări
- Cours PROBA Licence ProDocument19 paginiCours PROBA Licence Pronadia n'guessanÎncă nu există evaluări
- Cours - Vibrations 18 02 2021Document6 paginiCours - Vibrations 18 02 2021Med Raslene AlouiÎncă nu există evaluări
- Examen Final - Corrigé - Phys04 - 2020-21 - ESSAT PDFDocument5 paginiExamen Final - Corrigé - Phys04 - 2020-21 - ESSAT PDFHou HouÎncă nu există evaluări
- CorrigeRattrapage17 18 BerradaDocument4 paginiCorrigeRattrapage17 18 BerradaAwatif BeÎncă nu există evaluări
- Banach SteinhausDocument4 paginiBanach SteinhausfocusssmodeÎncă nu există evaluări
- TD Commun TX NumDocument16 paginiTD Commun TX NumMahdi KachouriÎncă nu există evaluări
- MAT1A examenPS Janv2018Document2 paginiMAT1A examenPS Janv2018Ghada AmakraneÎncă nu există evaluări
- CC 0 A 96087 Ab 4 Be 1 DCDDocument13 paginiCC 0 A 96087 Ab 4 Be 1 DCDChaouki SaidiÎncă nu există evaluări
- Signaux NumeriquesDocument4 paginiSignaux NumeriquesAmine AlaouiÎncă nu există evaluări
- PC 9: Intervalles de ConfianceDocument5 paginiPC 9: Intervalles de ConfianceMer YemÎncă nu există evaluări
- Concours Blanc 4Document3 paginiConcours Blanc 4Abena Bala Marc-LoïcÎncă nu există evaluări
- Chap 1Document8 paginiChap 1docteurgynecoÎncă nu există evaluări
- TD Tns m1 PDFDocument40 paginiTD Tns m1 PDFAboubacryÎncă nu există evaluări
- CM AcoustiqueDocument72 paginiCM AcoustiqueNabila HamlilÎncă nu există evaluări
- EstimationSTT2700h17 PDFDocument33 paginiEstimationSTT2700h17 PDFalfredÎncă nu există evaluări
- 16équations Differentielles Exercices Corrigés 02Document6 pagini16équations Differentielles Exercices Corrigés 02koruko basketÎncă nu există evaluări
- Corr - DM nc2b02 de Thermo StatDocument2 paginiCorr - DM nc2b02 de Thermo StatGhita BousfihaÎncă nu există evaluări
- TD Tns m1 CorrDocument43 paginiTD Tns m1 Corrjuniortass01Încă nu există evaluări
- BinomDocument4 paginiBinomPitchou RyanÎncă nu există evaluări
- Non Rajchman MeasuresDocument4 paginiNon Rajchman MeasuresBoutet de Monvel JacquesÎncă nu există evaluări
- Correction TD1Document4 paginiCorrection TD1elios.goujotÎncă nu există evaluări
- Edo90 Exaj CorDocument4 paginiEdo90 Exaj CorChabane MohamedÎncă nu există evaluări
- Edo90 Exaj Cor - MergedDocument27 paginiEdo90 Exaj Cor - MergedChabane MohamedÎncă nu există evaluări
- Ds Maths MPSIDocument2 paginiDs Maths MPSIEL Barkany MohammedÎncă nu există evaluări
- TD 2 CorrigeDocument6 paginiTD 2 Corrigeamrane mounirÎncă nu există evaluări
- TDMAT221S1Document4 paginiTDMAT221S1nimbeyeemmanuelÎncă nu există evaluări
- Cours6 Eqchal ResolDocument19 paginiCours6 Eqchal ResolKader MilanoÎncă nu există evaluări
- ExamenIF CorrigeDocument2 paginiExamenIF CorrigeSADOKÎncă nu există evaluări
- Synth 1718Document3 paginiSynth 1718Youssra DjeÎncă nu există evaluări
- Devoir SB2Document2 paginiDevoir SB2ouedraogodri2016Încă nu există evaluări
- Corrige Devoir 13Document6 paginiCorrige Devoir 13Mohamed GarmoumÎncă nu există evaluări
- TP EchantillonageDocument3 paginiTP Echantillonagezazazaz2000Încă nu există evaluări
- Probabilités TD2 ECDocument7 paginiProbabilités TD2 ECabidm2645Încă nu există evaluări
- TD Tns m1Document19 paginiTD Tns m1Ayoub AhrirÎncă nu există evaluări
- ArmaDocument60 paginiArmaOtmane HamdaniÎncă nu există evaluări
- Examen S2 2011 2012 RattDocument3 paginiExamen S2 2011 2012 RattAmir HamzaÎncă nu există evaluări
- Sigma Produit Binôme de Newton...Document5 paginiSigma Produit Binôme de Newton...Hamada NadiÎncă nu există evaluări
- Centrale 2019 MP M2 CorrigeDocument9 paginiCentrale 2019 MP M2 CorrigeAhzen's AbÎncă nu există evaluări
- ds2022 01 15Document3 paginids2022 01 15arno.boulardÎncă nu există evaluări
- corrigeMG S1 1920Document5 paginicorrigeMG S1 1920Hamza SadikÎncă nu există evaluări
- Kholles MathDocument18 paginiKholles MathPiè CoulibalyÎncă nu există evaluări
- Examen 2017Document3 paginiExamen 2017ethan cohenÎncă nu există evaluări
- EXERCICE 23.1-: Phenomenes de TransfertDocument2 paginiEXERCICE 23.1-: Phenomenes de TransfertMohamed Es-sedratyÎncă nu există evaluări
- Sol-Devoir 3Document2 paginiSol-Devoir 3Jï JîÎncă nu există evaluări
- Exercice2a Cor2Document3 paginiExercice2a Cor2سيدة ام رهامÎncă nu există evaluări
- Équations différentielles: Les Grands Articles d'UniversalisDe la EverandÉquations différentielles: Les Grands Articles d'UniversalisÎncă nu există evaluări
- Ref Forma BTS Compta GestionDocument64 paginiRef Forma BTS Compta Gestionmor ndiayeÎncă nu există evaluări
- Les IdentificateursDocument24 paginiLes Identificateursmor ndiayeÎncă nu există evaluări
- Redaction Administrative.2016Document126 paginiRedaction Administrative.2016mor ndiaye100% (1)
- Pointeurs Sur FonctionsDocument19 paginiPointeurs Sur Fonctionsmor ndiayeÎncă nu există evaluări
- Cours 1 - PrésentationDocument67 paginiCours 1 - Présentationmor ndiayeÎncă nu există evaluări
- Cours 3 - Appel de ProcédureDocument66 paginiCours 3 - Appel de Procéduremor ndiayeÎncă nu există evaluări
- Cours 4 - Intergiciel À MessageDocument39 paginiCours 4 - Intergiciel À Messagemor ndiayeÎncă nu există evaluări
- Cours 5 - Tolérance Aux FautesDocument44 paginiCours 5 - Tolérance Aux Fautesmor ndiayeÎncă nu există evaluări
- Cours 1 - IntroductionDocument15 paginiCours 1 - Introductionmor ndiayeÎncă nu există evaluări
- BacktrackingDocument19 paginiBacktrackingmor ndiayeÎncă nu există evaluări
- Logique Floue PDFDocument23 paginiLogique Floue PDFmor ndiayeÎncă nu există evaluări
- Algorithmes D'apprentissage Par Renforcement PDFDocument13 paginiAlgorithmes D'apprentissage Par Renforcement PDFmor ndiayeÎncă nu există evaluări
- Cours Mathématique Statistique2Document37 paginiCours Mathématique Statistique2naoual baghliÎncă nu există evaluări
- TD 6 MagDocument5 paginiTD 6 MagNAIBE DONGSOÎncă nu există evaluări
- BLPC N°009 (1964) - Introduction Au Raisonnement Statistique - BonitzerDocument8 paginiBLPC N°009 (1964) - Introduction Au Raisonnement Statistique - BonitzerAntoine PhilippeÎncă nu există evaluări
- COLLETAZ Series Temporelles Multivariees - MaJ 2020Document2 paginiCOLLETAZ Series Temporelles Multivariees - MaJ 2020Septimus PierreÎncă nu există evaluări
- Probas 6Document37 paginiProbas 6Rajae ChainabouÎncă nu există evaluări
- Cours Theorie Du RisqueDocument42 paginiCours Theorie Du RisqueGeorges A. K. BANNERMANÎncă nu există evaluări
- Cours Complet 2020 PDFDocument505 paginiCours Complet 2020 PDFÇhéîmæ100% (1)
- BayesDocument144 paginiBayessibiri gregoire ouedraogoÎncă nu există evaluări
- Stat2 ProbDocument23 paginiStat2 Probnaya.messaoudeneÎncă nu există evaluări
- Chapitre 3 - CointegrationDocument18 paginiChapitre 3 - CointegrationsambaÎncă nu există evaluări
- TD1 Biostatistique L2!19!20Document2 paginiTD1 Biostatistique L2!19!20didineÎncă nu există evaluări
- Série 1 TD Econométrie 3LSG FIN 2021 2020Document1 paginăSérie 1 TD Econométrie 3LSG FIN 2021 2020benayed oussema100% (1)
- RLMDocument6 paginiRLMČhAzoû Nâ-JîîÎncă nu există evaluări
- Chapitre 4 Copule Et Risque Multiples en Assurance PDFDocument35 paginiChapitre 4 Copule Et Risque Multiples en Assurance PDFschadrac75Încă nu există evaluări
- Test Stat RDocument54 paginiTest Stat RYAMEOGOÎncă nu există evaluări
- Tableaux LoisDocument6 paginiTableaux Loissakhir sarrÎncă nu există evaluări
- Chekima RomayssaDocument65 paginiChekima RomayssaluluÎncă nu există evaluări
- Corrige5-Ajust Et IC-Prop-MoyDocument5 paginiCorrige5-Ajust Et IC-Prop-MoyMamadou Moustapha NdiayeÎncă nu există evaluări
- Analyses de Données Master-1Document39 paginiAnalyses de Données Master-1pm.ndourÎncă nu există evaluări
- Gltco 122Document53 paginiGltco 122darrenmbomÎncă nu există evaluări
- Notes Cochran QDocument7 paginiNotes Cochran Qhubik38Încă nu există evaluări
- Cha Ines de Markov 2: Table Des Mati' EresDocument7 paginiCha Ines de Markov 2: Table Des Mati' EresCyrille LamasséÎncă nu există evaluări
- c1 PDFDocument60 paginic1 PDFTahiri MehdiÎncă nu există evaluări
- Cours Processus Et Calcul StochastiqueDocument79 paginiCours Processus Et Calcul StochastiqueFatima RafiiÎncă nu există evaluări
- Exercices Stat InferentielleDocument11 paginiExercices Stat InferentiellesjaubertÎncă nu există evaluări
- Chapitre 11Document22 paginiChapitre 11atika kabouyaÎncă nu există evaluări
- Cours STT3220 Goldfeld QuandtDocument6 paginiCours STT3220 Goldfeld QuandtFATEN BENNACEURÎncă nu există evaluări
- Formulaire Statistique InferentielleDocument8 paginiFormulaire Statistique InferentielleNeoXana01100% (1)
- Examen StatDec-AU1718Document1 paginăExamen StatDec-AU1718DOAA AL GHAZALIÎncă nu există evaluări