S-ar putea să vă placă și
- DBMS NotesDocument43 paginiDBMS Notesjitendrabudholiya620Încă nu există evaluări
- Unit 1 - Database Management Systems - WWW - Rgpvnotes.inDocument21 paginiUnit 1 - Database Management Systems - WWW - Rgpvnotes.inZyter MathuÎncă nu există evaluări
- Dbms NotesDocument71 paginiDbms Notessanyasirao182% (11)
- CS502 DBMS Notes Unit 1Document19 paginiCS502 DBMS Notes Unit 1Yadu PatidarÎncă nu există evaluări
- Database Management: 1 - Computer ApplicationsDocument7 paginiDatabase Management: 1 - Computer ApplicationsTino AlappatÎncă nu există evaluări
- Lecture Notes 1 PDFDocument4 paginiLecture Notes 1 PDFVignesh ChanthirasekarÎncă nu există evaluări
- Database Unit-1 NotesDocument13 paginiDatabase Unit-1 NotespthepronabÎncă nu există evaluări
- Unit - 1Document14 paginiUnit - 1JAYPALSINH GOHILÎncă nu există evaluări
- Introduction To Database SystemDocument12 paginiIntroduction To Database SystemJulfikar asifÎncă nu există evaluări
- RDBMS Unit1Document15 paginiRDBMS Unit1maniking9346Încă nu există evaluări
- DBMS Lec 1 + 2Document22 paginiDBMS Lec 1 + 2معتز العجيليÎncă nu există evaluări
- Chapter 1 Introduction To DBMS PDFDocument6 paginiChapter 1 Introduction To DBMS PDFVidhyaÎncă nu există evaluări
- 1 IntroductionDocument87 pagini1 IntroductionAnu SreeÎncă nu există evaluări
- Syllabus Data Base Management System: Unit-IDocument64 paginiSyllabus Data Base Management System: Unit-IAnonymous 26fLU3lÎncă nu există evaluări
- Dbms Notes by Bipul Kumar Yadav - 1581657091 PDFDocument121 paginiDbms Notes by Bipul Kumar Yadav - 1581657091 PDFArpoxonÎncă nu există evaluări
- DBMS Complete Note PDFDocument130 paginiDBMS Complete Note PDFSarwesh MaharzanÎncă nu există evaluări
- DBMS Notes by DinudineshDocument18 paginiDBMS Notes by DinudineshBhargav NaiduÎncă nu există evaluări
- Introduction To Database Management System-NotesDocument46 paginiIntroduction To Database Management System-Notesdurgagarg10051998Încă nu există evaluări
- Ankit Sir All Units DbmsDocument142 paginiAnkit Sir All Units Dbmssageranimesh20100% (1)
- Q Define Database, Data, DBMS, State Purpose of DatabaseDocument20 paginiQ Define Database, Data, DBMS, State Purpose of Databasenaresh sainiÎncă nu există evaluări
- DBDM 16 Marks All 5 UnitsDocument74 paginiDBDM 16 Marks All 5 Unitsathirayan85Încă nu există evaluări
- Unit1 CSEDocument16 paginiUnit1 CSEShagun PandeyÎncă nu există evaluări
- Database Design Concepts Introduction NotesDocument42 paginiDatabase Design Concepts Introduction NotesmunatsiÎncă nu există evaluări
- Slides Rdbms 1Document76 paginiSlides Rdbms 1Pavan KumarÎncă nu există evaluări
- Unit - 1 Introduction To Database Management SystemDocument20 paginiUnit - 1 Introduction To Database Management Systemhabib0999Încă nu există evaluări
- DBMS - QUESTION BANK With Answer TIEDocument56 paginiDBMS - QUESTION BANK With Answer TIESushmith Shettigar100% (3)
- Com 312 Lecture Notes2010Document49 paginiCom 312 Lecture Notes2010Oladele Campbell100% (9)
- FDBMSDocument26 paginiFDBMSsurendraÎncă nu există evaluări
- 1 - Introductory Concepts of DBMS: Define The Following TermsDocument133 pagini1 - Introductory Concepts of DBMS: Define The Following Termsronaldo magarÎncă nu există evaluări
- Unit-01 IntroductionDocument7 paginiUnit-01 IntroductionJINESH VARIAÎncă nu există evaluări
- E Notes PDF All UnitsDocument129 paginiE Notes PDF All Unitsshreya sorathiaÎncă nu există evaluări
- Unit-1 Introduction: Define The Following TermsDocument10 paginiUnit-1 Introduction: Define The Following TermsVirat KohliÎncă nu există evaluări
- DBMS BasicsDocument32 paginiDBMS BasicsAnime RespectÎncă nu există evaluări
- Rdbms (Unit 1)Document13 paginiRdbms (Unit 1)hari karanÎncă nu există evaluări
- DBMS GTU Study Material E-Notes All-Units 17102019083450AMDocument142 paginiDBMS GTU Study Material E-Notes All-Units 17102019083450AMrambabuÎncă nu există evaluări
- Dbms Assignment-1Document8 paginiDbms Assignment-1Bharat MalikÎncă nu există evaluări
- DBMS Unit IDocument30 paginiDBMS Unit IAnubhav GuptaÎncă nu există evaluări
- Database Concepts For MBADocument49 paginiDatabase Concepts For MBARaveena NaiduÎncă nu există evaluări
- Introduction To Database Management SystemDocument47 paginiIntroduction To Database Management SystemjisskuruvillaÎncă nu există evaluări
- Unit 1Document11 paginiUnit 1Anand GuptaÎncă nu există evaluări
- What Is Data Redundancy and InconsistencyDocument3 paginiWhat Is Data Redundancy and InconsistencyPalani_Kumar_924100% (2)
- Database System by Udaya R. DhunganaDocument13 paginiDatabase System by Udaya R. DhunganaurdurÎncă nu există evaluări
- Dbms Seperate NotesDocument74 paginiDbms Seperate NotesRupith Kumar .NÎncă nu există evaluări
- Unit 1 FullDocument126 paginiUnit 1 FullNikhil kumar ChandnaniÎncă nu există evaluări
- 1 8 Database and Data ModellingDocument6 pagini1 8 Database and Data ModellingnelisappawandiwaÎncă nu există evaluări
- DMS MicroprojectDocument13 paginiDMS MicroprojectRushi MemaneÎncă nu există evaluări
- CUAP DBMS Notes Unit11Document31 paginiCUAP DBMS Notes Unit11sahil rajÎncă nu există evaluări
- DBMS Class1Document15 paginiDBMS Class1sangeetha sheelaÎncă nu există evaluări
- Databases & CRMDocument12 paginiDatabases & CRMvaishalicÎncă nu există evaluări
- Database Management SystemsDocument191 paginiDatabase Management SystemsGangaa Shelvi100% (1)
- DBMS 2Document7 paginiDBMS 2Sha MatÎncă nu există evaluări
- BSC CsIt Complete RDBMS NotesDocument86 paginiBSC CsIt Complete RDBMS NotesNilesh GoteÎncă nu există evaluări
- Unit 1Document21 paginiUnit 123mca006Încă nu există evaluări
- DBMS Complete Notes - 0 (1) - OrganizedDocument120 paginiDBMS Complete Notes - 0 (1) - Organizedjerin joshyÎncă nu există evaluări
- Intro To DBMSDocument22 paginiIntro To DBMSapi-27570914100% (1)
- Dbms 1&2Document15 paginiDbms 1&2aswinsai615Încă nu există evaluări
- F - Edit - Chapter 1Document18 paginiF - Edit - Chapter 1asanajasimaÎncă nu există evaluări
- Assignment Help WEB DESIGN PDFDocument45 paginiAssignment Help WEB DESIGN PDFKapil PokhrelÎncă nu există evaluări
- Sql-Lab 3 DML PDFDocument4 paginiSql-Lab 3 DML PDFKapil PokhrelÎncă nu există evaluări
- 1.introduction To Basic SQL Queries: 1. Login To Mysql Shell For User Root (Ubuntu)Document4 pagini1.introduction To Basic SQL Queries: 1. Login To Mysql Shell For User Root (Ubuntu)Kapil PokhrelÎncă nu există evaluări
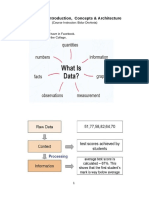
- Database: Introduction, Concepts & ArchitectureDocument32 paginiDatabase: Introduction, Concepts & ArchitectureKapil PokhrelÎncă nu există evaluări
- 07 Introduction To JavaScriptDocument30 pagini07 Introduction To JavaScriptKapil PokhrelÎncă nu există evaluări
- Data Definition Language (DDL)Document5 paginiData Definition Language (DDL)Kapil PokhrelÎncă nu există evaluări
- FilmmDocument1 paginăFilmmKapil PokhrelÎncă nu există evaluări
- 04 Responsive Web DesignDocument20 pagini04 Responsive Web DesignKapil PokhrelÎncă nu există evaluări
- Asia Pacific University of Technology and Innovation (APU) Page 1 of 3Document3 paginiAsia Pacific University of Technology and Innovation (APU) Page 1 of 3Kapil Pokhrel50% (2)
- CT053-3-1 Fundamentals of Web Design and DevelopmentDocument10 paginiCT053-3-1 Fundamentals of Web Design and DevelopmentKapil PokhrelÎncă nu există evaluări
- 01 Client Server Architecture + Web HostingDocument23 pagini01 Client Server Architecture + Web HostingKapil PokhrelÎncă nu există evaluări
- CITW Exam TipsDocument2 paginiCITW Exam TipsSreePrakashÎncă nu există evaluări
- HTML With JavascriptDocument24 paginiHTML With JavascriptKapil PokhrelÎncă nu există evaluări
- Assignment: (Module Code) (Module Name)Document1 paginăAssignment: (Module Code) (Module Name)Kapil PokhrelÎncă nu există evaluări
- C Programming Assignment Washing Machine SystemDocument40 paginiC Programming Assignment Washing Machine SystemAli Reza Yassi81% (32)
- Duration: 30 Minutes Answer All Questions. Each Question Carries 5 MarksDocument2 paginiDuration: 30 Minutes Answer All Questions. Each Question Carries 5 MarksKapil PokhrelÎncă nu există evaluări
- Section A (20 Marks) Answer All Questions QUESTION A1 (4 Marks)Document2 paginiSection A (20 Marks) Answer All Questions QUESTION A1 (4 Marks)Kapil PokhrelÎncă nu există evaluări
- What Is IsDocument1 paginăWhat Is IsKapil PokhrelÎncă nu există evaluări
- BBBCDocument1 paginăBBBCKapil PokhrelÎncă nu există evaluări
- Duration: 20 Minutes Answer ALL Questions. Please Fill in Your Answers in The Table Provided. Question No. 1 2 3 4 5 6 7 Marks 2 1 2 2 1 1 1 AnswerDocument2 paginiDuration: 20 Minutes Answer ALL Questions. Please Fill in Your Answers in The Table Provided. Question No. 1 2 3 4 5 6 7 Marks 2 1 2 2 1 1 1 AnswerKapil PokhrelÎncă nu există evaluări
- Introduction To Management (BM007-3-1-ITM) AssignmentDocument9 paginiIntroduction To Management (BM007-3-1-ITM) AssignmentCk VinÎncă nu există evaluări
- Introduction To Management (BM007-3-1-ITM) AssignmentDocument9 paginiIntroduction To Management (BM007-3-1-ITM) AssignmentCk VinÎncă nu există evaluări
- Leave Management System: Radha Govind Group of InstitutionDocument71 paginiLeave Management System: Radha Govind Group of InstitutionNamdev shivaniÎncă nu există evaluări
- Duration: 20 Minutes Answer ALL Questions. Please Fill in Your Answers in The Table Provided. Question No. 1 2 3 4 5 Marks 2 2 2 2 2 AnswerDocument1 paginăDuration: 20 Minutes Answer ALL Questions. Please Fill in Your Answers in The Table Provided. Question No. 1 2 3 4 5 Marks 2 2 2 2 2 AnswerKapil PokhrelÎncă nu există evaluări
- Introduction To C Programming AssignmentDocument14 paginiIntroduction To C Programming AssignmentSreePrakash100% (2)
- Duration: 30 Minutes Answer All Questions. Each Question Carries 5 MarksDocument2 paginiDuration: 30 Minutes Answer All Questions. Each Question Carries 5 MarksKapil PokhrelÎncă nu există evaluări
- Test (Q) - CoverDocument1 paginăTest (Q) - CoverKapil PokhrelÎncă nu există evaluări
- Duration: 30 Minutes Answer All Questions. Each Question Carries 5 MarksDocument2 paginiDuration: 30 Minutes Answer All Questions. Each Question Carries 5 MarksKapil PokhrelÎncă nu există evaluări
- Test (Q) - CoverDocument1 paginăTest (Q) - CoverKapil PokhrelÎncă nu există evaluări
- PH Scale: Rules of PH ValueDocument6 paginiPH Scale: Rules of PH Valuemadhurirathi111Încă nu există evaluări
- Spaces For Conflict and ControversiesDocument5 paginiSpaces For Conflict and ControversiesVistalÎncă nu există evaluări
- The Role of Religion in The Causation of Global Conflict & Peace and Other Related Issues Regarding Conflict ResolutionDocument11 paginiThe Role of Religion in The Causation of Global Conflict & Peace and Other Related Issues Regarding Conflict ResolutionlorenÎncă nu există evaluări
- Snap Fasteners For Clothes-Snap Fasteners For Clothes Manufacturers, Suppliers and Exporters On Alibaba - ComapparelDocument7 paginiSnap Fasteners For Clothes-Snap Fasteners For Clothes Manufacturers, Suppliers and Exporters On Alibaba - ComapparelLucky ParasharÎncă nu există evaluări
- PT3 Liste PDFDocument2 paginiPT3 Liste PDFSiti KamalÎncă nu există evaluări
- Bhaja Govindham LyricsDocument9 paginiBhaja Govindham LyricssydnaxÎncă nu există evaluări
- Simple FTP UploadDocument10 paginiSimple FTP Uploadagamem1Încă nu există evaluări
- Text Mohamed AliDocument2 paginiText Mohamed AliARYAJAI SINGHÎncă nu există evaluări
- Bed BathDocument6 paginiBed BathKristil ChavezÎncă nu există evaluări
- Due Date: 29-12-2021: Fall 2021 MTH104: Sets and Logic Assignment No. 1 (Lectures # 16 To 18) Total Marks: 10Document3 paginiDue Date: 29-12-2021: Fall 2021 MTH104: Sets and Logic Assignment No. 1 (Lectures # 16 To 18) Total Marks: 10manzoor ahmadÎncă nu există evaluări
- Sokkia GRX3Document4 paginiSokkia GRX3Muhammad Afran TitoÎncă nu există evaluări
- History of Architecture VI: Unit 1Document20 paginiHistory of Architecture VI: Unit 1Srehari100% (1)
- 130004-1991-Maceda v. Energy Regulatory BoardDocument14 pagini130004-1991-Maceda v. Energy Regulatory BoardChristian VillarÎncă nu există evaluări
- Aar604 Lecture 3Document55 paginiAar604 Lecture 3Azizul100% (1)
- Research Methods in Accounting & Finance Chapter 5Document27 paginiResearch Methods in Accounting & Finance Chapter 5bikilahussenÎncă nu există evaluări
- Math 3140-004: Vector Calculus and PdesDocument6 paginiMath 3140-004: Vector Calculus and PdesNathan MonsonÎncă nu există evaluări
- 11-03-25 PRESS RELEASE: The Riddle of Citizens United V Federal Election Commission... The Missing February 22, 2010 Judgment...Document2 pagini11-03-25 PRESS RELEASE: The Riddle of Citizens United V Federal Election Commission... The Missing February 22, 2010 Judgment...Human Rights Alert - NGO (RA)Încă nu există evaluări
- Romeuf Et Al., 1995Document18 paginiRomeuf Et Al., 1995David Montaño CoronelÎncă nu există evaluări
- Strength Exp 2 Brinell Hardness TestDocument13 paginiStrength Exp 2 Brinell Hardness Testhayder alaliÎncă nu există evaluări
- How To Play Casino - Card Game RulesDocument1 paginăHow To Play Casino - Card Game RulesNouka VEÎncă nu există evaluări
- Due Books List ECEDocument3 paginiDue Books List ECEMadhumithaÎncă nu există evaluări
- Social Studies 5th Grade Georgia StandardsDocument6 paginiSocial Studies 5th Grade Georgia Standardsapi-366462849Încă nu există evaluări
- Atividade de InglêsDocument8 paginiAtividade de InglêsGabriel FreitasÎncă nu există evaluări
- CLEMENTE CALDE vs. THE COURT OF APPEALSDocument1 paginăCLEMENTE CALDE vs. THE COURT OF APPEALSDanyÎncă nu există evaluări
- Pr1 m4 Identifying The Inquiry and Stating The ProblemDocument61 paginiPr1 m4 Identifying The Inquiry and Stating The ProblemaachecheutautautaÎncă nu există evaluări
- Waa Sik Arene & Few Feast Wis (FHT CHT Ste1) - Tifa AieaDocument62 paginiWaa Sik Arene & Few Feast Wis (FHT CHT Ste1) - Tifa AieaSrujhana RaoÎncă nu există evaluări
- How To Format Your Business ProposalDocument2 paginiHow To Format Your Business Proposalwilly sergeÎncă nu există evaluări
- Section 9 - Brickwork and BlockworkDocument6 paginiSection 9 - Brickwork and BlockworkShing Faat WongÎncă nu există evaluări
- Chapter 8 Supplier Quality ManagementDocument71 paginiChapter 8 Supplier Quality ManagementAnh NguyenÎncă nu există evaluări
- THM07 Module 2 The Tourist Market and SegmentationDocument14 paginiTHM07 Module 2 The Tourist Market and Segmentationjennifer mirandaÎncă nu există evaluări