S-ar putea să vă placă și
- Operaciones Proposicionales y Lenguaje Formal - ActividadDocument8 paginiOperaciones Proposicionales y Lenguaje Formal - ActividadDiego OrozcoÎncă nu există evaluări
- Manual POS AdminDocument664 paginiManual POS Adminmarlonjcc1100% (1)
- PISOSDocument44 paginiPISOSLLakelyne Rojas100% (1)
- Seminario de Tesis II TextoDocument54 paginiSeminario de Tesis II TextoAlvaro CastroÎncă nu există evaluări
- Ingenieria Por Metodos Semana 3Document6 paginiIngenieria Por Metodos Semana 3danilo acostaÎncă nu există evaluări
- Buses Datos y Bus Dir Calcula Tamaño MemoriaDocument10 paginiBuses Datos y Bus Dir Calcula Tamaño MemoriacarlosÎncă nu există evaluări
- Distribución Chi Cuadrado XXDocument3 paginiDistribución Chi Cuadrado XXConi RSÎncă nu există evaluări
- IV FIN 110 TE Valenzuela Buendia 2020Document111 paginiIV FIN 110 TE Valenzuela Buendia 2020Taykui Kuren HmÎncă nu există evaluări
- Ley de CorteDocument21 paginiLey de CorteJose Rodriguez Chavez100% (1)
- New 01 Conde, J. (2018) Teoria de ErroresDocument7 paginiNew 01 Conde, J. (2018) Teoria de ErroresViri YseyÎncă nu există evaluări
- El Método de Proyectos Como Técnica DidácticaDocument9 paginiEl Método de Proyectos Como Técnica DidácticaMerly RiosÎncă nu există evaluări
- Cuestionario-Satisfacción-Usuario - Cálculo de La Confiabilidad Con El Alfa de CronbachDocument15 paginiCuestionario-Satisfacción-Usuario - Cálculo de La Confiabilidad Con El Alfa de Cronbachemigdio_alfaro9892Încă nu există evaluări
- Proceso de Investigación AdministrativaDocument13 paginiProceso de Investigación AdministrativaLeonela MoscatiniÎncă nu există evaluări
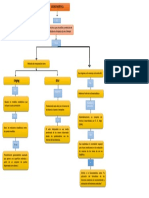
- Mapa ConceptualDocument1 paginăMapa Conceptualtereza navarroÎncă nu există evaluări
- Examen Parcial de Análisis Computacional de Sistemas MinerosDocument5 paginiExamen Parcial de Análisis Computacional de Sistemas MinerosBENJAMIN CHIHUANTITO KCANAÎncă nu există evaluări
- SupuestosDocument5 paginiSupuestosElizabeth isnÎncă nu există evaluări
- Grupo 2 - Foro 6 PDFDocument18 paginiGrupo 2 - Foro 6 PDFGuillermo Quispe HuallpaÎncă nu există evaluări
- Conceptos y Definiciones de Planificación MineraDocument32 paginiConceptos y Definiciones de Planificación Mineraguiampu313050% (2)
- Sustentación Del Modelo - Regresión Lineal Múltiple MINERIADocument9 paginiSustentación Del Modelo - Regresión Lineal Múltiple MINERIAphoenix eastwoodÎncă nu există evaluări
- Reporte Bhpbilliton BajoDocument88 paginiReporte Bhpbilliton BajoClaudio Esteban Picón100% (1)
- LOS ESTUDIOS DE VIABILIDAD EN EL DESARROLLO DE LOS PROYECTOS MINEROS TrabajoDocument15 paginiLOS ESTUDIOS DE VIABILIDAD EN EL DESARROLLO DE LOS PROYECTOS MINEROS TrabajoAlex SantaCruz HernandezÎncă nu există evaluări
- Apuntes Trabajos de Titulación PDFDocument240 paginiApuntes Trabajos de Titulación PDFJerson Mendoza JilerÎncă nu există evaluări
- Chi CuadradoDocument4 paginiChi CuadradoJavier MoyaÎncă nu există evaluări
- Cap III - El Método Científico y Sus Etapas de ConcreciónDocument28 paginiCap III - El Método Científico y Sus Etapas de ConcreciónMulaÎncă nu există evaluări
- Taller Microeconomia 25% Jhon Alexander Jimenez RiveraDocument19 paginiTaller Microeconomia 25% Jhon Alexander Jimenez RiveraJhon Alexander Jimenez RiveraÎncă nu există evaluări
- Esfuerzo y DeformaciónDocument2 paginiEsfuerzo y DeformaciónxhunaÎncă nu există evaluări
- U2 Act2 Variabilidad GNPGDocument10 paginiU2 Act2 Variabilidad GNPGGloria NohemíÎncă nu există evaluări
- Exploración Por Depósitos Epitermales de Oro: January 2000Document44 paginiExploración Por Depósitos Epitermales de Oro: January 2000Juan Jaime TAIPE RODRIGUEZÎncă nu există evaluări
- GEOVIA Surpac + Informacion Relevante + ConclusionDocument5 paginiGEOVIA Surpac + Informacion Relevante + ConclusionNanni ReyesÎncă nu există evaluări
- ¿Cuáles Son Las Consideraciones Básicas para Elegir Un Tema y LevantamientoDocument3 pagini¿Cuáles Son Las Consideraciones Básicas para Elegir Un Tema y LevantamientoSanto Miguel Roman GarciaÎncă nu există evaluări
- Metodos de Geoestadistica PDFDocument38 paginiMetodos de Geoestadistica PDFhilda magaliÎncă nu există evaluări
- Trabajo Investigacion Arcilla-IDocument12 paginiTrabajo Investigacion Arcilla-ICliner Flores0% (1)
- Proyectos Sociales - EcoDocument2 paginiProyectos Sociales - EcohenryÎncă nu există evaluări
- Metodologia MaterialDocument8 paginiMetodologia MaterialLennyn AriasÎncă nu există evaluări
- 4) EpistemologiaDocument18 pagini4) Epistemologiajaime100% (1)
- GUIA-1-Estadistica-I UNIDO COMPLETODocument61 paginiGUIA-1-Estadistica-I UNIDO COMPLETOPedro Luis ManchayÎncă nu există evaluări
- MP - Raul Pino Gotuzzo (Cap 1)Document1 paginăMP - Raul Pino Gotuzzo (Cap 1)Hugo Hennry ArevaloÎncă nu există evaluări
- Trabajo Final de Estadistica DescriptivaDocument16 paginiTrabajo Final de Estadistica DescriptivaMauricio QuispeÎncă nu există evaluări
- TP8 - PPT Chi Cuadrado - Prueba de Independencia de AtributosDocument23 paginiTP8 - PPT Chi Cuadrado - Prueba de Independencia de AtributosAnonymous HdENZfRÎncă nu există evaluări
- Calculo DILUCIONDocument2 paginiCalculo DILUCIONNicolas Eduardo Moraga FaundezÎncă nu există evaluări
- Plan Provincial de Riego y DrenajeDocument250 paginiPlan Provincial de Riego y DrenajePARE1002Încă nu există evaluări
- Ventilación de Minas 13-04-2017Document82 paginiVentilación de Minas 13-04-2017nelson javier perezÎncă nu există evaluări
- Relación Entre El Rendimiento Académico en Matemáticas y Los Estilos de Aprendizaje de Los Estudiantes de La FDocument29 paginiRelación Entre El Rendimiento Académico en Matemáticas y Los Estilos de Aprendizaje de Los Estudiantes de La FJorge Eliecer Villarreal Fernandez100% (1)
- Proyecto de Tesis InvestigacionDocument36 paginiProyecto de Tesis InvestigacionAnonymous vSLbWIndEmÎncă nu există evaluări
- Ayuda 05 Introducción A La ProbabilidadDocument75 paginiAyuda 05 Introducción A La ProbabilidadAngel AquinoÎncă nu există evaluări
- Ensayo de VariablesDocument9 paginiEnsayo de VariablesAngela Malpartida HurtadoÎncă nu există evaluări
- Planteamiento Del ProblemaDocument34 paginiPlanteamiento Del ProblemaLuis Alejandro D TÎncă nu există evaluări
- Word 2007 - Tablas PDFDocument37 paginiWord 2007 - Tablas PDFCristobal Abdias JoveÎncă nu există evaluări
- Sistema de Gestión IntegralDocument2 paginiSistema de Gestión IntegralCrystell GrandaÎncă nu există evaluări
- Planificacion MineraDocument45 paginiPlanificacion MineraClaudia Alejandra100% (1)
- Evaluacion de Proyectos MinerosDocument1 paginăEvaluacion de Proyectos Mineroslamisma09Încă nu există evaluări
- Inf - South African Mining - MinecreteDocument5 paginiInf - South African Mining - MinecreteEDWIN MEJIA MANRIQUEÎncă nu există evaluări
- Diseño ExperimentalDocument1 paginăDiseño Experimentalsandy sanchezÎncă nu există evaluări
- InterperismoDocument18 paginiInterperismoMarcelino Salazar100% (1)
- Dialnet Proceso de Internacionalización de EmpresasDocument25 paginiDialnet Proceso de Internacionalización de EmpresasjuanÎncă nu există evaluări
- Crecimiento de La Ingenieria en El PeruDocument10 paginiCrecimiento de La Ingenieria en El PeruALBERTOÎncă nu există evaluări
- Reglamento Nivel SuperiorDocument94 paginiReglamento Nivel SuperiorRuth Cobo RosalesÎncă nu există evaluări
- Ventilación de Minas Clase 5Document36 paginiVentilación de Minas Clase 5Christopher hilario Poma LópezÎncă nu există evaluări
- Entrevista A Rodolfo LacyDocument2 paginiEntrevista A Rodolfo LacyCarmen FloresÎncă nu există evaluări
- Formulacion de Un Proyecto Ambiental Escolar. SenaDocument32 paginiFormulacion de Un Proyecto Ambiental Escolar. SenaNohoraÎncă nu există evaluări
- Derivacion NumericaDocument11 paginiDerivacion NumericaLuis Gustavo Flores RondonÎncă nu există evaluări
- Regresion Lineal PDFDocument9 paginiRegresion Lineal PDFJuan Felipe EstradaÎncă nu există evaluări
- Contraste de Hipótesis: CapituloDocument58 paginiContraste de Hipótesis: CapituloFatima del Pilar Espinoza MirandaÎncă nu există evaluări
- Ensayo de Pruebas de HipotesisDocument8 paginiEnsayo de Pruebas de HipotesisAiranÎncă nu există evaluări
- Prueba de HipotesisDocument17 paginiPrueba de HipotesisJavier De La HozÎncă nu există evaluări
- Definición-Fases-Características - PsicoComunitariaDocument23 paginiDefinición-Fases-Características - PsicoComunitariaAngie LeonelaÎncă nu există evaluări
- América LatinaDocument17 paginiAmérica LatinaAngie LeonelaÎncă nu există evaluări
- América LatinaDocument17 paginiAmérica LatinaAngie LeonelaÎncă nu există evaluări
- Definición-Fases-Características - PsicoComunitariaDocument23 paginiDefinición-Fases-Características - PsicoComunitariaAngie LeonelaÎncă nu există evaluări
- TrastornosDocument61 paginiTrastornosAnonymous I2nHEMNÎncă nu există evaluări
- América LatinaDocument17 paginiAmérica LatinaAngie LeonelaÎncă nu există evaluări
- TrastornosDocument61 paginiTrastornosAnonymous I2nHEMNÎncă nu există evaluări
- Dialnet PruebasDeBondadDeAjusteAUnaDistribucionNormal 5633043 PDFDocument10 paginiDialnet PruebasDeBondadDeAjusteAUnaDistribucionNormal 5633043 PDFChristhian RivadeneiraÎncă nu există evaluări
- Prueba de Hipótesis 20200911 METODOS PDFDocument19 paginiPrueba de Hipótesis 20200911 METODOS PDFAngie LeonelaÎncă nu există evaluări
- Modelo DidacticoDocument21 paginiModelo DidacticoericaalemvÎncă nu există evaluări
- DocumentDocument10 paginiDocumentAngie LeonelaÎncă nu există evaluări
- El Poder Del FeedbackDocument2 paginiEl Poder Del FeedbackElena MaischÎncă nu există evaluări
- Mauricio - Aracena - Barraza - s4 - InstrumDocument4 paginiMauricio - Aracena - Barraza - s4 - InstrumMauricio AracenaÎncă nu există evaluări
- Universidad Nacional Autonoma de Honduras.: Luis Andrés Pineda ZúnigaDocument5 paginiUniversidad Nacional Autonoma de Honduras.: Luis Andrés Pineda ZúnigaDarwin PinedaÎncă nu există evaluări
- Ladrillo EcologicoDocument5 paginiLadrillo EcologicoDIEGO BRAYHAN PERALTA CAPCHAÎncă nu există evaluări
- Guia de Reforzamiento. 8vo Grado 2023Document1 paginăGuia de Reforzamiento. 8vo Grado 2023DONALD JOSE LOPEZ ESPINOZAÎncă nu există evaluări
- Planificación Estrategica-2022-2027-V11-08-2022Document101 paginiPlanificación Estrategica-2022-2027-V11-08-2022Edmundo ValenzuelaÎncă nu există evaluări
- Chi Cuadrado EjerciciosDocument2 paginiChi Cuadrado Ejerciciosfercho paredesÎncă nu există evaluări
- 10-MM-Lista Parámetros MM420 440Document159 pagini10-MM-Lista Parámetros MM420 440Jose Luis Martinez MartinezÎncă nu există evaluări
- Conectores para La Construcción Con MaderaDocument340 paginiConectores para La Construcción Con MaderaStiebler IngenierosÎncă nu există evaluări
- El TeodolitoDocument48 paginiEl TeodolitoYesseña Abegail33% (3)
- Prescripción AdqusitivaDocument2 paginiPrescripción AdqusitivaJuan Pablo CuevaÎncă nu există evaluări
- Anales de TV OnlineDocument10 paginiAnales de TV OnlineJoel Alfredo Acosta ChirinosÎncă nu există evaluări
- Glab - s02 - Ssarmiento - 2022 2Document6 paginiGlab - s02 - Ssarmiento - 2022 2Janeth Roxana Mamani MamaniÎncă nu există evaluări
- Parcial 1Document33 paginiParcial 1Heriberto CalderonÎncă nu există evaluări
- Starbucks - Service Exploration On BehanceDocument3 paginiStarbucks - Service Exploration On BehancecarogonherÎncă nu există evaluări
- Analisis Esfuerzos en VigasDocument7 paginiAnalisis Esfuerzos en Vigasleandro prietoÎncă nu există evaluări
- Trabajo Práctico 3 (TP3) TecnoDocument10 paginiTrabajo Práctico 3 (TP3) TecnoFernanda Reynoso VeneziaÎncă nu există evaluări
- Actualizar Nod32 v3 A Mas Sin InternetDocument7 paginiActualizar Nod32 v3 A Mas Sin InternetinsonicoÎncă nu există evaluări
- Guía de Ejercicios de Cálculo de SubredesDocument6 paginiGuía de Ejercicios de Cálculo de SubredesJackoperaÎncă nu există evaluări
- Tarea 1Document4 paginiTarea 1davidÎncă nu există evaluări
- Oc 21001-096 - FiorellaDocument1 paginăOc 21001-096 - FiorellaJesus CondoriÎncă nu există evaluări
- Punto 2 y 3 Entrega 1 de ContabilidadDocument2 paginiPunto 2 y 3 Entrega 1 de ContabilidadSergio Osorio TrivinoÎncă nu există evaluări
- Foo PDFDocument15 paginiFoo PDFjimmy omarÎncă nu există evaluări
- PR09O090XX - MECA - Cambio de Bomba Centrífuga de Cargadero O PiscinasDocument5 paginiPR09O090XX - MECA - Cambio de Bomba Centrífuga de Cargadero O PiscinasWilson BelloÎncă nu există evaluări
- DD072 Tarea PracticaDocument5 paginiDD072 Tarea PracticaCarlos Alfredo Angulo BolañosÎncă nu există evaluări