S-ar putea să vă placă și
- Speech Coding: Fundamentals and Applications: ARK Asegawa OhnsonDocument20 paginiSpeech Coding: Fundamentals and Applications: ARK Asegawa OhnsonKevin CrisdiÎncă nu există evaluări
- Software Radio: Sampling Rate Selection, Design and SynchronizationDe la EverandSoftware Radio: Sampling Rate Selection, Design and SynchronizationÎncă nu există evaluări
- SPARTA McCormackPolitis2019SpartaCompassDocument13 paginiSPARTA McCormackPolitis2019SpartaCompassGuillot GaëlÎncă nu există evaluări
- Maher Ieeespe 0906 476-481Document6 paginiMaher Ieeespe 0906 476-481Emad AfifyÎncă nu există evaluări
- Speech Coding: Fundamentals and Applications: ARK Asegawa OhnsonDocument20 paginiSpeech Coding: Fundamentals and Applications: ARK Asegawa OhnsonMohamed TalaatÎncă nu există evaluări
- 66.Dsp Lab Manual Pbrvits-8.3.202-NewDocument99 pagini66.Dsp Lab Manual Pbrvits-8.3.202-NewmalyadriÎncă nu există evaluări
- N5650 1Document14 paginiN5650 1Debajyoti DattaÎncă nu există evaluări
- TH2015PESC1126 Convertie PDFDocument185 paginiTH2015PESC1126 Convertie PDFLuthfiÎncă nu există evaluări
- Transient Detection in Speech and Audio SignalsDocument8 paginiTransient Detection in Speech and Audio SignalsThanuja adepuÎncă nu există evaluări
- Speech & Audio Processing Part - II: Marc Moonen Dept. E.E./ESAT, K.U.LeuvenDocument22 paginiSpeech & Audio Processing Part - II: Marc Moonen Dept. E.E./ESAT, K.U.LeuvenFadhlanÎncă nu există evaluări
- Me Iii Sem Comm190814040842 PDFDocument7 paginiMe Iii Sem Comm190814040842 PDFachin mponlineÎncă nu există evaluări
- Scheme of Examination of B.EDocument12 paginiScheme of Examination of B.EDivay SawhneyÎncă nu există evaluări
- Procedia: Speech Coding TechniquesDocument11 paginiProcedia: Speech Coding TechniquesMakar HanyÎncă nu există evaluări
- Securing Audio Watermarking System Using Discrete Fourier Transform For Copyright ProtectionDocument5 paginiSecuring Audio Watermarking System Using Discrete Fourier Transform For Copyright ProtectionEditor IJRITCCÎncă nu există evaluări
- TC-311 (Course Profile) DCITDocument3 paginiTC-311 (Course Profile) DCITHani HasanÎncă nu există evaluări
- DcsDocument4 paginiDcsSai AkshayÎncă nu există evaluări
- Third Semester Courses: Course No. Course Name L-T-P-Credits Year of 10EC7105 Audio Processing 3 - 0 - 0 - 3 2015Document2 paginiThird Semester Courses: Course No. Course Name L-T-P-Credits Year of 10EC7105 Audio Processing 3 - 0 - 0 - 3 2015anto5751Încă nu există evaluări
- DSP Engineer, Systems Engineer, Wireless Design EngineerDocument3 paginiDSP Engineer, Systems Engineer, Wireless Design Engineerapi-72678201Încă nu există evaluări
- Jeas 0120 8068Document10 paginiJeas 0120 8068FengXuan YangÎncă nu există evaluări
- A Software Tool For Introducing Speech Coding Fundamentals in A DSP CourseDocument10 paginiA Software Tool For Introducing Speech Coding Fundamentals in A DSP CourseSıtkı AkkayaÎncă nu există evaluări
- Lesson 2 - Digitizing and Packetizing VoiceDocument22 paginiLesson 2 - Digitizing and Packetizing VoiceDe Suares Providencia CarlosÎncă nu există evaluări
- Wireless Ms Zaiba Ishrat - TEC-801Document27 paginiWireless Ms Zaiba Ishrat - TEC-801seemarahulÎncă nu există evaluări
- Advanced Signal Processing: Proceedings of The 21st Academic Council of VIT (30.11.2010)Document2 paginiAdvanced Signal Processing: Proceedings of The 21st Academic Council of VIT (30.11.2010);(Încă nu există evaluări
- Convention Paper 5553: Spectral Band Replication, A Novel Approach in Audio CodingDocument8 paginiConvention Paper 5553: Spectral Band Replication, A Novel Approach in Audio CodingJuan Andrés Mariscal RamirezÎncă nu există evaluări
- Chapter 1 Introduction To DSPDocument22 paginiChapter 1 Introduction To DSPfarina ilyanaÎncă nu există evaluări
- Wang 2010Document6 paginiWang 2010manishscryÎncă nu există evaluări
- Chapter 1: Introduction: Communication Engineering Video Processing Speech/Audio Processing MedicalDocument4 paginiChapter 1: Introduction: Communication Engineering Video Processing Speech/Audio Processing Medicalluong vyÎncă nu există evaluări
- DAFF Soft - DAGA2010Document2 paginiDAFF Soft - DAGA2010efvergaraÎncă nu există evaluări
- Audio CompressionDocument6 paginiAudio CompressionMohammed PublicationsÎncă nu există evaluări
- Ec8562 Digital Signal Processing Laboratory 1953309632 Ec8562 Digital Signal Processing LabDocument81 paginiEc8562 Digital Signal Processing Laboratory 1953309632 Ec8562 Digital Signal Processing LabVenkatesh KumarÎncă nu există evaluări
- Ec8562-Digital Signal Processing Laboratory-1953309632-Ec8562-Digital-Signal-Processing-LabDocument81 paginiEc8562-Digital Signal Processing Laboratory-1953309632-Ec8562-Digital-Signal-Processing-Labmenakadeviece100% (1)
- Measuring The Impact of Audio Compression On The Spectral Quality of Speech DataDocument9 paginiMeasuring The Impact of Audio Compression On The Spectral Quality of Speech DataPaul Vincent NonatÎncă nu există evaluări
- Ec8562 DSP ManualDocument90 paginiEc8562 DSP ManualsudhagarkarpagamÎncă nu există evaluări
- MPEG-4 Advanced Audio CodingDocument13 paginiMPEG-4 Advanced Audio CodingRad OuÎncă nu există evaluări
- Ece4001 Digital-Communication-Systems Eth 1.1 47 Ece4001Document4 paginiEce4001 Digital-Communication-Systems Eth 1.1 47 Ece4001Suhil IrshadÎncă nu există evaluări
- DSD Syllabus KtuDocument1 paginăDSD Syllabus KtuAjÎncă nu există evaluări
- Cep DSPDocument2 paginiCep DSPosama salikÎncă nu există evaluări
- FBDocument3 paginiFBJohn matthewÎncă nu există evaluări
- Ece2006 Digital-Signal-Processing Eth 1.0 37 Ece2006Document3 paginiEce2006 Digital-Signal-Processing Eth 1.0 37 Ece2006John matthewÎncă nu există evaluări
- MPEG Layer-3: An Introduction ToDocument15 paginiMPEG Layer-3: An Introduction TowbauwbauÎncă nu există evaluări
- 10 1 1 111Document11 pagini10 1 1 111deb_ashisdÎncă nu există evaluări
- Challenges and Recent Developments in Hearing AidsDocument42 paginiChallenges and Recent Developments in Hearing AidsMaria Alejandra Rivera ZambranoÎncă nu există evaluări
- Proj No. Title: A/P Chong Yong Kim A/P Gan Woon SengDocument5 paginiProj No. Title: A/P Chong Yong Kim A/P Gan Woon SengTần LongÎncă nu există evaluări
- Voice Signal Processing For Speech Synthesis: June 2006Document6 paginiVoice Signal Processing For Speech Synthesis: June 2006Prince ChaudharyÎncă nu există evaluări
- Voice Signal Processing For Speech Synthesis: June 2006Document6 paginiVoice Signal Processing For Speech Synthesis: June 2006Prince ChaudharyÎncă nu există evaluări
- Automatic Speech Activity Detection, Source Localization, and Speech Recognition On The Chil Seminar CorpusDocument4 paginiAutomatic Speech Activity Detection, Source Localization, and Speech Recognition On The Chil Seminar CorpusPallavi DholeÎncă nu există evaluări
- EC623: Advanced Topics in DSP (ADSP) : 3-0-2-8 Credit Elective CourseDocument19 paginiEC623: Advanced Topics in DSP (ADSP) : 3-0-2-8 Credit Elective CourseShubham MittalÎncă nu există evaluări
- Ec8562-Digital Signal Processing Laboratory-1953309632-Ec8562-Digital-Signal-Processing-LabDocument80 paginiEc8562-Digital Signal Processing Laboratory-1953309632-Ec8562-Digital-Signal-Processing-LabRahul Anand K MÎncă nu există evaluări
- OfdmDocument5 paginiOfdmonallpelinÎncă nu există evaluări
- Ece2006 Digital-Signal-Processing Eth 1.0 37 Ece2006Document3 paginiEce2006 Digital-Signal-Processing Eth 1.0 37 Ece2006maniÎncă nu există evaluări
- EE 615: Lecture 1 Multicarrier Communications: Professor Uf TureliDocument53 paginiEE 615: Lecture 1 Multicarrier Communications: Professor Uf TurelijebileeÎncă nu există evaluări
- Asn PDFDocument21 paginiAsn PDFUma MaheswariÎncă nu există evaluări
- Communication Systems: Fall 2021Document38 paginiCommunication Systems: Fall 2021SyedÎncă nu există evaluări
- TarsosDSP 2.3 ManualDocument14 paginiTarsosDSP 2.3 ManualbenitoÎncă nu există evaluări
- Analysis-Assisted Sound Processing With AudiosculptDocument5 paginiAnalysis-Assisted Sound Processing With AudiosculptAlisa KobzarÎncă nu există evaluări
- Speech Audio Radar DSPDocument3 paginiSpeech Audio Radar DSPPinky BhagwatÎncă nu există evaluări
- Lab Manual: Name Roll No. Year Batch DepartmentDocument64 paginiLab Manual: Name Roll No. Year Batch DepartmentZoe Gazpacho100% (1)
- Me Ece CSSP Syllabus 2011Document39 paginiMe Ece CSSP Syllabus 2011Aejaz AamerÎncă nu există evaluări
- Optimizing Converged Cisco Networks (Ont) : Module 2: Cisco Voip ImplementationsDocument22 paginiOptimizing Converged Cisco Networks (Ont) : Module 2: Cisco Voip ImplementationsccazorlaqscÎncă nu există evaluări
- Contraction of TensorsDocument3 paginiContraction of TensorshachanÎncă nu există evaluări
- Example 9Document3 paginiExample 9hachanÎncă nu există evaluări
- Differential OperatorDocument4 paginiDifferential OperatorhachanÎncă nu există evaluări
- Exponential and Logarithmic FunctionsDocument8 paginiExponential and Logarithmic FunctionshachanÎncă nu există evaluări
- EXAMPLE 7 The Following: ManipulateDocument3 paginiEXAMPLE 7 The Following: ManipulatehachanÎncă nu există evaluări
- Solution 2: 7.3 Trigonometric FunctionsDocument2 paginiSolution 2: 7.3 Trigonometric FunctionshachanÎncă nu există evaluări
- The QR DecompositionDocument3 paginiThe QR DecompositionhachanÎncă nu există evaluări
- The Problem Can Be Translated Into Python With TheDocument2 paginiThe Problem Can Be Translated Into Python With ThehachanÎncă nu există evaluări
- The Cholesky DecompositionDocument4 paginiThe Cholesky DecompositionhachanÎncă nu există evaluări
- Integer ProgrammingDocument5 paginiInteger ProgramminghachanÎncă nu există evaluări
- BoschDocument128 paginiBoschhachanÎncă nu există evaluări
- The Forces On TheDocument8 paginiThe Forces On ThehachanÎncă nu există evaluări
- Sakho I. Introduction To Quantum Mechanics 2. 2020 PDFDocument297 paginiSakho I. Introduction To Quantum Mechanics 2. 2020 PDFhachanÎncă nu există evaluări
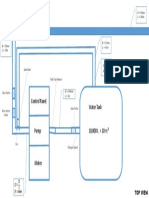
- Water Tank 10,000 L 10 Control Panel: Top ViewDocument1 paginăWater Tank 10,000 L 10 Control Panel: Top ViewhachanÎncă nu există evaluări
- Force andDocument6 paginiForce andhachanÎncă nu există evaluări
- The Arbitrage Pricing Theory ModelDocument3 paginiThe Arbitrage Pricing Theory ModelhachanÎncă nu există evaluări
- Note That The Equations of Steps 1 and 2Document2 paginiNote That The Equations of Steps 1 and 2hachanÎncă nu există evaluări
- And Vertical Forces ActingDocument6 paginiAnd Vertical Forces ActinghachanÎncă nu există evaluări
- 2 DynamicsDocument4 pagini2 DynamicshachanÎncă nu există evaluări
- Tugboat A Is PushingDocument9 paginiTugboat A Is PushinghachanÎncă nu există evaluări
- Calculations and Numerical AccuracyDocument4 paginiCalculations and Numerical AccuracyhachanÎncă nu există evaluări
- NVIDIA System Information 01-08-2011 21-54-14Document1 paginăNVIDIA System Information 01-08-2011 21-54-14Saksham BansalÎncă nu există evaluări
- Annex 4 (Word Format)Document1 paginăAnnex 4 (Word Format)Amores, ArmandoÎncă nu există evaluări
- Using Visio PDFDocument12 paginiUsing Visio PDFAnonymous Af4ORJÎncă nu există evaluări
- Try These: 1.4 Rational Numbers Between Two Rational NumbersDocument1 paginăTry These: 1.4 Rational Numbers Between Two Rational NumbersLokendraÎncă nu există evaluări
- Vandana New ResumeDocument1 paginăVandana New ResumeVandu KÎncă nu există evaluări
- Lecture 6 NormalizationDocument54 paginiLecture 6 NormalizationAndrea BatholomeoÎncă nu există evaluări
- PACSystems RX3i CPU Quick Start GuideDocument54 paginiPACSystems RX3i CPU Quick Start GuideHaz ManÎncă nu există evaluări
- P2P Technology User's ManualDocument8 paginiP2P Technology User's ManualElenilto Oliveira de AlmeidaÎncă nu există evaluări
- Temporary Revision Number 4Document1 paginăTemporary Revision Number 4josephÎncă nu există evaluări
- Oil and Gas Reloaded: Offshore ArgentinaDocument9 paginiOil and Gas Reloaded: Offshore ArgentinaMuhammad Fahmi AnbÎncă nu există evaluări
- C++ SummaryDocument2 paginiC++ SummaryramakantsawantÎncă nu există evaluări
- Victor Chironda CV 2019Document4 paginiVictor Chironda CV 2019Alex LebedevÎncă nu există evaluări
- Nadir Qaiser Zong ProjectDocument42 paginiNadir Qaiser Zong Projectloverboy_q_s80% (5)
- Block Diagram and Signal Flow GraphDocument15 paginiBlock Diagram and Signal Flow GraphAngelus Vincent GuilalasÎncă nu există evaluări
- Z Remy SpaanDocument87 paginiZ Remy SpaanAlexandra AdrianaÎncă nu există evaluări
- Technote On - Communication Between M340 and ATV312 Over Modbus Using READ - VAR and WRITE - VARDocument14 paginiTechnote On - Communication Between M340 and ATV312 Over Modbus Using READ - VAR and WRITE - VARsimbamike100% (1)
- Temario Spring MicroserviciosDocument5 paginiTemario Spring MicroserviciosgcarreongÎncă nu există evaluări
- Improving Privacy and Security in Multi-Authority Attribute-Based EncyptionDocument12 paginiImproving Privacy and Security in Multi-Authority Attribute-Based Encyptionselva kumarÎncă nu există evaluări
- MATLAB and Simulink: Prof. Dr. Ottmar BeucherDocument71 paginiMATLAB and Simulink: Prof. Dr. Ottmar BeucherShubham ChauhanÎncă nu există evaluări
- LG 2300N - DVDDocument9 paginiLG 2300N - DVDh.keulder1480Încă nu există evaluări
- Ultra-Low Standby Power SRAM With Adaptive Data-Retention-Voltage-Regulating SchemeDocument4 paginiUltra-Low Standby Power SRAM With Adaptive Data-Retention-Voltage-Regulating SchemeTasmiyaÎncă nu există evaluări
- Find The Coordinates of Every Square: Naval Grid CalculatorDocument2 paginiFind The Coordinates of Every Square: Naval Grid CalculatorMarie MythosÎncă nu există evaluări
- Massive MIMO (FDD) (eRAN13.1 - 05)Document154 paginiMassive MIMO (FDD) (eRAN13.1 - 05)Shashank Prajapati100% (2)
- ACESYS V8.0 - User Manual - AlternateDocument12 paginiACESYS V8.0 - User Manual - AlternateMohamed AdelÎncă nu există evaluări
- CS201 Introduction To Programming Solved MID Term Paper 03Document4 paginiCS201 Introduction To Programming Solved MID Term Paper 03ayesharahimÎncă nu există evaluări
- CLUSTER 1-Magsaysay-WSPPRDocument18 paginiCLUSTER 1-Magsaysay-WSPPRJopheth RelucioÎncă nu există evaluări
- Problem 5 Limocon, MelendezDocument24 paginiProblem 5 Limocon, MelendezMaria Angela MelendezÎncă nu există evaluări
- 6305ele S1L1Document33 pagini6305ele S1L1M Moiz IlyasÎncă nu există evaluări
- Lathi Ls SM Chapter 2Document33 paginiLathi Ls SM Chapter 2Dr Satyabrata JitÎncă nu există evaluări
- Priority ConservationDocument6 paginiPriority Conservationapi-213428788Încă nu există evaluări