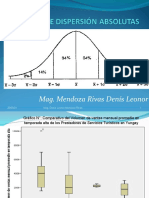
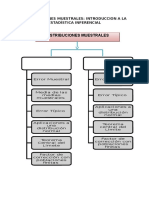
S-ar putea să vă placă și
- Analisis FactorialDocument40 paginiAnalisis FactorialMayra Sánchez CabanillasÎncă nu există evaluări
- Unidad 2Document30 paginiUnidad 2cinthyavmÎncă nu există evaluări
- 3.1.1.b El Modelo de Efectos FijosDocument7 pagini3.1.1.b El Modelo de Efectos FijosYaqueline OrtizÎncă nu există evaluări
- Anova, Regresión y CorrelaciónDocument37 paginiAnova, Regresión y CorrelaciónRichard Felipe100% (1)
- Distribuciones de ProbabilidadDocument9 paginiDistribuciones de ProbabilidadSteve MaycraÎncă nu există evaluări
- Chi Cuadrada 2Document12 paginiChi Cuadrada 2CassandraÎncă nu există evaluări
- Estadistica, Poblacion y MuestraDocument16 paginiEstadistica, Poblacion y MuestralilisenaÎncă nu există evaluări
- Ejemplos y Ejercicios de AmvDocument113 paginiEjemplos y Ejercicios de Amvjaviermetalrock-1100% (1)
- Medidas de Dispersion y EjerciciosDocument11 paginiMedidas de Dispersion y EjercicioscarlosÎncă nu există evaluări
- Guia de Ejercicios 1 EstadisticasDocument26 paginiGuia de Ejercicios 1 EstadisticasJuan Jose Rios Anabia0% (1)
- Prueba de Signos InformeDocument8 paginiPrueba de Signos InformeBryan ValarezoÎncă nu există evaluări
- Manual para Elaboracion de Tesis y Trabajos de InvestigacionDocument91 paginiManual para Elaboracion de Tesis y Trabajos de InvestigacionElver Ambrosio100% (1)
- Analisis MultivariadoDocument55 paginiAnalisis MultivariadoHarold ManzanaresÎncă nu există evaluări
- Anova Dos Factores - Semana 14Document47 paginiAnova Dos Factores - Semana 14Brayan VargayaÎncă nu există evaluări
- Distribución MultinomialDocument16 paginiDistribución MultinomialFernando Reynaga50% (2)
- Qué Es ManovaDocument3 paginiQué Es ManovaBea Mejia0% (1)
- Taller de Componentes PrincipalesDocument18 paginiTaller de Componentes PrincipalesRigoberto ToprresÎncă nu există evaluări
- Analisis FactorialDocument10 paginiAnalisis FactorialIsaías Tafur MallquiÎncă nu există evaluări
- Análisis Multivariante de La Varianza (Manova)Document8 paginiAnálisis Multivariante de La Varianza (Manova)Eduardo ArmasÎncă nu există evaluări
- Medidas de DispersiónDocument49 paginiMedidas de DispersiónCésar Torres QuirozÎncă nu există evaluări
- Capitulo 10-Analisis - Datos - Probabilidad PDFDocument90 paginiCapitulo 10-Analisis - Datos - Probabilidad PDFivcscribdÎncă nu există evaluări
- Analisis Factorial Exploratorio en RStudio Variable Enseñanza VirtualDocument80 paginiAnalisis Factorial Exploratorio en RStudio Variable Enseñanza VirtualJuan Pedro Santos FernándezÎncă nu există evaluări
- Prueba de Bondad de AjusteDocument23 paginiPrueba de Bondad de AjusteCARLA FABIOLA CHALLCO LOPINTAÎncă nu există evaluări
- Ejemplo de Distribucion de PoissonDocument2 paginiEjemplo de Distribucion de Poissonhenry SuarezÎncă nu există evaluări
- Análisis Factorial ExploratorioDocument26 paginiAnálisis Factorial ExploratorioLizbeth Gil100% (1)
- Ejercicios de EstadisticaDocument5 paginiEjercicios de Estadisticadario osorioÎncă nu există evaluări
- 5.1 Regresión Lineal Simple y Correlación.Document40 pagini5.1 Regresión Lineal Simple y Correlación.Ana Laura López OrocioÎncă nu există evaluări
- Datos No AgrupadosDocument9 paginiDatos No Agrupadosmaryfer_2039198278% (9)
- T de StudentDocument4 paginiT de StudentTom QHÎncă nu există evaluări
- Guía de Actividad 2. Movimiento de Proyectil y Caída LibreDocument9 paginiGuía de Actividad 2. Movimiento de Proyectil y Caída LibreKevin HerreraÎncă nu există evaluări
- Matriz Varianza - Docx 2Document5 paginiMatriz Varianza - Docx 2Altagracia MLÎncă nu există evaluări
- Analisis de Correspondencias Con SPSSDocument11 paginiAnalisis de Correspondencias Con SPSSAlia G. Pichincura100% (1)
- Tipos de GráficosDocument22 paginiTipos de GráficosCastillo Becerra Alex JavierÎncă nu există evaluări
- Intervalos de Confianza Con SpssDocument6 paginiIntervalos de Confianza Con SpssRonald Jimenez TemocheÎncă nu există evaluări
- Análisis de CovarianzaDocument21 paginiAnálisis de CovarianzaDavid Misael Contreras SalazarÎncă nu există evaluări
- Diapos Estimación de Parámetros Intervalos de ConfianzaDocument25 paginiDiapos Estimación de Parámetros Intervalos de Confianzajorge macedoÎncă nu există evaluări
- Tarea - Ejercicio Práctico de Prueba de Hipótesis y Análisis de ColinealidadDocument6 paginiTarea - Ejercicio Práctico de Prueba de Hipótesis y Análisis de ColinealidadmargaritaÎncă nu există evaluări
- Chi CuadradoDocument7 paginiChi CuadradoRamiro Muñoz ArévaloÎncă nu există evaluări
- Distribuciones MuestralesDocument8 paginiDistribuciones MuestralesJennifer S LopezÎncă nu există evaluări
- Actividad Práctica N° 01 - Determinación Tamaño MuestraDocument5 paginiActividad Práctica N° 01 - Determinación Tamaño MuestraGonzalo EduardoÎncă nu există evaluări
- La Importancia de La Estadistica en La Ingenieria de SistemasDocument1 paginăLa Importancia de La Estadistica en La Ingenieria de SistemasCamilo Avila GuerreroÎncă nu există evaluări
- Medidas de Tendencia Central DATOS SIN AGRUPARDocument5 paginiMedidas de Tendencia Central DATOS SIN AGRUPARCoquito CocoÎncă nu există evaluări
- Multivariables y Distribuciones MuestralesDocument10 paginiMultivariables y Distribuciones MuestralesAlbertoTreviñoÎncă nu există evaluări
- Unidad 2 Medida de Tendencias Central y DispersiónDocument56 paginiUnidad 2 Medida de Tendencias Central y DispersiónMelanieÎncă nu există evaluări
- Eficiencia de Los Estimadores. Muestreo SistemáticoDocument7 paginiEficiencia de Los Estimadores. Muestreo SistemáticoJuan Carlos TalaveraÎncă nu există evaluări
- AFC AFC Vs AFE: Ideas GeneralesDocument10 paginiAFC AFC Vs AFE: Ideas GeneralesbeaÎncă nu există evaluări
- Organización de Datos Con SPSSDocument11 paginiOrganización de Datos Con SPSSKatherin VanessaÎncă nu există evaluări
- Ejercicios Regresion Lineal SimpleDocument11 paginiEjercicios Regresion Lineal SimpleLesly Leonor Moctezuma VelezÎncă nu există evaluări
- Infografia Distribucion de ProbabilidadesDocument1 paginăInfografia Distribucion de ProbabilidadesAdriana RivadeneiraÎncă nu există evaluări
- EstadísticaDocument15 paginiEstadísticaVero Velasco0% (1)
- Fundamentos Intervalos de ConfianzaDocument5 paginiFundamentos Intervalos de ConfianzaMario Iván SalasÎncă nu există evaluări
- Problemas de Estadistica DescriptivaDocument24 paginiProblemas de Estadistica DescriptivaLidiaReyesCanillas100% (1)
- Práctica Grupal de Análisis de Varianza de Un Factor ResueltoDocument16 paginiPráctica Grupal de Análisis de Varianza de Un Factor Resueltomayte anabel huillca gutierrezÎncă nu există evaluări
- 1.3 Medidas de Posiciòn Aritmetica - Mediana - Moda - CuartilesDocument38 pagini1.3 Medidas de Posiciòn Aritmetica - Mediana - Moda - CuartilesEdison MaciasÎncă nu există evaluări
- Cómo Generar Números Aleatorios en SPSSDocument12 paginiCómo Generar Números Aleatorios en SPSSNelson Pinto CoaquiraÎncă nu există evaluări
- DIFERENCIAS - ANALISIS FACTORIAL Vs COMPONENTES PRINCIPALESDocument4 paginiDIFERENCIAS - ANALISIS FACTORIAL Vs COMPONENTES PRINCIPALESGabriel GodheroÎncă nu există evaluări
- ANALISIS FACTORIAL Abreviado (Apunte 9)Document10 paginiANALISIS FACTORIAL Abreviado (Apunte 9)Rodrigo Andres Corvalán MartínezÎncă nu există evaluări
- Apuntes Analisis FactorialDocument64 paginiApuntes Analisis FactorialIsabelÎncă nu există evaluări
- Contraste en El Modelo FactorialDocument10 paginiContraste en El Modelo Factorialnaval1879Încă nu există evaluări
- El ModeloDocument9 paginiEl ModeloMuestrasÎncă nu există evaluări
- Competitividad Del Sector Seguro y ReaseguroDocument2 paginiCompetitividad Del Sector Seguro y ReaseguroLineth RodriguezÎncă nu există evaluări
- Seminario IEE Tema 3aDocument7 paginiSeminario IEE Tema 3ayany_oaxacaÎncă nu există evaluări
- Educacion Terapia Ocupacional Navarra 06Document22 paginiEducacion Terapia Ocupacional Navarra 06Jesuss HidalgoÎncă nu există evaluări
- DD072 Herramientas Inform Ticas de Gesti N de ProyectosDocument4 paginiDD072 Herramientas Inform Ticas de Gesti N de Proyectosalvaro villamizarÎncă nu există evaluări
- Pictogram ADocument2 paginiPictogram ASabadoGrisÎncă nu există evaluări
- Arte Contemporáneo: Cuarto-Quinto: Semana 15Document34 paginiArte Contemporáneo: Cuarto-Quinto: Semana 15Manuel ArmandoÎncă nu există evaluări
- Entrevista A Los Maestros de PrimeroDocument2 paginiEntrevista A Los Maestros de PrimeroJair RivasÎncă nu există evaluări
- CASOS REGISTRADOS - PriscilaDocument2 paginiCASOS REGISTRADOS - PriscilaPRISCILA ABIGAIL SANCHEZ ESQUECHEÎncă nu există evaluări
- Puertos y Terminales Pesqueras 21Document17 paginiPuertos y Terminales Pesqueras 21Edwin Antonio Ortiz FalconÎncă nu există evaluări
- Sistema Nervioso CentralDocument7 paginiSistema Nervioso CentralMondongo gokuÎncă nu există evaluări
- Empresa Sesion 2Document23 paginiEmpresa Sesion 2Alexander GutierrezÎncă nu există evaluări
- Texto ArgumentativoDocument12 paginiTexto ArgumentativoAngela ChavezÎncă nu există evaluări
- Acueducto Romano de MellariaDocument7 paginiAcueducto Romano de MellariaCarmen Gonzalez TorricoÎncă nu există evaluări
- Javier Aguirre FernándezDocument4 paginiJavier Aguirre Fernándezjuancho usanavy marinaÎncă nu există evaluări
- Producto Acádemico 3Document3 paginiProducto Acádemico 3GENRRY ALDAZABAL PORTILLAÎncă nu există evaluări
- PR301-01A3 Manual de Instrucciones v01Document42 paginiPR301-01A3 Manual de Instrucciones v01Jay Cee RizoÎncă nu există evaluări
- Incapacidad ValentinaDocument1 paginăIncapacidad Valentinakarol fajardoÎncă nu există evaluări
- 11 Informe de Salud y Seguridad en El TrabajoDocument11 pagini11 Informe de Salud y Seguridad en El Trabajocarlos alradoado calderonÎncă nu există evaluări
- Tarea 3Document11 paginiTarea 3Karen CastilloÎncă nu există evaluări
- Memoria Descriptiva Instalaciones SanitariasDocument12 paginiMemoria Descriptiva Instalaciones SanitariasIngIngÎncă nu există evaluări
- Practico 1Document2 paginiPractico 1Belen EchegoyenÎncă nu există evaluări
- Región e Historia en MéxicoDocument133 paginiRegión e Historia en MéxicoVictor Torres RosasÎncă nu există evaluări
- Biosensores y BiomarcadoresDocument63 paginiBiosensores y BiomarcadoresMiguel AlfaroÎncă nu există evaluări
- 1° de Secundaria AP - 1° TrimestreDocument14 pagini1° de Secundaria AP - 1° TrimestreAlem Amed Rojas UgarteÎncă nu există evaluări
- Protocolo de BioseguriddDocument9 paginiProtocolo de BioseguriddMárolys LozanoÎncă nu există evaluări
- Zookeeper UpRunningDocument18 paginiZookeeper UpRunningrazasuperiorÎncă nu există evaluări
- F27 2018 3trimestre DuDocument579 paginiF27 2018 3trimestre DuAle CMÎncă nu există evaluări
- Etapa Dinámica Del Proceso AdministrativoDocument8 paginiEtapa Dinámica Del Proceso AdministrativoSandra MelingÎncă nu există evaluări
- Academia Amantes Del Conocimiento: Ciclo Repaso San Marcos 2023 - IDocument11 paginiAcademia Amantes Del Conocimiento: Ciclo Repaso San Marcos 2023 - IDiego Dueñas VelardeÎncă nu există evaluări
- Problemas Derivadas IDocument2 paginiProblemas Derivadas IRaul Enrique Carrasco ConchaÎncă nu există evaluări
- Tipos de Sanciones TributariasDocument18 paginiTipos de Sanciones TributariasAleja ToroÎncă nu există evaluări
- Oportunidades y Desafios Ley 31335 PDFDocument29 paginiOportunidades y Desafios Ley 31335 PDFPriscila Cristina Echevarría López100% (1)
- Informacion PITDocument5 paginiInformacion PITcarlosfranco2013Încă nu există evaluări