S-ar putea să vă placă și
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (119)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (587)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2219)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (894)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- Transcription and TranslationDocument4 paginiTranscription and TranslationGerry0% (1)
- Animal Digestion and NutritionDocument36 paginiAnimal Digestion and Nutritionelliequinn5100% (1)
- Estimation & Extraction of DNADocument5 paginiEstimation & Extraction of DNAR .K.BÎncă nu există evaluări
- Full Download Beckers World of The Cell 9th Edition Hardin Solutions ManualDocument35 paginiFull Download Beckers World of The Cell 9th Edition Hardin Solutions Manualsmallmanclaude100% (38)
- PFCRT Gene in Plasmodium Falciparum Field Isolates From Muzaffargarh, PakistanDocument12 paginiPFCRT Gene in Plasmodium Falciparum Field Isolates From Muzaffargarh, PakistanvivaÎncă nu există evaluări
- A Wearable Electrochemical Biosensor For The Monitoring of Metabolites and NutrientsDocument13 paginiA Wearable Electrochemical Biosensor For The Monitoring of Metabolites and NutrientsBAUTISTA DIPAOLA100% (1)
- The Guide To QPCRDocument109 paginiThe Guide To QPCRPaweł GłodowiczÎncă nu există evaluări
- Effects of Quinine Quinidine and Chloroquine On A9Document8 paginiEffects of Quinine Quinidine and Chloroquine On A9Arun BharathiÎncă nu există evaluări
- Heat Shock ProteinsDocument4 paginiHeat Shock ProteinsAndri Praja SatriaÎncă nu există evaluări
- Polymers: Acids PhosphateDocument10 paginiPolymers: Acids PhosphategqsdjztkydÎncă nu există evaluări
- BIO 101 Chapter 8Document13 paginiBIO 101 Chapter 8mkmanÎncă nu există evaluări
- Genomic and Non-Genomic Effects of Androgens in The Cardiovascular System: Clinical ImplicationsDocument14 paginiGenomic and Non-Genomic Effects of Androgens in The Cardiovascular System: Clinical ImplicationsGeraldine Villamil JiménezÎncă nu există evaluări
- CH 7 Cellular Respiration CompleteDocument31 paginiCH 7 Cellular Respiration CompleteWilly WonkaÎncă nu există evaluări
- 9700 s15 QP CompleteDocument264 pagini9700 s15 QP CompleteJohnÎncă nu există evaluări
- USABODocument2 paginiUSABOkcinvinciblemanÎncă nu există evaluări
- Chapter V: LIPIDSDocument23 paginiChapter V: LIPIDSGwyneth Marie DayaganÎncă nu există evaluări
- Drosophila Developmental Biology Methods - 2014 - MethodsDocument1 paginăDrosophila Developmental Biology Methods - 2014 - MethodsYenifer Paola Rojas QuejadaÎncă nu există evaluări
- CellcommworksheetDocument1 paginăCellcommworksheetYolpy AvukovuÎncă nu există evaluări
- Synthetic DNA Synthesis and Assembly PDFDocument17 paginiSynthetic DNA Synthesis and Assembly PDFAlessandroÎncă nu există evaluări
- Edexcel Intl A Levels Biology Unit 2 Wbi12 v1Document14 paginiEdexcel Intl A Levels Biology Unit 2 Wbi12 v1seif nimerÎncă nu există evaluări
- What Is OpsonizationDocument56 paginiWhat Is OpsonizationrekhaÎncă nu există evaluări
- Grade 11: General Biology IDocument38 paginiGrade 11: General Biology ITEOFILO GATDULAÎncă nu există evaluări
- 10 PlasmidsDocument17 pagini10 Plasmidsparduman kumarÎncă nu există evaluări
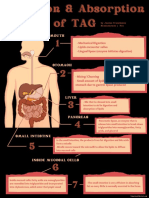
- Digestion & Absorption of TAGDocument1 paginăDigestion & Absorption of TAGJanine Franchesca SuministradoÎncă nu există evaluări
- Protein Synthesis - WorksheetDocument7 paginiProtein Synthesis - WorksheetMaisha IslamÎncă nu există evaluări
- Cell Cycle CheckpointsDocument3 paginiCell Cycle CheckpointsAlbert Jade Pontimayor LegariaÎncă nu există evaluări
- FMGE Information BulletinDocument17 paginiFMGE Information Bulletinmahesh100% (4)
- Chromosomal AlterationsDocument6 paginiChromosomal AlterationsJestoni BigaelÎncă nu există evaluări
- L 55 Introduction To Hormones and Hormone Receptors (CH 75)Document15 paginiL 55 Introduction To Hormones and Hormone Receptors (CH 75)Tayai LengimaÎncă nu există evaluări
- Biological Importance of MagnasiumDocument27 paginiBiological Importance of Magnasiumwarrierabhay100% (1)