S-ar putea să vă placă și
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5795)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Lecture - 15 Dynamic Interconnection NetworksDocument13 paginiLecture - 15 Dynamic Interconnection NetworksmohsinmanzoorÎncă nu există evaluări
- Mini Project - Machine Learning - Tejas NayakDocument65 paginiMini Project - Machine Learning - Tejas Nayaktejas_nayakÎncă nu există evaluări
- Introduction To TouchdesignerDocument134 paginiIntroduction To TouchdesignerIsmael Vanni100% (1)
- Windows 10 Pro v.1511 En-Us x64 July2016 Pre-Activated - TEAM OS (Download Torrent) - TPBDocument2 paginiWindows 10 Pro v.1511 En-Us x64 July2016 Pre-Activated - TEAM OS (Download Torrent) - TPBKarogelRamiterre50% (2)
- Memory Management in LINUXDocument16 paginiMemory Management in LINUXShifan DemahomÎncă nu există evaluări
- Cisco SRA - Chap4Document42 paginiCisco SRA - Chap4pikamauÎncă nu există evaluări
- BACnet BasicsDocument28 paginiBACnet BasicsWasimulHaq WaimulÎncă nu există evaluări
- Message QueuesDocument15 paginiMessage QueuesRoshni BijuÎncă nu există evaluări
- NetApp 2500 Series - Product Comparison - Data StorageDocument2 paginiNetApp 2500 Series - Product Comparison - Data StorageSahatma SiallaganÎncă nu există evaluări
- A Project Report On Tic Tac Toe GameDocument13 paginiA Project Report On Tic Tac Toe GameKabeer GolechhaÎncă nu există evaluări
- The Inside Story On Shared Libraries and Dynamic LoadingDocument8 paginiThe Inside Story On Shared Libraries and Dynamic Loadingprabhakar_n1Încă nu există evaluări
- Oracle Applications: AD Utilities Reference GuideDocument112 paginiOracle Applications: AD Utilities Reference GuideNaresh BabuÎncă nu există evaluări
- Chapter 7: Networking Concepts: IT Essentials v6.0Document7 paginiChapter 7: Networking Concepts: IT Essentials v6.0Chan ChanÎncă nu există evaluări
- Free Download Data Science Curriculum - Innomatics Research Labs Hyderabad, IndiaDocument14 paginiFree Download Data Science Curriculum - Innomatics Research Labs Hyderabad, IndiaAkash InnomaticsÎncă nu există evaluări
- 1COR232Document5 pagini1COR232fin99Încă nu există evaluări
- Issue Fixed:: Sapi/nf-Processthreadsapi-CreateprocessaDocument5 paginiIssue Fixed:: Sapi/nf-Processthreadsapi-CreateprocessafarlysonÎncă nu există evaluări
- Power BiDocument68 paginiPower BiRamanath MaddaliÎncă nu există evaluări
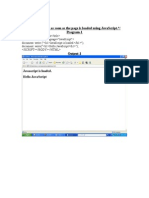
- Display Hello As Soon As The Page Is Loaded Using Javascript. / Program-1Document25 paginiDisplay Hello As Soon As The Page Is Loaded Using Javascript. / Program-1arun1974Încă nu există evaluări
- User's Guide: Code Composer Studio IDE Getting Started GuideDocument90 paginiUser's Guide: Code Composer Studio IDE Getting Started Guiderudra_1Încă nu există evaluări
- 001MIT411 LabExer001Document3 pagini001MIT411 LabExer001Yatten0% (1)
- Ece 313: Problem Set 6 Reliability and CdfsDocument2 paginiEce 313: Problem Set 6 Reliability and CdfsspitzersglareÎncă nu există evaluări
- Jira GuideDocument104 paginiJira Guideioana_nekÎncă nu există evaluări
- Avocent Virtual KVMDocument1 paginăAvocent Virtual KVMbrightanvilÎncă nu există evaluări
- U C51Document138 paginiU C51coep05Încă nu există evaluări
- Blacklist SpamHausDocument4 paginiBlacklist SpamHausjhonnathan0103Încă nu există evaluări
- MSinfo 32Document81 paginiMSinfo 32stevetorpeyÎncă nu există evaluări
- Ipinfusion Company Interview Questions Asked at 5 Years ExperienceDocument4 paginiIpinfusion Company Interview Questions Asked at 5 Years ExperienceAnjani Kumar RaiÎncă nu există evaluări
- How To Choose A Micro ControllerDocument22 paginiHow To Choose A Micro ControllerGAN SA KI100% (1)
- QP QuadprogDocument4 paginiQP QuadprogEmpire AlliesÎncă nu există evaluări
- Forecasting Gold Prices Using Fuzzy C MeansDocument8 paginiForecasting Gold Prices Using Fuzzy C MeansJournal of ComputingÎncă nu există evaluări