S-ar putea să vă placă și
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Ethical Practices in Bangladeshi MediaDocument18 paginiEthical Practices in Bangladeshi MediaRakib_23450% (2)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- Digital and Data CommunicationsDocument7 paginiDigital and Data CommunicationsyaelfabulousÎncă nu există evaluări
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- DAILY LESSON LOG OF M1NS-Ib-3 (Week Two-Day 2)Document4 paginiDAILY LESSON LOG OF M1NS-Ib-3 (Week Two-Day 2)Anonymous GLXj9kKp2Încă nu există evaluări
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Department of Education: Republic of The PhilippinesDocument2 paginiDepartment of Education: Republic of The PhilippinesMEDARDO OBRA100% (1)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- November SCHOOL-TO-SCHOOL PARTNERSHIP (BNHS & TIPAS)Document4 paginiNovember SCHOOL-TO-SCHOOL PARTNERSHIP (BNHS & TIPAS)ryanÎncă nu există evaluări
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
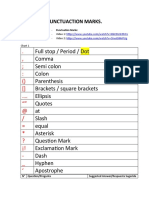
- Full Stop / Period / Dot Comma Semi Colon Colon Parenthesis Brackets / Square Brackets Ellipsis Quotes at Slash Equal Asterisk Question Mark Exclamation Mark Dash Hyphen ApostropheDocument3 paginiFull Stop / Period / Dot Comma Semi Colon Colon Parenthesis Brackets / Square Brackets Ellipsis Quotes at Slash Equal Asterisk Question Mark Exclamation Mark Dash Hyphen ApostropheJorge Cardona SanchezÎncă nu există evaluări
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- Globex Call Center Solutions Presentation PDFDocument9 paginiGlobex Call Center Solutions Presentation PDFAnas SapryÎncă nu există evaluări
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Demo (Inverse of One-to-One Functions)Document3 paginiDemo (Inverse of One-to-One Functions)April Joy LascuñaÎncă nu există evaluări
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- Self DirectedLearningVanBriesen2010Document21 paginiSelf DirectedLearningVanBriesen2010Enric ToledoÎncă nu există evaluări
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- Syntagmatic and Paradigmatic RelationsDocument3 paginiSyntagmatic and Paradigmatic RelationsdattarupamÎncă nu există evaluări
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- CT2Pro User Manual Final CompressedDocument2 paginiCT2Pro User Manual Final CompressedRicky VelascoÎncă nu există evaluări
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Midterm Exam Full Name: - Estrella Jines Ruiz - Date: - Teacher: Antonio AlburquequeDocument3 paginiMidterm Exam Full Name: - Estrella Jines Ruiz - Date: - Teacher: Antonio AlburquequeMaria Ruiz AlcasÎncă nu există evaluări
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Department of Education: Republic of The PhilippinesDocument2 paginiDepartment of Education: Republic of The PhilippinesRIO ORPIANOÎncă nu există evaluări
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- Miss Zainab Ammar: Standard ConsultationDocument1 paginăMiss Zainab Ammar: Standard Consultationammar naeemÎncă nu există evaluări
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (345)
- (SUMMARY) Perilaku Keorganisasian (Chapter 11) PDFDocument7 pagini(SUMMARY) Perilaku Keorganisasian (Chapter 11) PDFtaqi taqaÎncă nu există evaluări
- Speaking Naturally Tillitt Bruce Newton Bruder MaryDocument128 paginiSpeaking Naturally Tillitt Bruce Newton Bruder MaryamegmhÎncă nu există evaluări
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Authentic Assessment: Benefits To Learning and Implementation ChallengesDocument10 paginiAuthentic Assessment: Benefits To Learning and Implementation ChallengesMissia H. SabtalÎncă nu există evaluări
- ENG201 Past Final Term Solved MCQsDocument24 paginiENG201 Past Final Term Solved MCQscs619finalproject.com80% (5)
- Architecture Diagram - End-To-End IP Options - EBO 2022Document1 paginăArchitecture Diagram - End-To-End IP Options - EBO 2022bambangÎncă nu există evaluări
- Questionnaire For Syllabus Design 2Document7 paginiQuestionnaire For Syllabus Design 2Talha MaqsoodÎncă nu există evaluări
- Jot2 Task2 Kylefibelstad FinaldraftDocument17 paginiJot2 Task2 Kylefibelstad Finaldraftapi-556169844Încă nu există evaluări
- Register Context of SituationDocument18 paginiRegister Context of SituationFebri SusantiÎncă nu există evaluări
- Teaching Methodology (Handout)Document1 paginăTeaching Methodology (Handout)Sharjeel Ahmed Khan100% (1)
- OTP SMS in UAE & Saudi Arabia - Transactional SMS ServiceDocument5 paginiOTP SMS in UAE & Saudi Arabia - Transactional SMS ServiceinayagillnidaÎncă nu există evaluări
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- Writing TopicsDocument4 paginiWriting Topicshongpk.2006Încă nu există evaluări
- Introduction To Natural Language Processing (NLP)Document87 paginiIntroduction To Natural Language Processing (NLP)PATSON CHIDARIÎncă nu există evaluări
- Comparative Study On Wireless Mobile Technology 1G, 2G, 3G, 4G and 5GDocument5 paginiComparative Study On Wireless Mobile Technology 1G, 2G, 3G, 4G and 5GnhatvpÎncă nu există evaluări
- Word Count Vs Text Count An AlternativeDocument5 paginiWord Count Vs Text Count An AlternativePishoi ArmaniosÎncă nu există evaluări
- Research Templete WindaDocument6 paginiResearch Templete WindazzrylileÎncă nu există evaluări
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Positive Classroom EnvironmentsDocument5 paginiPositive Classroom Environmentsapi-302210367Încă nu există evaluări
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)