S-ar putea să vă placă și
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5784)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (890)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (587)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (72)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (119)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Killer Robot Report 1Document3 paginiKiller Robot Report 1Anuja SharmaÎncă nu există evaluări
- Worksheet 5 Obstacle DetectionDocument3 paginiWorksheet 5 Obstacle Detectionapi-239713895Încă nu există evaluări
- Seam TrackingDocument16 paginiSeam TrackingSadek Crisostomo Absi AlfaroÎncă nu există evaluări
- VEX IQ Curriculum: It's Your FutureDocument12 paginiVEX IQ Curriculum: It's Your FutureFatmaÎncă nu există evaluări
- Machine Learning in Manufacturing Ergonomics Recent Advances Challenges and OpportunitiesDocument8 paginiMachine Learning in Manufacturing Ergonomics Recent Advances Challenges and OpportunitiesFARHANAH ALMIRAH NADILA -Încă nu există evaluări
- Chapter 1 - FundamentalsDocument28 paginiChapter 1 - FundamentalsHayleysus ShmelashÎncă nu există evaluări
- Solar Powered Mobile Operated Smart Multifunction Agriculture RobotDocument4 paginiSolar Powered Mobile Operated Smart Multifunction Agriculture RobotVIVA-TECH IJRIÎncă nu există evaluări
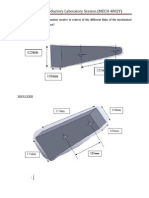
- Robotics Lab Session Covers Drive Mechanisms, Payloads, Sensors (MECH 4002YDocument12 paginiRobotics Lab Session Covers Drive Mechanisms, Payloads, Sensors (MECH 4002Ysanjiv0909Încă nu există evaluări
- Actuators and Robot Systems (PE-VI) - Google FormsDocument8 paginiActuators and Robot Systems (PE-VI) - Google FormsappuamreddyÎncă nu există evaluări
- MATLAB Meets LEGO Mindstorms - A Freshman Introduction Course Into Practical EngineeringDocument13 paginiMATLAB Meets LEGO Mindstorms - A Freshman Introduction Course Into Practical Engineeringiky77Încă nu există evaluări
- Industrial Robotics OverviewDocument54 paginiIndustrial Robotics OverviewKishore RaviÎncă nu există evaluări
- Ceg4158 PDCDocument4 paginiCeg4158 PDCZichao ZhangÎncă nu există evaluări
- Robotics Course Objectives and ApplicationsDocument5 paginiRobotics Course Objectives and ApplicationsN Dhanunjaya Rao BorraÎncă nu există evaluări
- Ac 2012-3073: Practical Hands-On Industrial Robotics Lab-Oratory DevelopmentDocument10 paginiAc 2012-3073: Practical Hands-On Industrial Robotics Lab-Oratory DevelopmentMerced HernandezÎncă nu există evaluări
- Final Year Project Proposal - AgcDocument8 paginiFinal Year Project Proposal - AgcOsei SylvesterÎncă nu există evaluări
- Industrial Robotics GuideDocument68 paginiIndustrial Robotics GuideRameshÎncă nu există evaluări
- (Intelligent Robotics and Autonomous Agents Series) Choset H., Et Al.-Principles of Robot Motion - Theory, Algorithms, and Implementations-MIT (2005)Document616 pagini(Intelligent Robotics and Autonomous Agents Series) Choset H., Et Al.-Principles of Robot Motion - Theory, Algorithms, and Implementations-MIT (2005)Rounak Majumdar100% (1)
- Fast, Accurate Multi-Axis Programming For Robots.: Delcam PLC, AMS Division WWW - Delcam.tvDocument2 paginiFast, Accurate Multi-Axis Programming For Robots.: Delcam PLC, AMS Division WWW - Delcam.tvOscar SaenzÎncă nu există evaluări
- Analysis Section 1Document13 paginiAnalysis Section 1Noman ShahzadÎncă nu există evaluări
- OSOYOO V2.1 Robot Car Kit For Arduino - Introduction Model#2019012400Document15 paginiOSOYOO V2.1 Robot Car Kit For Arduino - Introduction Model#2019012400geloandima1Încă nu există evaluări
- Seminar ON (Snake Robot) : Biomimetic RobotsDocument16 paginiSeminar ON (Snake Robot) : Biomimetic RobotsJitendra SarojÎncă nu există evaluări
- Ai AslDocument4 paginiAi AslTanishq agarwalÎncă nu există evaluări
- Modeling Puma Robot Using MatlabDocument3 paginiModeling Puma Robot Using MatlabJulio Luis Guzman MarañonÎncă nu există evaluări
- Echnopreneur AND Echnopreneurship: Pamantasan NG Cabuyao College of Computing and EngineeringDocument10 paginiEchnopreneur AND Echnopreneurship: Pamantasan NG Cabuyao College of Computing and EngineeringLeslie Ann Elazegui UntalanÎncă nu există evaluări
- Warehouse Robotics MarketDocument11 paginiWarehouse Robotics MarketIndustryARC Automation100% (1)
- Introduction To RoboticsDocument17 paginiIntroduction To RoboticsBharath ThatipamulaÎncă nu există evaluări
- Law EssayDocument4 paginiLaw EssayJackÎncă nu există evaluări
- Robot Programming: Amirkabir University of Technology Computer Engineering & Information Technology DepartmentDocument35 paginiRobot Programming: Amirkabir University of Technology Computer Engineering & Information Technology Departmentiliekp8Încă nu există evaluări
- Industrial RoboticsDocument23 paginiIndustrial Roboticssamarjit ghatageÎncă nu există evaluări
- Agriculture AutomationDocument10 paginiAgriculture AutomationPon Pari VendanÎncă nu există evaluări