S-ar putea să vă placă și
- Environmental Economics for Tree Huggers and Other SkepticsDe la EverandEnvironmental Economics for Tree Huggers and Other SkepticsÎncă nu există evaluări
- SIR GIBBIE & DONAL GRANT: The Baronet's Song and The Shepherd's Castle (Adventure Classic)De la EverandSIR GIBBIE & DONAL GRANT: The Baronet's Song and The Shepherd's Castle (Adventure Classic)Încă nu există evaluări
- A Head In The Cloud: Tutorials, Mini-Tutorials, Micro-Tutorials, and Appreciations From the Blog of Robert Paul WolffDe la EverandA Head In The Cloud: Tutorials, Mini-Tutorials, Micro-Tutorials, and Appreciations From the Blog of Robert Paul WolffÎncă nu există evaluări
- Dominance and Delusion: Why we do the things we doDe la EverandDominance and Delusion: Why we do the things we doEvaluare: 5 din 5 stele5/5 (1)
- Notes From The UndergroundDe la EverandNotes From The UndergroundEvaluare: 4.5 din 5 stele4.5/5 (12)
- The Development Dilemma: Security, Prosperity, and a Return to HistoryDe la EverandThe Development Dilemma: Security, Prosperity, and a Return to HistoryÎncă nu există evaluări
- The Neomercantilists: A Global Intellectual HistoryDe la EverandThe Neomercantilists: A Global Intellectual HistoryÎncă nu există evaluări
- Kalecki's Theory of DistributionDocument30 paginiKalecki's Theory of DistributionJahnavi Patil0% (1)
- Bbs Program5Document1 paginăBbs Program5api-584843593Încă nu există evaluări
- Hasnas Toward A Theory of Empirical Natural RightsDocument36 paginiHasnas Toward A Theory of Empirical Natural RightsTokyoTomÎncă nu există evaluări
- BCiMC Salaries Above 100KDocument1 paginăBCiMC Salaries Above 100KNRF_VancouverÎncă nu există evaluări
- Bates On Levels 2006Document16 paginiBates On Levels 2006Beowulf Odin SonÎncă nu există evaluări
- Essay For The Grand Inquisitor From Brothers KaramazovDocument7 paginiEssay For The Grand Inquisitor From Brothers KaramazovsoveryeasyÎncă nu există evaluări
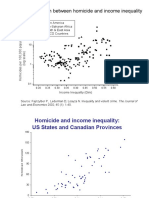
- Kate Pickett and Richard Wilkinson Presentation To The RSA. July 2010Document74 paginiKate Pickett and Richard Wilkinson Presentation To The RSA. July 2010The RSAÎncă nu există evaluări
- Michael Heinrich - An Introduction To The Three Volumes of Karl Marx - S Capital (2012)Document233 paginiMichael Heinrich - An Introduction To The Three Volumes of Karl Marx - S Capital (2012)Zoran Terzić100% (2)
- Parallelomania by Samuel SandmelDocument11 paginiParallelomania by Samuel SandmelMike WhitentonÎncă nu există evaluări
- Variational Analysis: Critical Extremals and Sturmian ExtensionsDe la EverandVariational Analysis: Critical Extremals and Sturmian ExtensionsEvaluare: 5 din 5 stele5/5 (1)
- Co-Clustering: Models, Algorithms and ApplicationsDe la EverandCo-Clustering: Models, Algorithms and ApplicationsÎncă nu există evaluări
- Semi-Simple Lie Algebras and Their RepresentationsDe la EverandSemi-Simple Lie Algebras and Their RepresentationsEvaluare: 4 din 5 stele4/5 (1)
- Agmon 1964Document58 paginiAgmon 1964CoÎncă nu există evaluări
- Articulo MetodosDocument7 paginiArticulo MetodosCesarRamÎncă nu există evaluări
- The Method of Trigonometrical Sums in the Theory of NumbersDe la EverandThe Method of Trigonometrical Sums in the Theory of NumbersÎncă nu există evaluări
- Prediction Theory and Fourier SeriesDocument39 paginiPrediction Theory and Fourier Seriesandrei ionutÎncă nu există evaluări
- Demos 016Document6 paginiDemos 016music2850Încă nu există evaluări
- Arnold Awanou 12 ADocument20 paginiArnold Awanou 12 AGerard AwanouÎncă nu există evaluări
- Linear Inequalities and Related Systems. (AM-38), Volume 38De la EverandLinear Inequalities and Related Systems. (AM-38), Volume 38Încă nu există evaluări
- (2nd Stage) Detecting Dependence I - Detecting Dependence Between Spatial ProcessesDocument52 pagini(2nd Stage) Detecting Dependence I - Detecting Dependence Between Spatial ProcessesMa GaÎncă nu există evaluări
- Agresti 1995Document10 paginiAgresti 1995Nughthoh Arfawi KurdhiÎncă nu există evaluări
- Kernel Functions and Elliptic Differential Equations in Mathematical PhysicsDe la EverandKernel Functions and Elliptic Differential Equations in Mathematical PhysicsEvaluare: 4.5 din 5 stele4.5/5 (2)
- Unitary Representations and Harmonic Analysis: An IntroductionDe la EverandUnitary Representations and Harmonic Analysis: An IntroductionÎncă nu există evaluări
- Entanglement Under SymmetryDocument16 paginiEntanglement Under SymmetrygejikeijiÎncă nu există evaluări
- Convergence and Uniformity in Topology. (AM-2), Volume 2De la EverandConvergence and Uniformity in Topology. (AM-2), Volume 2Încă nu există evaluări
- B1+ Exam MappingDocument3 paginiB1+ Exam Mappingmonika krajewskaÎncă nu există evaluări
- Character QuestionsDocument3 paginiCharacter QuestionsAaron FarmerÎncă nu există evaluări
- An Example of A Rating Scale To Q4Document4 paginiAn Example of A Rating Scale To Q4Zeeshan ch 'Hadi'Încă nu există evaluări
- The Big Table of Quantum AIDocument7 paginiThe Big Table of Quantum AIAbu Mohammad Omar Shehab Uddin AyubÎncă nu există evaluări
- (ANSI - AWS A5.31-92R) AWS A5 Committee On Filler Metal-SpecificationDocument18 pagini(ANSI - AWS A5.31-92R) AWS A5 Committee On Filler Metal-SpecificationSivaram KottaliÎncă nu există evaluări
- B4 Ethical Problems and Rules of Internet NetiquetteDocument11 paginiB4 Ethical Problems and Rules of Internet NetiquetteTarkan SararÎncă nu există evaluări
- ASN PyariViswamResumeDocument3 paginiASN PyariViswamResumeapi-27019513100% (2)
- Real-World Data Is Dirty: Data Cleansing and The Merge/Purge ProblemDocument29 paginiReal-World Data Is Dirty: Data Cleansing and The Merge/Purge Problemapi-19731161Încă nu există evaluări
- EER Model: Enhance Entity Relationship ModelDocument12 paginiEER Model: Enhance Entity Relationship ModelHaroon KhalidÎncă nu există evaluări
- Service Manual: DDX24BT, DDX340BTDocument94 paginiService Manual: DDX24BT, DDX340BTDumur SaileshÎncă nu există evaluări
- Google - (Chrome) - Default NetworkDocument21 paginiGoogle - (Chrome) - Default Networkjohnnyalves93302Încă nu există evaluări
- Practical FileDocument108 paginiPractical FileRakesh KumarÎncă nu există evaluări
- Tankless Vs TankDocument2 paginiTankless Vs TankClick's PlumbingÎncă nu există evaluări
- CasDocument2 paginiCasJamesalbert KingÎncă nu există evaluări
- TRANSLATIONDocument4 paginiTRANSLATIONGarren Jude Aquino100% (1)
- Implications of PropTechDocument107 paginiImplications of PropTechAnsar FarooqiÎncă nu există evaluări
- Creativity MCQDocument17 paginiCreativity MCQAmanVatsÎncă nu există evaluări
- Philosophical Warfare and The Shadow of IdeasDocument5 paginiPhilosophical Warfare and The Shadow of IdeasDavid MetcalfeÎncă nu există evaluări
- Java ProgrammingDocument134 paginiJava ProgrammingArt LookÎncă nu există evaluări
- UFO and PentagonDocument69 paginiUFO and PentagonNur Agustinus100% (3)
- Mathematics 10 Performance Task #1 Write The Activities in A Short Bond Paper Activities Activity 1: Go Investigate!Document2 paginiMathematics 10 Performance Task #1 Write The Activities in A Short Bond Paper Activities Activity 1: Go Investigate!Angel Grace Diego Corpuz100% (2)
- 10th Syllbus PDFDocument104 pagini10th Syllbus PDFGagandeep KaurÎncă nu există evaluări
- Risk Management Q1Document8 paginiRisk Management Q1Parth MuniÎncă nu există evaluări
- Assessment Center GuideDocument4 paginiAssessment Center GuidebilloobuttÎncă nu există evaluări
- Example of Annual Audit Planning Work ProgramDocument2 paginiExample of Annual Audit Planning Work Programrindwa100% (1)
- Gujarat Technological UniversityDocument2 paginiGujarat Technological UniversityShruti BiradarÎncă nu există evaluări
- ARCO ANDI Wayne PIB Installation and Start Up GuideDocument39 paginiARCO ANDI Wayne PIB Installation and Start Up GuidejotazunigaÎncă nu există evaluări
- Very High Frequency Omni-Directional Range: Alejandro Patt CarrionDocument21 paginiVery High Frequency Omni-Directional Range: Alejandro Patt CarrionAlejandro PattÎncă nu există evaluări
- (Type The Documen T Title) : (Year)Document18 pagini(Type The Documen T Title) : (Year)goodluck788Încă nu există evaluări
- 2013 - To and Fro. Modernism and Vernacular ArchitectureDocument246 pagini2013 - To and Fro. Modernism and Vernacular ArchitecturesusanaÎncă nu există evaluări