S-ar putea să vă placă și
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5795)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (345)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1091)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- DD640-DD620-DD160 - Overview (Customer Presentation)Document25 paginiDD640-DD620-DD160 - Overview (Customer Presentation)pcoffey2240Încă nu există evaluări
- CallRecord LogDocument12 paginiCallRecord LogShirin patel100% (2)
- Secure Coding Lecture 2: Injections, and Buffer Overflows: Benny PinkasDocument75 paginiSecure Coding Lecture 2: Injections, and Buffer Overflows: Benny PinkasSharon Y.Încă nu există evaluări
- How To Create A Secure Login Using PHP and MYSQLDocument16 paginiHow To Create A Secure Login Using PHP and MYSQLEnryu NagantÎncă nu există evaluări
- WeeklyAssignment 2Document10 paginiWeeklyAssignment 2ABINASH dashÎncă nu există evaluări
- Apache Hive Cookbook - Sample ChapterDocument27 paginiApache Hive Cookbook - Sample ChapterPackt Publishing100% (1)
- Keywords in CDocument10 paginiKeywords in CJothi LakshmiUÎncă nu există evaluări
- Introduction To File Input and OutputDocument7 paginiIntroduction To File Input and OutputLyle Andrei SotozaÎncă nu există evaluări
- MRVPN FL - OvpnDocument3 paginiMRVPN FL - OvpnSetarehÎncă nu există evaluări
- SQL Data AdapterDocument2 paginiSQL Data AdapterRajesh VhadlureÎncă nu există evaluări
- Osmotrx Vty ReferenceDocument79 paginiOsmotrx Vty ReferencelaforgeÎncă nu există evaluări
- EDUSECDocument2 paginiEDUSECViswaprem CAÎncă nu există evaluări
- CatOS To IOS Conversion Catalyst 6500kDocument46 paginiCatOS To IOS Conversion Catalyst 6500kzarandijaÎncă nu există evaluări
- SQL (Structured Query Language)Document35 paginiSQL (Structured Query Language)Chemutai JoyceÎncă nu există evaluări
- Synon BaDocument564 paginiSynon BaHanirahul Kumar0% (1)
- KCS301 Data Structure UNIT 3 Searching Sorting HashingDocument61 paginiKCS301 Data Structure UNIT 3 Searching Sorting Hashingsaumya2213215Încă nu există evaluări
- Iae1 QPDocument3 paginiIae1 QPyaboyÎncă nu există evaluări
- Over Clause and Ordered CalculationsDocument62 paginiOver Clause and Ordered CalculationsgueguessÎncă nu există evaluări
- Plantilla Reval Multipagas EncriptacionDocument2 paginiPlantilla Reval Multipagas EncriptacionJA González CastillaÎncă nu există evaluări
- The Network Protocol Cheatsheet: Riddhi SuryavanshiDocument6 paginiThe Network Protocol Cheatsheet: Riddhi SuryavanshiIgor Basquerotto de CarvalhoÎncă nu există evaluări
- C Programming - Data Structures and AlgorithmsDocument167 paginiC Programming - Data Structures and AlgorithmsreeyahlynneÎncă nu există evaluări
- Health Check QRadarDocument31 paginiHealth Check QRadartest conceptÎncă nu există evaluări
- 1101 Chapter 10 Essential Peripherals - Slide HandoutsDocument44 pagini1101 Chapter 10 Essential Peripherals - Slide HandoutsManuel MamaniÎncă nu există evaluări
- AN55-Porting Cosmic Applications To RaisonanceDocument26 paginiAN55-Porting Cosmic Applications To Raisonancemathewbasil22Încă nu există evaluări
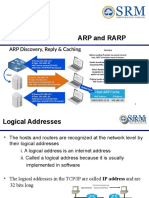
- Unit I ARP and RARPDocument37 paginiUnit I ARP and RARPMurtaza VasanwalaÎncă nu există evaluări
- RRTDocument1 paginăRRTHernanHuamanchumoÎncă nu există evaluări
- Palo Alto ChecklistDocument78 paginiPalo Alto ChecklistVenkata RamanaÎncă nu există evaluări
- Pymemcache Readthedocs Io en LatestDocument44 paginiPymemcache Readthedocs Io en LatestclaverÎncă nu există evaluări
- Bluecoat sg8100 20070523101530Document4 paginiBluecoat sg8100 20070523101530stephanefrÎncă nu există evaluări