S-ar putea să vă placă și
- Google Cloud Platform for Data Engineering: From Beginner to Data Engineer using Google Cloud PlatformDe la EverandGoogle Cloud Platform for Data Engineering: From Beginner to Data Engineer using Google Cloud PlatformEvaluare: 5 din 5 stele5/5 (1)
- Parallel Data Mining of Association RulesDocument10 paginiParallel Data Mining of Association RulesAvinash MudunuriÎncă nu există evaluări
- Data Mining ReportDocument15 paginiData Mining ReportKrishna KiranÎncă nu există evaluări
- Data Mining: A Database PerspectiveDocument19 paginiData Mining: A Database PerspectiveSijo JohnÎncă nu există evaluări
- Efficient Graph-Based Algorithms For Discovering and Maintaining Association Rules in Large DatabasesDocument24 paginiEfficient Graph-Based Algorithms For Discovering and Maintaining Association Rules in Large DatabasesAkhil Jabbar MeerjaÎncă nu există evaluări
- Chapter 01 - A Practical Introduction To Data Structures and Algorithm AnalysisDocument38 paginiChapter 01 - A Practical Introduction To Data Structures and Algorithm AnalysisReynaleen AgtaÎncă nu există evaluări
- Application of Particle Swarm Optimization To Association Rule MiningDocument11 paginiApplication of Particle Swarm Optimization To Association Rule MiningAnonymous TxPyX8cÎncă nu există evaluări
- Ingestion Layer PDFDocument11 paginiIngestion Layer PDFAnonymous 3OMRz3VCÎncă nu există evaluări
- Introduction To Data Structures and Algorithm AnalysisDocument47 paginiIntroduction To Data Structures and Algorithm AnalysismrtvuranÎncă nu există evaluări
- CS350-CH01 - Data Structures and AlgorithmsDocument34 paginiCS350-CH01 - Data Structures and AlgorithmsprafullsinghÎncă nu există evaluări
- Data Mining Association Rules Mining:: LargeDocument7 paginiData Mining Association Rules Mining:: LargeSimran Jit SinghÎncă nu există evaluări
- Operations Research Applications in The Field of Information and CommunicationDocument6 paginiOperations Research Applications in The Field of Information and CommunicationrushabhrakholiyaÎncă nu există evaluări
- Contact Me To Get Fully Solved Smu Assignments/Project/Synopsis/Exam Guide PaperDocument7 paginiContact Me To Get Fully Solved Smu Assignments/Project/Synopsis/Exam Guide PaperMrinal KalitaÎncă nu există evaluări
- Introducing Parallelism in Privacy Preserving Data Mining AlgorithmsDocument4 paginiIntroducing Parallelism in Privacy Preserving Data Mining AlgorithmsInternational Journal of computational Engineering research (IJCER)Încă nu există evaluări
- Data Mining 2-5Document4 paginiData Mining 2-5nirman kumarÎncă nu există evaluări
- Srs SubmitDocument36 paginiSrs SubmitAjit Singh KushwahÎncă nu există evaluări
- Applying K-Means Clustering Algorithm To Discover Knowledge From Insurance Dataset Using WEKA ToolDocument5 paginiApplying K-Means Clustering Algorithm To Discover Knowledge From Insurance Dataset Using WEKA TooltheijesÎncă nu există evaluări
- UNIT-1 Introduction To Data MiningDocument29 paginiUNIT-1 Introduction To Data MiningVedhaVyas MahasivaÎncă nu există evaluări
- Data Mining and Data WarehouseDocument11 paginiData Mining and Data Warehouseapi-19799369Încă nu există evaluări
- Using Network Model Represent Metadata in Data Warehouse: Sampa DasDocument3 paginiUsing Network Model Represent Metadata in Data Warehouse: Sampa DasEditor IJRITCCÎncă nu există evaluări
- Data WarehousesDocument6 paginiData WarehousespadmavathiÎncă nu există evaluări
- Performance Evaluation of Sequential and Parallel Mining of Association Rules Using Apriori AlgorithmsDocument6 paginiPerformance Evaluation of Sequential and Parallel Mining of Association Rules Using Apriori AlgorithmsputtegowdaÎncă nu există evaluări
- Ijcs 2016 0303008 PDFDocument16 paginiIjcs 2016 0303008 PDFeditorinchiefijcsÎncă nu există evaluări
- Data Mining and Data Warehouse: Raju - Qis@yahoo - Co.in Praneeth - Grp@yahoo - Co.inDocument8 paginiData Mining and Data Warehouse: Raju - Qis@yahoo - Co.in Praneeth - Grp@yahoo - Co.inapi-19799369Încă nu există evaluări
- Database Lab AssignmentDocument26 paginiDatabase Lab AssignmentSYED MUHAMMAD USAMA MASOODÎncă nu există evaluări
- DATA STRUCTURE AND ALGORITHMS NotesDocument74 paginiDATA STRUCTURE AND ALGORITHMS NotesBASSIEÎncă nu există evaluări
- Data Mining and Data Warehouse: Qis College of Engineering & Technology OngoleDocument10 paginiData Mining and Data Warehouse: Qis College of Engineering & Technology Ongoleapi-19799369Încă nu există evaluări
- Name: Donato M. Galleon III: Discussion Questions #5Document3 paginiName: Donato M. Galleon III: Discussion Questions #5Donato Galleon IIIÎncă nu există evaluări
- Unit 3 Introduction To Data Warehousing: Structure Page NosDocument21 paginiUnit 3 Introduction To Data Warehousing: Structure Page NosAkshay MathurÎncă nu există evaluări
- CBAR: An Efficient Method For Mining Association Rules: Yuh-Jiuan Tsay, Jiunn-Yann ChiangDocument7 paginiCBAR: An Efficient Method For Mining Association Rules: Yuh-Jiuan Tsay, Jiunn-Yann Chiangmahapreethi2125Încă nu există evaluări
- Big Data Framework For System Health MonitoringDocument10 paginiBig Data Framework For System Health Monitoringmalik shahzad AbdullahÎncă nu există evaluări
- Maintenance Modification Algorithms and Its Implementation On Object Oriented Data WarehouseDocument9 paginiMaintenance Modification Algorithms and Its Implementation On Object Oriented Data WarehouseRammani AdhikariÎncă nu există evaluări
- Layouts Inverted MatrixDocument10 paginiLayouts Inverted MatrixMarius_2010Încă nu există evaluări
- Time Table Scheduling in Data MiningDocument61 paginiTime Table Scheduling in Data MiningAmrit KaurÎncă nu există evaluări
- Fault Tolerant SystemsDocument43 paginiFault Tolerant Systemsmanuarnold12Încă nu există evaluări
- BigDataAnalyticsDocument36 paginiBigDataAnalyticsdeepak1892100% (1)
- Great Compiled Notes Data Mining V1Document92 paginiGreat Compiled Notes Data Mining V1MALLIKARJUN YÎncă nu există evaluări
- Datamining 2Document5 paginiDatamining 2Manoj ManuÎncă nu există evaluări
- International Refereed Journal of Engineering and Science (IRJES)Document10 paginiInternational Refereed Journal of Engineering and Science (IRJES)www.irjes.comÎncă nu există evaluări
- p132 ClosetDocument11 paginip132 Closetjnanesh582Încă nu există evaluări
- Data Mining and Database Systems: Where Is The Intersection?Document5 paginiData Mining and Database Systems: Where Is The Intersection?Juan KardÎncă nu există evaluări
- Storage and Information Management (8 It 3)Document11 paginiStorage and Information Management (8 It 3)Manmohan Singh100% (2)
- Data Mining and Data Warehouse BYDocument12 paginiData Mining and Data Warehouse BYapi-19799369100% (1)
- 100+ Data Analyst Interview QnA PDFDocument19 pagini100+ Data Analyst Interview QnA PDFArun PanneerÎncă nu există evaluări
- Hidden Patterns, Unknown Correlations, Market Trends, Customer Preferences and Other Useful Information That Can Help Organizations Make More-Informed Business DecisionsDocument4 paginiHidden Patterns, Unknown Correlations, Market Trends, Customer Preferences and Other Useful Information That Can Help Organizations Make More-Informed Business DecisionsPolukanti GouthamkrishnaÎncă nu există evaluări
- Data Mining and Warehousing: - Data Mining Has Become A Popular Buzzword But, in Fact, Promises ToDocument9 paginiData Mining and Warehousing: - Data Mining Has Become A Popular Buzzword But, in Fact, Promises ToJournal of Computer ApplicationsÎncă nu există evaluări
- Grid Computing: Advanced Web, For Computing, Collaboration and CommunicationDocument11 paginiGrid Computing: Advanced Web, For Computing, Collaboration and CommunicationMr.SANTANU BANERJEE100% (3)
- Application of Data Warehouse and Data Mining in Construction ManagementDocument12 paginiApplication of Data Warehouse and Data Mining in Construction ManagementSaiful Hadi MastorÎncă nu există evaluări
- Data Mining - Reference - 1Document91 paginiData Mining - Reference - 1Suresh SinghÎncă nu există evaluări
- Base Knowledge BasedDocument14 paginiBase Knowledge BasednagaidlÎncă nu există evaluări
- Knowledge HidingDocument37 paginiKnowledge Hidingfac fasjesÎncă nu există evaluări
- Supply Chain IntegrationDocument12 paginiSupply Chain IntegrationMarisol LopezÎncă nu există evaluări
- Module-3 (Part-2)Document46 paginiModule-3 (Part-2)sujithÎncă nu există evaluări
- Knowledge Engineering Report: Apriori AlgorithmDocument13 paginiKnowledge Engineering Report: Apriori AlgorithmEnvil_Vlie0% (1)
- NegativeDocument2 paginiNegativeSuman PanditÎncă nu există evaluări
- Datamining - Primitives - Languages - System ArchDocument50 paginiDatamining - Primitives - Languages - System ArchDrArun Kumar ChoudharyÎncă nu există evaluări
- Design Principle For Big DataDocument4 paginiDesign Principle For Big DataFirdaus AdibÎncă nu există evaluări
- CS614 FinalTerm Solved PapersDocument24 paginiCS614 FinalTerm Solved Papersahmed ilyasÎncă nu există evaluări
- Data Mining Primitives, Languages and System ArchitectureDocument64 paginiData Mining Primitives, Languages and System Architecturesureshkumar001Încă nu există evaluări
- Standard Answers For The MSC ProgrammeDocument17 paginiStandard Answers For The MSC ProgrammeTiwiÎncă nu există evaluări
- PSA Poster Project WorkbookDocument38 paginiPSA Poster Project WorkbookwalliamaÎncă nu există evaluări
- W25509 PDF EngDocument11 paginiW25509 PDF EngNidhi SinghÎncă nu există evaluări
- Physics Education Thesis TopicsDocument4 paginiPhysics Education Thesis TopicsPaperWriterServicesCanada100% (2)
- rp10 PDFDocument77 paginirp10 PDFRobson DiasÎncă nu există evaluări
- Sources of Hindu LawDocument9 paginiSources of Hindu LawKrishnaKousikiÎncă nu există evaluări
- Rom 2 - 0-11 (En)Document132 paginiRom 2 - 0-11 (En)Mara HerreraÎncă nu există evaluări
- Skills Checklist - Gastrostomy Tube FeedingDocument2 paginiSkills Checklist - Gastrostomy Tube Feedingpunam todkar100% (1)
- My Mother at 66Document6 paginiMy Mother at 66AnjanaÎncă nu există evaluări
- John L. Selzer - Merit and Degree in Webster's - The Duchess of MalfiDocument12 paginiJohn L. Selzer - Merit and Degree in Webster's - The Duchess of MalfiDivya AggarwalÎncă nu există evaluări
- Music CG 2016Document95 paginiMusic CG 2016chesterkevinÎncă nu există evaluări
- Iguana Joe's Lawsuit - September 11, 2014Document14 paginiIguana Joe's Lawsuit - September 11, 2014cindy_georgeÎncă nu există evaluări
- Mechanical Production Engineer Samphhhhhle ResumeDocument2 paginiMechanical Production Engineer Samphhhhhle ResumeAnirban MazumdarÎncă nu există evaluări
- Sandstorm Absorbent SkyscraperDocument4 paginiSandstorm Absorbent SkyscraperPardisÎncă nu există evaluări
- Neonatal Mortality - A Community ApproachDocument13 paginiNeonatal Mortality - A Community ApproachJalam Singh RathoreÎncă nu există evaluări
- Chapter 23Document9 paginiChapter 23Javier Chuchullo TitoÎncă nu există evaluări
- HatfieldDocument33 paginiHatfieldAlex ForrestÎncă nu există evaluări
- LP For EarthquakeDocument6 paginiLP For Earthquakejelena jorgeoÎncă nu există evaluări
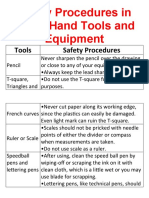
- Safety Procedures in Using Hand Tools and EquipmentDocument12 paginiSafety Procedures in Using Hand Tools and EquipmentJan IcejimenezÎncă nu există evaluări
- SweetenersDocument23 paginiSweetenersNur AfifahÎncă nu există evaluări
- Comparison Between CompetitorsDocument2 paginiComparison Between Competitorsritesh singhÎncă nu există evaluări
- Bolt Grade Markings and Strength ChartDocument2 paginiBolt Grade Markings and Strength ChartGregory GaschteffÎncă nu există evaluări
- Determination Rules SAP SDDocument2 paginiDetermination Rules SAP SDkssumanthÎncă nu există evaluări
- Quarter 1 - Module 1Document31 paginiQuarter 1 - Module 1Roger Santos Peña75% (4)
- Pityriasis VersicolorDocument10 paginiPityriasis Versicolorketty putriÎncă nu există evaluări
- Dermatology Skin in Systemic DiseaseDocument47 paginiDermatology Skin in Systemic DiseaseNariska CooperÎncă nu există evaluări
- Sept Dec 2018 Darjeeling CoDocument6 paginiSept Dec 2018 Darjeeling Conajihah zakariaÎncă nu există evaluări
- Congenital Cardiac Disease: A Guide To Evaluation, Treatment and Anesthetic ManagementDocument87 paginiCongenital Cardiac Disease: A Guide To Evaluation, Treatment and Anesthetic ManagementJZÎncă nu există evaluări
- Test 51Document7 paginiTest 51Nguyễn Hiền Giang AnhÎncă nu există evaluări
- Illustrating An Experiment, Outcome, Sample Space and EventDocument9 paginiIllustrating An Experiment, Outcome, Sample Space and EventMarielle MunarÎncă nu există evaluări