S-ar putea să vă placă și
- Five Steps of Hypothesis TestingDocument3 paginiFive Steps of Hypothesis Testingjervrgbp15Încă nu există evaluări
- Is Important Because:: The Normal DistributionDocument19 paginiIs Important Because:: The Normal DistributionRohanPuthalathÎncă nu există evaluări
- CH 11 - Small Sample TestDocument8 paginiCH 11 - Small Sample TesthehehaswalÎncă nu există evaluări
- Chapter 8 and 9Document7 paginiChapter 8 and 9Ellii YouTube channelÎncă nu există evaluări
- What Is Hypothesis TestingDocument32 paginiWhat Is Hypothesis TestingNasir Mehmood AryaniÎncă nu există evaluări
- STAT1301 Notes: Steps For Scientific StudyDocument31 paginiSTAT1301 Notes: Steps For Scientific StudyjohnÎncă nu există evaluări
- StatisticsDocument5 paginiStatisticsjohn ashley martinezÎncă nu există evaluări
- An Introduction To T-Tests: Statistical Test Means Hypothesis TestingDocument8 paginiAn Introduction To T-Tests: Statistical Test Means Hypothesis Testingshivani100% (1)
- Hypothesis TestingDocument44 paginiHypothesis TestingRudraksh AgrawalÎncă nu există evaluări
- SRM Assignement: 1. T-TestDocument5 paginiSRM Assignement: 1. T-TestGurjit SinghÎncă nu există evaluări
- Inferential Statistics For Data ScienceDocument10 paginiInferential Statistics For Data Sciencersaranms100% (1)
- ST 511 Self NotesDocument6 paginiST 511 Self NotesvikasptkÎncă nu există evaluări
- Assignment AnswersDocument5 paginiAssignment AnswersKiran KumarÎncă nu există evaluări
- Decision TheoryDocument101 paginiDecision TheoryWaqas ImranÎncă nu există evaluări
- Data Science Interview Preparation (30 Days of Interview Preparation)Document27 paginiData Science Interview Preparation (30 Days of Interview Preparation)Satyavaraprasad BallaÎncă nu există evaluări
- Testing of Hypothesis HypothesisDocument32 paginiTesting of Hypothesis HypothesisAbhishek JaiswalÎncă nu există evaluări
- Hypothesis Testing 15pagesDocument15 paginiHypothesis Testing 15pagesAravindan RÎncă nu există evaluări
- Unit 3 HypothesisDocument41 paginiUnit 3 Hypothesisabhinavkapoor101Încă nu există evaluări
- Basic Statistics For Data ScienceDocument45 paginiBasic Statistics For Data ScienceBalasaheb ChavanÎncă nu există evaluări
- Statistics & Probability Q4 - Week 3-4Document16 paginiStatistics & Probability Q4 - Week 3-4Rayezeus Jaiden Del RosarioÎncă nu există evaluări
- Forms of Test StatisticDocument31 paginiForms of Test StatisticJackielou TrongcosoÎncă nu există evaluări
- Notes On Sampling and Hypothesis TestingDocument10 paginiNotes On Sampling and Hypothesis Testinghunt_pgÎncă nu există evaluări
- Unit 4 Basic StatisticsDocument11 paginiUnit 4 Basic Statisticsshimmy yayÎncă nu există evaluări
- ML Unit2 SimpleLinearRegression pdf-60-97Document38 paginiML Unit2 SimpleLinearRegression pdf-60-97Deepali KoiralaÎncă nu există evaluări
- Basic Statitical Inference (Lecture3)Document8 paginiBasic Statitical Inference (Lecture3)KanwalÎncă nu există evaluări
- CIVL101: Lecture-27-28 Mathematical Statistics-Test of SignificanceDocument30 paginiCIVL101: Lecture-27-28 Mathematical Statistics-Test of SignificanceRajesh KabiÎncă nu există evaluări
- Test of HypothesisDocument85 paginiTest of HypothesisJyoti Prasad Sahu64% (11)
- L7 Hypothesis TestingDocument59 paginiL7 Hypothesis Testingمصطفى سامي شهيد لفتهÎncă nu există evaluări
- Mann - Whitney Test - Nonparametric T TestDocument18 paginiMann - Whitney Test - Nonparametric T TestMahiraÎncă nu există evaluări
- Engineering Data Analysis Probability: Probability Is A Measure Quantifying The Likelihood That Events Will OccurDocument8 paginiEngineering Data Analysis Probability: Probability Is A Measure Quantifying The Likelihood That Events Will OccurCharlotte FerriolÎncă nu există evaluări
- Allama Iqbal Open University, Islamabad: (Department of Secondary Teacher Education)Document7 paginiAllama Iqbal Open University, Islamabad: (Department of Secondary Teacher Education)Shakeel BalochÎncă nu există evaluări
- What Is A TDocument5 paginiWhat Is A TkamransÎncă nu există evaluări
- Assignment 2Document19 paginiAssignment 2Ehsan KarimÎncă nu există evaluări
- Sas ProcsDocument8 paginiSas ProcsPrasad TvsnvÎncă nu există evaluări
- Biostat - Group 3Document42 paginiBiostat - Group 3Jasmin JimenezÎncă nu există evaluări
- Inferential Statistics: ProbabilityDocument5 paginiInferential Statistics: ProbabilityAhmed NawazÎncă nu există evaluări
- Hypothesis Testing. BCApptxDocument34 paginiHypothesis Testing. BCApptxshedotuoyÎncă nu există evaluări
- Statistics - Own CompilationDocument20 paginiStatistics - Own Compilationbogdan_de_romaniaÎncă nu există evaluări
- Is Important Because:: TECH 6300 Introduction To Statistical Inference The Normal DistributionDocument19 paginiIs Important Because:: TECH 6300 Introduction To Statistical Inference The Normal DistributionGellie Vale T. Managbanag100% (1)
- Hypothesis Testing Statistical InferencesDocument10 paginiHypothesis Testing Statistical InferencesReaderÎncă nu există evaluări
- Lecture 27/chapters 22 & 23: Hypothesis Tests For MeansDocument20 paginiLecture 27/chapters 22 & 23: Hypothesis Tests For MeansSAIRITHISH SÎncă nu există evaluări
- Testing of HypothesisDocument37 paginiTesting of HypothesisSiddharth Bahri67% (3)
- Biostatistics NotesDocument6 paginiBiostatistics Notesdeepanjan sarkarÎncă nu există evaluări
- Lecture Notes ON Parametric & Non-Parametric Tests FOR Social Scientists/ Participants OF Research Metodology Workshop Bbau, LucknowDocument19 paginiLecture Notes ON Parametric & Non-Parametric Tests FOR Social Scientists/ Participants OF Research Metodology Workshop Bbau, LucknowDiwakar RajputÎncă nu există evaluări
- BRM PresentationDocument25 paginiBRM PresentationHeena Abhyankar BhandariÎncă nu există evaluări
- Chapter No. 08 Fundamental Sampling Distributions and Data Descriptions - 02 (Presentation)Document91 paginiChapter No. 08 Fundamental Sampling Distributions and Data Descriptions - 02 (Presentation)Sahib Ullah MukhlisÎncă nu există evaluări
- Hypothesis Testing Vince ReganzDocument9 paginiHypothesis Testing Vince ReganzVince Edward RegañonÎncă nu există evaluări
- Untitled 472Document13 paginiUntitled 472papanombaÎncă nu există evaluări
- Measures of Central TendencyDocument4 paginiMeasures of Central TendencydeepikaajhaÎncă nu există evaluări
- Student S T Statistic: Test For Equality of Two Means Test For Value of A Single MeanDocument35 paginiStudent S T Statistic: Test For Equality of Two Means Test For Value of A Single MeanAmaal GhaziÎncă nu există evaluări
- Tests of Significance Notes PDFDocument12 paginiTests of Significance Notes PDFManish KÎncă nu există evaluări
- Biostatistics Notes: Descriptive StatisticsDocument16 paginiBiostatistics Notes: Descriptive StatisticsRuvimbo T ShumbaÎncă nu există evaluări
- The Central Limit Theorem and Hypothesis Testing FinalDocument29 paginiThe Central Limit Theorem and Hypothesis Testing FinalMichelleneChenTadle100% (1)
- Explanation For The Statistical Tools UsedDocument4 paginiExplanation For The Statistical Tools UsedgeethamadhuÎncă nu există evaluări
- Appendix ADocument7 paginiAppendix AuzznÎncă nu există evaluări
- Z Test FormulaDocument6 paginiZ Test FormulaE-m FunaÎncă nu există evaluări
- Stats Hypothesis TestingDocument3 paginiStats Hypothesis TestingLiana BaluyotÎncă nu există evaluări
- Dec JanDocument6 paginiDec Janmadhujayan100% (1)
- CAA Safety Plan 2011 To 2013Document46 paginiCAA Safety Plan 2011 To 2013cookie01543Încă nu există evaluări
- Final WMS2023 HairdressingDocument15 paginiFinal WMS2023 HairdressingMIRAWATI SAHIBÎncă nu există evaluări
- 1916 South American Championship Squads - WikipediaDocument6 pagini1916 South American Championship Squads - WikipediaCristian VillamayorÎncă nu există evaluări
- Who Trs 993 Web FinalDocument284 paginiWho Trs 993 Web FinalAnonymous 6OPLC9UÎncă nu există evaluări
- ADC of PIC MicrocontrollerDocument4 paginiADC of PIC Microcontrollerkillbill100% (2)
- Math 9 Quiz 4Document3 paginiMath 9 Quiz 4Lin SisombounÎncă nu există evaluări
- Kosher Leche Descremada Dairy America Usa Planta TiptonDocument2 paginiKosher Leche Descremada Dairy America Usa Planta Tiptontania SaezÎncă nu există evaluări
- Biology Key Stage 4 Lesson PDFDocument4 paginiBiology Key Stage 4 Lesson PDFAleesha AshrafÎncă nu există evaluări
- What Is Universe?Document19 paginiWhat Is Universe?Ruben M. VerdidaÎncă nu există evaluări
- Previous Year Questions - Macro Economics - XIIDocument16 paginiPrevious Year Questions - Macro Economics - XIIRituraj VermaÎncă nu există evaluări
- Espree I Class Korr3Document22 paginiEspree I Class Korr3hgaucherÎncă nu există evaluări
- CS-6777 Liu AbsDocument103 paginiCS-6777 Liu AbsILLA PAVAN KUMAR (PA2013003013042)Încă nu există evaluări
- P 348Document196 paginiP 348a123456978Încă nu există evaluări
- To Study Customer Relationship Management in Big BazaarDocument45 paginiTo Study Customer Relationship Management in Big BazaarAbhi KengaleÎncă nu există evaluări
- Binge Eating Disorder ANNADocument12 paginiBinge Eating Disorder ANNAloloasbÎncă nu există evaluări
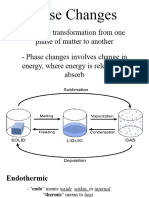
- General Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveDocument19 paginiGeneral Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveJolo Allexice R. PinedaÎncă nu există evaluări
- Open Letter To Hon. Nitin Gadkari On Pothole Problem On National and Other Highways in IndiaDocument3 paginiOpen Letter To Hon. Nitin Gadkari On Pothole Problem On National and Other Highways in IndiaProf. Prithvi Singh KandhalÎncă nu există evaluări
- 1995 Biology Paper I Marking SchemeDocument13 pagini1995 Biology Paper I Marking Schemetramysss100% (2)
- Standard Test Methods For Rheological Properties of Non-Newtonian Materials by Rotational (Brookfield Type) ViscometerDocument8 paginiStandard Test Methods For Rheological Properties of Non-Newtonian Materials by Rotational (Brookfield Type) ViscometerRodrigo LopezÎncă nu există evaluări
- Elpodereso Case AnalysisDocument3 paginiElpodereso Case AnalysisUsama17100% (2)
- Open Source NetworkingDocument226 paginiOpen Source NetworkingyemenlinuxÎncă nu există evaluări
- Cam 18 Test 3 ListeningDocument6 paginiCam 18 Test 3 ListeningKhắc Trung NguyễnÎncă nu există evaluări
- ENT 300 Individual Assessment-Personal Entrepreneurial CompetenciesDocument8 paginiENT 300 Individual Assessment-Personal Entrepreneurial CompetenciesAbu Ammar Al-hakimÎncă nu există evaluări
- Steel Design Fourth Edition William T Segui Solution Manual 1Document11 paginiSteel Design Fourth Edition William T Segui Solution Manual 1RazaÎncă nu există evaluări
- Automatic Gearbox ZF 4HP 20Document40 paginiAutomatic Gearbox ZF 4HP 20Damien Jorgensen100% (3)
- Convection Transfer EquationsDocument9 paginiConvection Transfer EquationsA.N.M. Mominul Islam MukutÎncă nu există evaluări
- Famous Little Red Book SummaryDocument6 paginiFamous Little Red Book SummaryMatt MurdockÎncă nu există evaluări
- Derebe TekesteDocument75 paginiDerebe TekesteAbinet AdemaÎncă nu există evaluări
- 928 Diagnostics Manual v2.7Document67 pagini928 Diagnostics Manual v2.7Roger Sego100% (2)