S-ar putea să vă placă și
- Pipelining and Instruction Level Parallelism: 5 Steps of MIPS DatapathDocument12 paginiPipelining and Instruction Level Parallelism: 5 Steps of MIPS DatapathNgat SkyÎncă nu există evaluări
- Pipeline Hazards ExplainedDocument27 paginiPipeline Hazards ExplainedAhmed NabilÎncă nu există evaluări
- Pipeline Hazards. PresentationDocument20 paginiPipeline Hazards. PresentationReaderRRGHT100% (1)
- HRY-312 Computer Organization Introduction To PipeliningDocument30 paginiHRY-312 Computer Organization Introduction To Pipelininggami2Încă nu există evaluări
- Appendix ADocument93 paginiAppendix AzeewoxÎncă nu există evaluări
- Pipeline HazardsDocument94 paginiPipeline HazardsManasa RavelaÎncă nu există evaluări
- UNIT-5: Pipeline and Vector ProcessingDocument63 paginiUNIT-5: Pipeline and Vector ProcessingAkash KankariaÎncă nu există evaluări
- Pipeline HazardsDocument39 paginiPipeline HazardsPranidhi RajvanshiÎncă nu există evaluări
- Co - Unit Ii - IiDocument34 paginiCo - Unit Ii - Iiy22cd125Încă nu există evaluări
- Data Hazards: Danger!Danger!Danger!Document7 paginiData Hazards: Danger!Danger!Danger!Abdullah Ashraf ElkordyÎncă nu există evaluări
- Week 4 - PipeliningDocument44 paginiWeek 4 - Pipeliningdress dressÎncă nu există evaluări
- Embedded Systems Design: Pipelining and Instruction SchedulingDocument48 paginiEmbedded Systems Design: Pipelining and Instruction SchedulingMisbah Sajid ChaudhryÎncă nu există evaluări
- Multiple Issue Processors ExplainedDocument40 paginiMultiple Issue Processors ExplainedrazorviperÎncă nu există evaluări
- Pipelinehazard For ClassDocument61 paginiPipelinehazard For ClassJayanta SikdarÎncă nu există evaluări
- Lecture 7: Pipelining Review and HazardsDocument121 paginiLecture 7: Pipelining Review and HazardsdoomachaleyÎncă nu există evaluări
- The Big Picture: Requirements Algorithms Prog. Lang./Os Isa Uarch Circuit DeviceDocument60 paginiThe Big Picture: Requirements Algorithms Prog. Lang./Os Isa Uarch Circuit DevicevshlvvkÎncă nu există evaluări
- Slides Chapter 6 PipeliningDocument60 paginiSlides Chapter 6 PipeliningWin WarÎncă nu există evaluări
- Pipelining and Vector ProcessingDocument28 paginiPipelining and Vector ProcessingBinuVargisÎncă nu există evaluări
- MULTIcycle OPERATIONSDocument24 paginiMULTIcycle OPERATIONSi_2loveu3235Încă nu există evaluări
- Pipeline Processor DesignDocument89 paginiPipeline Processor Designkumarguptav91Încă nu există evaluări
- Pipelining Preview: Basics & ChallengesDocument75 paginiPipelining Preview: Basics & ChallengesdoomachaleyÎncă nu există evaluări
- Pipeline HazardsDocument94 paginiPipeline HazardsdrawthelinemiruÎncă nu există evaluări
- CAO Pipelining LectureDocument50 paginiCAO Pipelining LectureSabareesh MuralidharanÎncă nu există evaluări
- Solution For Exam QuestionsDocument36 paginiSolution For Exam QuestionsakilantÎncă nu există evaluări
- Instruction PipelineDocument27 paginiInstruction PipelineEswin AngelÎncă nu există evaluări
- 05 TimingDocument7 pagini05 TimingAditya SoniÎncă nu există evaluări
- Chap4 PipeliningDocument39 paginiChap4 PipeliningAmanda Judy AndradeÎncă nu există evaluări
- Lec 24Document3 paginiLec 24BerkanErolÎncă nu există evaluări
- Pipelining and ParallelismDocument41 paginiPipelining and ParallelismPratham GuptaÎncă nu există evaluări
- EE (CE) 6304 Computer Architecture Lecture #2 (8/28/13)Document35 paginiEE (CE) 6304 Computer Architecture Lecture #2 (8/28/13)Vishal MehtaÎncă nu există evaluări
- Chapter6 - PipeliningDocument61 paginiChapter6 - PipeliningNimmy MariamÎncă nu există evaluări
- Chapter6 - PipeliningDocument61 paginiChapter6 - PipeliningPrakash SubramanianÎncă nu există evaluări
- ch09 Morris ManoDocument15 paginich09 Morris ManoYogita Negi RawatÎncă nu există evaluări
- Low-Voltage Rad-Hard 32-Bit Sparc Embedded Processor TSC695FL PreliminaryDocument42 paginiLow-Voltage Rad-Hard 32-Bit Sparc Embedded Processor TSC695FL Preliminaryjluis57Încă nu există evaluări
- Reducing Pipeline Branch PenaltiesDocument4 paginiReducing Pipeline Branch PenaltiesSwagato MondalÎncă nu există evaluări
- Module1 UPDDocument72 paginiModule1 UPDZhanzhi LiuÎncă nu există evaluări
- Design For TestDocument4 paginiDesign For TestDivya PatelÎncă nu există evaluări
- Pipelining Pipelining Characteristics of Pipelining Clocks and Latches 5 Stages of Pipelining Hazards Loads / Stores Risc and CiscDocument12 paginiPipelining Pipelining Characteristics of Pipelining Clocks and Latches 5 Stages of Pipelining Hazards Loads / Stores Risc and CiscKelvinÎncă nu există evaluări
- What is Pipelining: Overlapping Instruction ExecutionDocument47 paginiWhat is Pipelining: Overlapping Instruction ExecutionBijay MishraÎncă nu există evaluări
- Superscalar Processors: What Is A Superscalar Architecture?Document9 paginiSuperscalar Processors: What Is A Superscalar Architecture?Venkatesh NarlaÎncă nu există evaluări
- 7 CLK Tree SynthesisDocument64 pagini7 CLK Tree Synthesisdharma_panga8217100% (1)
- Unit-V: Performance Enhancement TechinquesDocument61 paginiUnit-V: Performance Enhancement Techinqueslaalan jiÎncă nu există evaluări
- ARM ProcessorDocument46 paginiARM Processoryixexi7070Încă nu există evaluări
- Chapter 6 - PipeliningDocument61 paginiChapter 6 - PipeliningShravani ShravzÎncă nu există evaluări
- Instruction Pipelining (Ii) : Reducing Pipeline Branch PenaltiesDocument4 paginiInstruction Pipelining (Ii) : Reducing Pipeline Branch Penaltiesdsvidhya123Încă nu există evaluări
- Scan Path DesignDocument54 paginiScan Path DesignGowtham HariÎncă nu există evaluări
- Pipeline - Instr - Super BranchDocument48 paginiPipeline - Instr - Super BranchSHEENA YÎncă nu există evaluări
- ILP - Appendix C PDFDocument52 paginiILP - Appendix C PDFDhananjay JahagirdarÎncă nu există evaluări
- Vasu DFTDocument28 paginiVasu DFTsenthilkumarÎncă nu există evaluări
- PIPELINING INSTRUCTIONS IN C5X PROCESSORSDocument21 paginiPIPELINING INSTRUCTIONS IN C5X PROCESSORSB11 Aswathy SureshÎncă nu există evaluări
- Topic2c Ss DynamicschedulingDocument94 paginiTopic2c Ss DynamicschedulingCalam1tousÎncă nu există evaluări
- FINAL PresentationDocument31 paginiFINAL Presentationsrinithi20032005Încă nu există evaluări
- Instruction PipelineDocument16 paginiInstruction PipelineRamya RamasubramanianÎncă nu există evaluări
- Pipelining Basics & Pipeline HazardsDocument77 paginiPipelining Basics & Pipeline HazardsdoomachaleyÎncă nu există evaluări
- unit41Document87 paginiunit41Arvind VishnubhatlaÎncă nu există evaluări
- All-Digital Frequency Synthesizer in Deep-Submicron CMOSDe la EverandAll-Digital Frequency Synthesizer in Deep-Submicron CMOSÎncă nu există evaluări
- Transistor Electronics: Use of Semiconductor Components in Switching OperationsDe la EverandTransistor Electronics: Use of Semiconductor Components in Switching OperationsEvaluare: 1 din 5 stele1/5 (1)
- Breathing Air System Performance QualificationDocument11 paginiBreathing Air System Performance QualificationCHALLA ANITHA100% (1)
- Buried Pipes in OLGADocument5 paginiBuried Pipes in OLGAmotalebyÎncă nu există evaluări
- NDIR Type Infrared Gas Analyzer Type ZKJ-3Document97 paginiNDIR Type Infrared Gas Analyzer Type ZKJ-3Yoga SanÎncă nu există evaluări
- XPol 806-960MHz 90° Fixed Tilt Sector Panel AntennaDocument1 paginăXPol 806-960MHz 90° Fixed Tilt Sector Panel AntennaArif Noviardiansyah100% (1)
- T 2 ReviewDocument5 paginiT 2 ReviewAYA707Încă nu există evaluări
- Ec Council Certified Security Analyst Ecsa v8 PDFDocument5 paginiEc Council Certified Security Analyst Ecsa v8 PDFJunaid Habibullaha0% (1)
- Bearing Life CycleDocument2 paginiBearing Life CyclemoerkerkÎncă nu există evaluări
- Price ListDocument141 paginiPrice ListAriane Llantero0% (1)
- Calculation Sheet: Perunding Nusajasa SDN BHDDocument7 paginiCalculation Sheet: Perunding Nusajasa SDN BHDSarahLukakuÎncă nu există evaluări
- Dam Break AnalysisDocument18 paginiDam Break AnalysisBushra UmerÎncă nu există evaluări
- 1 Conductor Characteristics PDFDocument20 pagini1 Conductor Characteristics PDFjaimeÎncă nu există evaluări
- PACSystemsRX3i CS GFA559G (2010)Document4 paginiPACSystemsRX3i CS GFA559G (2010)Omar Alfredo Del CastilloÎncă nu există evaluări
- User Manual of Joinchamp Dental Unit 2022Document54 paginiUser Manual of Joinchamp Dental Unit 2022Renjun hwangÎncă nu există evaluări
- CE8395 QB - by WWW - Easyengineering.net 1Document18 paginiCE8395 QB - by WWW - Easyengineering.net 1sureshkumarÎncă nu există evaluări
- Chinese Military Aircraft and MissilesDocument69 paginiChinese Military Aircraft and Missilesjb2ookworm92% (12)
- Otating Ontrol Evices: T M S ADocument11 paginiOtating Ontrol Evices: T M S ANeme VasquesÎncă nu există evaluări
- 9/11 FAA Transcript Mentioning Hijacked Airliners, in Particular United 175Document12 pagini9/11 FAA Transcript Mentioning Hijacked Airliners, in Particular United 1759/11 Document ArchiveÎncă nu există evaluări
- ECEN 310 Tutorial 5Document7 paginiECEN 310 Tutorial 5Haris Ãlï0% (1)
- Valmet HP Cleaning System For Pulp FiltersDocument2 paginiValmet HP Cleaning System For Pulp FiltersnotengofffÎncă nu există evaluări
- Vlsi DesignDocument2 paginiVlsi DesignXXXÎncă nu există evaluări
- Glycol Dehydration UnitDocument11 paginiGlycol Dehydration UnitarispriyatmonoÎncă nu există evaluări
- TSC List of Correspondents 201711 PDFDocument180 paginiTSC List of Correspondents 201711 PDFbaroon1234Încă nu există evaluări
- Vertical VTP Pump enDocument8 paginiVertical VTP Pump enJorgeÎncă nu există evaluări
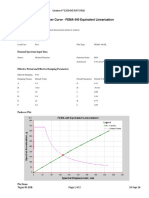
- FEMA 440 equivalent linearization pushover analysisDocument2 paginiFEMA 440 equivalent linearization pushover analysisAdam JrÎncă nu există evaluări
- Non-powered Fiberglass Whips and MountsDocument2 paginiNon-powered Fiberglass Whips and MountsKateÎncă nu există evaluări
- PDF Table ExtractorDocument17 paginiPDF Table ExtractorJaneÎncă nu există evaluări
- Make Noise Soundhack Erbe-Verb: Reverb FX ModuleDocument1 paginăMake Noise Soundhack Erbe-Verb: Reverb FX ModuleAghzuiÎncă nu există evaluări
- Digestive Chamber: Scale NTSDocument1 paginăDigestive Chamber: Scale NTSRomeo Beding Densen Jr.Încă nu există evaluări
- Thermodynamic Properties of Lithium Bromide Water Solutions at High TemperaturesDocument17 paginiThermodynamic Properties of Lithium Bromide Water Solutions at High TemperaturesAnonymous 7IKdlmÎncă nu există evaluări
- LCA Training PackageDocument57 paginiLCA Training PackageSilvia PolliniÎncă nu există evaluări