S-ar putea să vă placă și
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Roman Catholic Bishop of Jaro v. Dela PenaDocument2 paginiRoman Catholic Bishop of Jaro v. Dela PenaBeltran KathÎncă nu există evaluări
- What Is Innovation A ReviewDocument33 paginiWhat Is Innovation A ReviewAnonymous EnIdJOÎncă nu există evaluări
- Roman Catholic of Aklan Vs Mun of Aklan FULL TEXTDocument33 paginiRoman Catholic of Aklan Vs Mun of Aklan FULL TEXTDessa Ruth ReyesÎncă nu există evaluări
- Zoe LeonardDocument9 paginiZoe LeonardSandro Alves SilveiraÎncă nu există evaluări
- Chris Baeza: ObjectiveDocument2 paginiChris Baeza: Objectiveapi-283893712Încă nu există evaluări
- Art of Data ScienceDocument159 paginiArt of Data Sciencepratikshr192% (12)
- Doloran Auxilliary PrayersDocument4 paginiDoloran Auxilliary PrayersJosh A.Încă nu există evaluări
- Chemistry Chapter SummariesDocument23 paginiChemistry Chapter SummariesHayley AndersonÎncă nu există evaluări
- 4.1 Genetic Counselling 222Document12 pagini4.1 Genetic Counselling 222Sahar JoshÎncă nu există evaluări
- Kierkegaard, S - Three Discourses On Imagined Occasions (Augsburg, 1941) PDFDocument129 paginiKierkegaard, S - Three Discourses On Imagined Occasions (Augsburg, 1941) PDFtsuphrawstyÎncă nu există evaluări
- Breathing: Joshua, Youssef, and ApolloDocument28 paginiBreathing: Joshua, Youssef, and ApolloArvinth Guna SegaranÎncă nu există evaluări
- Ingles Nivel 2Document119 paginiIngles Nivel 2Perla Cortes100% (1)
- Pugh MatrixDocument18 paginiPugh MatrixSulaiman Khan0% (1)
- Adult Consensual SpankingDocument21 paginiAdult Consensual Spankingswl156% (9)
- GEHealthcare Brochure - Discovery CT590 RT PDFDocument12 paginiGEHealthcare Brochure - Discovery CT590 RT PDFAnonymous ArdclHUOÎncă nu există evaluări
- Vijay Law Series List of Publications - 2014: SN Subject/Title Publisher Year IsbnDocument3 paginiVijay Law Series List of Publications - 2014: SN Subject/Title Publisher Year IsbnSabya Sachee Rai0% (2)
- 10 Problems of Philosophy EssayDocument3 pagini10 Problems of Philosophy EssayRandy MarshÎncă nu există evaluări
- Modern Prometheus Editing The HumanDocument399 paginiModern Prometheus Editing The HumanHARTK 70Încă nu există evaluări
- Basic Trigonometric FunctionDocument34 paginiBasic Trigonometric FunctionLony PatalÎncă nu există evaluări
- Gamify Your Classroom - A Field Guide To Game-Based Learning, Revised EditionDocument372 paginiGamify Your Classroom - A Field Guide To Game-Based Learning, Revised EditionCuong Tran VietÎncă nu există evaluări
- Ocr Graphics Gcse CourseworkDocument6 paginiOcr Graphics Gcse Courseworkzys0vemap0m3100% (2)
- WaveDocument1 paginăWavejimbieÎncă nu există evaluări
- Resume UngerDocument2 paginiResume UngerMichelle ClarkÎncă nu există evaluări
- Physics Waves MCQDocument6 paginiPhysics Waves MCQAyan GhoshÎncă nu există evaluări
- Overall Structure and Stock Phrase TemplateDocument16 paginiOverall Structure and Stock Phrase Templatesangeetha Bajanthri C100% (1)
- Adjective Clauses: Relative Pronouns & Relative ClausesDocument4 paginiAdjective Clauses: Relative Pronouns & Relative ClausesJaypee MelendezÎncă nu există evaluări
- EmTech TG Acad v5 112316Document87 paginiEmTech TG Acad v5 112316Arvin Barrientos Bernesto67% (3)
- Question No. 2: (Type Here)Document5 paginiQuestion No. 2: (Type Here)temestruc71Încă nu există evaluări
- FR-A800 Plus For Roll To RollDocument40 paginiFR-A800 Plus For Roll To RollCORTOCIRCUITANTEÎncă nu există evaluări
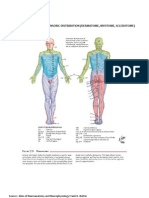
- Dermatome, Myotome, SclerotomeDocument4 paginiDermatome, Myotome, SclerotomeElka Rifqah100% (3)