S-ar putea să vă placă și
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (890)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Lte Call Flow GuideDocument34 paginiLte Call Flow Guiderahuls256100% (6)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- Katz Buonincontro, J., & Anderson, R. C. (2018) - A Review of Articles Using Observation Methods To Study Creativity in Education (1980-2018)Document18 paginiKatz Buonincontro, J., & Anderson, R. C. (2018) - A Review of Articles Using Observation Methods To Study Creativity in Education (1980-2018)dulceÎncă nu există evaluări
- Sculpture Special EditionDocument59 paginiSculpture Special EditionCollect ArtÎncă nu există evaluări
- Storage VMWare LinuxDocument7 paginiStorage VMWare LinuxSomu DasÎncă nu există evaluări
- ASG DAMA Data GovernanceDocument25 paginiASG DAMA Data GovernanceWebVP_DAMARCÎncă nu există evaluări
- Capacity CalculationDocument13 paginiCapacity CalculationPradeepÎncă nu există evaluări
- Capacity CalculationDocument13 paginiCapacity CalculationPradeepÎncă nu există evaluări
- AWS Certified Solutions Architect - AssociateDocument128 paginiAWS Certified Solutions Architect - AssociateMoe Kaungkin80% (5)
- Unit-Vi Hive Hadoop & Big DataDocument24 paginiUnit-Vi Hive Hadoop & Big DataAbhay Dabhade100% (1)
- MSIT 116A Advanced Management Information SystemDocument182 paginiMSIT 116A Advanced Management Information SystemErr3350% (2)
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument58 paginiExamples of Continuous Probability Distributions:: The Normal and Standard NormalupasanamohantyÎncă nu există evaluări
- KPS: Teori ConstraintDocument10 paginiKPS: Teori ConstraintPaRaDoX eLaKSaMaNaÎncă nu există evaluări
- JITfinalDocument32 paginiJITfinalPradeepÎncă nu există evaluări
- LR Guide: Key Concepts for Logistic Regression ModelsDocument29 paginiLR Guide: Key Concepts for Logistic Regression ModelsPradeepÎncă nu există evaluări
- Conditional RegressionDocument7 paginiConditional RegressionPradeepÎncă nu există evaluări
- Thread Scheduling and DispatchingDocument75 paginiThread Scheduling and DispatchingPradeepÎncă nu există evaluări
- Logistic Regression Predicts Binge Drinking from Facebook UseDocument28 paginiLogistic Regression Predicts Binge Drinking from Facebook UsePradeepÎncă nu există evaluări
- JITfinalDocument32 paginiJITfinalPradeepÎncă nu există evaluări
- S Tatistical Tolerance Synthesis Using Distribution Function ZonesDocument12 paginiS Tatistical Tolerance Synthesis Using Distribution Function ZonesPradeepÎncă nu există evaluări
- Quality GuruDocument53 paginiQuality Gurutehky63Încă nu există evaluări
- IMS Partners with JSTOR to Preserve Annals of Math StatsDocument12 paginiIMS Partners with JSTOR to Preserve Annals of Math StatsPradeepÎncă nu există evaluări
- Mantel-Haenszel Test1Document1 paginăMantel-Haenszel Test1PradeepÎncă nu există evaluări
- Lecture 4Document45 paginiLecture 4PradeepÎncă nu există evaluări
- Lecture 4Document45 paginiLecture 4PradeepÎncă nu există evaluări
- SharemarketDocument7 paginiSharemarketerganeshÎncă nu există evaluări
- Statistical Tests PDFDocument7 paginiStatistical Tests PDFPradeepÎncă nu există evaluări
- 76754Document9 pagini76754pkj009Încă nu există evaluări
- ANOVA701Document55 paginiANOVA701PradeepÎncă nu există evaluări
- ANOVA701Document55 paginiANOVA701PradeepÎncă nu există evaluări
- Graham 1Document5 paginiGraham 1SANUÎncă nu există evaluări
- Aggregate Planning With Learning Curve Productivity : BackgroundDocument13 paginiAggregate Planning With Learning Curve Productivity : BackgroundPradeepÎncă nu există evaluări
- 1209876Document7 pagini1209876PradeepÎncă nu există evaluări
- 19741Document4 pagini19741pkj009Încă nu există evaluări
- Buffetts First BillionDocument35 paginiBuffetts First Billionbhaskar.jain20021814Încă nu există evaluări
- Wiley Finance Art of Company Valuation and Financial Statement Analysis A Value Investor S Guide With Real Life Case StudiesDocument4 paginiWiley Finance Art of Company Valuation and Financial Statement Analysis A Value Investor S Guide With Real Life Case StudiesPradeepÎncă nu există evaluări
- Building Good Models Is Not Enough: Richard RichelsDocument8 paginiBuilding Good Models Is Not Enough: Richard RichelsPradeepÎncă nu există evaluări
- 171473Document10 pagini171473PradeepÎncă nu există evaluări
- 171820Document12 pagini171820PradeepÎncă nu există evaluări
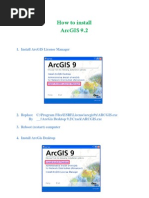
- How To Install ArcGIS 9.2Document5 paginiHow To Install ArcGIS 9.2Musaab100% (8)
- My Project For MonographDocument27 paginiMy Project For MonographAntonio Eduardo AntonioÎncă nu există evaluări
- Lineland - HBase Architecture 101 - StorageDocument15 paginiLineland - HBase Architecture 101 - StorageAmir RiazÎncă nu există evaluări
- Ch07 DatabaseDocument37 paginiCh07 DatabaseGangadhar MamadapurÎncă nu există evaluări
- INT243Document2 paginiINT243manvendraÎncă nu există evaluări
- Error Control Coding Fundamentals and Applications by Shu Lin PDFDocument2 paginiError Control Coding Fundamentals and Applications by Shu Lin PDFMaggie0% (1)
- It, Computer, PG ProgramsDocument6 paginiIt, Computer, PG ProgramsAnisha AdhikariÎncă nu există evaluări
- Microproject Report WordDocument12 paginiMicroproject Report WordVedant DhanawadeÎncă nu există evaluări
- Customer Relationship Management and The IDIC Model in Retail BankingDocument12 paginiCustomer Relationship Management and The IDIC Model in Retail BankingEsyaÎncă nu există evaluări
- Log Analysis and Monitoring with WSO2 BAM and CEPDocument30 paginiLog Analysis and Monitoring with WSO2 BAM and CEPmurari_0454168Încă nu există evaluări
- Data Modeling Using The Entity-Relationship (ER) Model: Slide 1-1Document61 paginiData Modeling Using The Entity-Relationship (ER) Model: Slide 1-1HasanÎncă nu există evaluări
- Management Accounting OverviewDocument20 paginiManagement Accounting OverviewNamasteÎncă nu există evaluări
- IBM Content Manager OnDemand and FileNet-1Document88 paginiIBM Content Manager OnDemand and FileNet-1David ResendizÎncă nu există evaluări
- Year 12 Reasearch BookletDocument15 paginiYear 12 Reasearch BookletImtiaz MohammedÎncă nu există evaluări
- Distributed Transactions ProtocolsDocument62 paginiDistributed Transactions ProtocolsMonika SrivastavaÎncă nu există evaluări
- Wonder Tatenda Mapiye Industrial Attachment ReportDocument18 paginiWonder Tatenda Mapiye Industrial Attachment ReportTaririrai HoveÎncă nu există evaluări
- Top SQL MCQDocument85 paginiTop SQL MCQScientific WayÎncă nu există evaluări
- Session11-4Slots-Basic IODocument60 paginiSession11-4Slots-Basic IOMinh VuÎncă nu există evaluări
- AsureID License Log AnalysisDocument585 paginiAsureID License Log AnalysisJose Soto100% (1)
- Research Methodology Ums PDFDocument104 paginiResearch Methodology Ums PDFAin Adibah100% (1)
- Print Thesis1 5Document41 paginiPrint Thesis1 5Kathleen Ann Santiago0% (1)
- Singly Linked List Program in CDocument12 paginiSingly Linked List Program in CRevathimuthusamyÎncă nu există evaluări