S-ar putea să vă placă și
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5795)
- Project Data Sheet: PDS Creation DateDocument4 paginiProject Data Sheet: PDS Creation DatesmzahidshahÎncă nu există evaluări
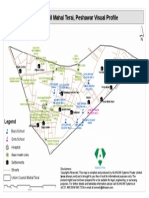
- Union Council Mahal Terai, Peshawar Visual Profile: LegendDocument1 paginăUnion Council Mahal Terai, Peshawar Visual Profile: LegendsmzahidshahÎncă nu există evaluări
- Forest Tree Species Classification Using Multispectral Satellite ImageriesDocument8 paginiForest Tree Species Classification Using Multispectral Satellite ImageriessmzahidshahÎncă nu există evaluări
- DSFSDF Ss SDocument4 paginiDSFSDF Ss SsmzahidshahÎncă nu există evaluări
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Temperature Measuring Instrument (1-Channel) : Testo 925 - For Fast and Reliable Measurements in The HVAC FieldDocument8 paginiTemperature Measuring Instrument (1-Channel) : Testo 925 - For Fast and Reliable Measurements in The HVAC FieldMirwansyah TanjungÎncă nu există evaluări
- Midas Civil WebinarDocument51 paginiMidas Civil WebinarCHarlesghylonÎncă nu există evaluări
- How-To Guide: Transaction Launcher (SAP CRM 7.0) .0Document22 paginiHow-To Guide: Transaction Launcher (SAP CRM 7.0) .0Satish DhondalayÎncă nu există evaluări
- Getting Familiar With Microsoft Word 2007 For WindowsDocument3 paginiGetting Familiar With Microsoft Word 2007 For WindowsRaymel HernandezÎncă nu există evaluări
- DC Motor Drive: - General Concept - Speed Control - SCR Drives - Switched-Mode DC DrivesDocument34 paginiDC Motor Drive: - General Concept - Speed Control - SCR Drives - Switched-Mode DC Driveshdrzaman9439Încă nu există evaluări
- Aggregate Planning and Master Scheduling: Mcgraw-Hill/IrwinDocument15 paginiAggregate Planning and Master Scheduling: Mcgraw-Hill/IrwinKushal BhatiaÎncă nu există evaluări
- Iqmin A Jktinv0087205 Jktyulia 20230408071006Document1 paginăIqmin A Jktinv0087205 Jktyulia 20230408071006Rahayu UmarÎncă nu există evaluări
- Assignment SurveyDocument4 paginiAssignment Surveyfatin_fazlina_1Încă nu există evaluări
- Leadership Culture and Management Practices A Comparative Study Between Denmark and Japan PDFDocument70 paginiLeadership Culture and Management Practices A Comparative Study Between Denmark and Japan PDFMichelle Samillano PasaheÎncă nu există evaluări
- Applications of Genetic Algorithm in Water Resources Management and OptimizationDocument11 paginiApplications of Genetic Algorithm in Water Resources Management and OptimizationGarima TyagiÎncă nu există evaluări
- Differential Pressure Switch RH3Document2 paginiDifferential Pressure Switch RH3Jairo ColeccionistaÎncă nu există evaluări
- ANCAP Corporate Design GuidelinesDocument20 paginiANCAP Corporate Design GuidelineshazopmanÎncă nu există evaluări
- Envitec Company Profile PDFDocument2 paginiEnvitec Company Profile PDFrcerberoÎncă nu există evaluări
- Pressure Vessel PDFDocument8 paginiPressure Vessel PDFdanielreyeshernandezÎncă nu există evaluări
- CV Europass 20160805 Kolla EN PDFDocument2 paginiCV Europass 20160805 Kolla EN PDFKeshav KollaÎncă nu există evaluări
- Rosemount 2120 Vibrating Fork Liquid Level SwitchDocument16 paginiRosemount 2120 Vibrating Fork Liquid Level SwitchTariqMalikÎncă nu există evaluări
- QP Cluster Manager PDFDocument31 paginiQP Cluster Manager PDFkanisha2014Încă nu există evaluări
- Odot Microstation TrainingDocument498 paginiOdot Microstation TrainingNARAYANÎncă nu există evaluări
- S A 20190725Document4 paginiS A 20190725krishaÎncă nu există evaluări
- IRDADocument26 paginiIRDANikhil JainÎncă nu există evaluări
- Pakistan Machine Tool Factory Internship ReportDocument14 paginiPakistan Machine Tool Factory Internship ReportAtif MunirÎncă nu există evaluări
- Amces 2020Document1 paginăAmces 2020Karthik GootyÎncă nu există evaluări
- Netflix - WikipediaDocument3 paginiNetflix - WikipediaHanako ChinatsuÎncă nu există evaluări
- Authentication MethodsDocument1 paginăAuthentication MethodsmelocyÎncă nu există evaluări
- Punjab ULBRFPVolume IAttachmentdate 21 Nov 2016Document214 paginiPunjab ULBRFPVolume IAttachmentdate 21 Nov 2016NishantvermaÎncă nu există evaluări
- MEPC 1-Circ 723Document10 paginiMEPC 1-Circ 723Franco MitranoÎncă nu există evaluări
- What Is JavaScriptDocument10 paginiWhat Is JavaScriptKhalinux AnonimoÎncă nu există evaluări
- Mahesh Chand CVDocument4 paginiMahesh Chand CVMahesh NiralaÎncă nu există evaluări
- Rehau Awadukt Thermo: Ground-Air Heat Exchanger System For Controlled VentilationDocument36 paginiRehau Awadukt Thermo: Ground-Air Heat Exchanger System For Controlled VentilationLeon_68Încă nu există evaluări
- Ot 701Document2 paginiOt 701Fares Al HoumsiÎncă nu există evaluări