S-ar putea să vă placă și
- 3.6 Inverse RequirementsDocument1 pagină3.6 Inverse RequirementsShaista SaeedÎncă nu există evaluări
- Client Server Architecture A Complete Guide - 2020 EditionDe la EverandClient Server Architecture A Complete Guide - 2020 EditionÎncă nu există evaluări
- C Super Market Billing SystemDocument21 paginiC Super Market Billing SystemNaMan SeThi0% (1)
- Software Measurement A Complete Guide - 2020 EditionDe la EverandSoftware Measurement A Complete Guide - 2020 EditionÎncă nu există evaluări
- Hospital Management System UmlDocument10 paginiHospital Management System UmlMeenatchi VaradarasuÎncă nu există evaluări
- RDBMS Relational Database Management System A Complete Guide - 2020 EditionDe la EverandRDBMS Relational Database Management System A Complete Guide - 2020 EditionÎncă nu există evaluări
- Design and Development of Online Doctor Appointment SystemDocument10 paginiDesign and Development of Online Doctor Appointment SystemFarah Yousaf100% (1)
- Software Requirement Specification (SRS) : Online Photo GalleryDocument5 paginiSoftware Requirement Specification (SRS) : Online Photo Galleryklint0% (1)
- Appointment SystemDocument14 paginiAppointment SystemvaibhavÎncă nu există evaluări
- Srs Budget AccountingDocument27 paginiSrs Budget AccountingDivya Sharma100% (1)
- System Requirements DocumetDocument16 paginiSystem Requirements DocumetrojaÎncă nu există evaluări
- Pulkit Hospital Management ReportDocument53 paginiPulkit Hospital Management ReportPulkitÎncă nu există evaluări
- DiagramsDocument135 paginiDiagramsDan ValienteÎncă nu există evaluări
- Design and Implementation of E-Commerce Site For Online ShoppingDocument23 paginiDesign and Implementation of E-Commerce Site For Online ShoppingShariar Parvez TonmoyÎncă nu există evaluări
- Hospital ManagementDocument54 paginiHospital ManagementAmey Mandhare100% (1)
- of MP (Banking REcord SystemDocument38 paginiof MP (Banking REcord SystemAjit TiwariÎncă nu există evaluări
- College Data Management SystemDocument7 paginiCollege Data Management SystemParth BhawarÎncă nu există evaluări
- Doctor Synopsis PDFDocument7 paginiDoctor Synopsis PDFAnonymous W6EqDup0% (1)
- ERD & DFD & Diff. BT Flow Chart and Structured ChartDocument7 paginiERD & DFD & Diff. BT Flow Chart and Structured ChartToday MaldaÎncă nu există evaluări
- E Health Care Management System Java ProjectDocument23 paginiE Health Care Management System Java ProjectArya ChandranÎncă nu există evaluări
- Hospital Management Domain ModelDocument4 paginiHospital Management Domain Modelvinod kapateÎncă nu există evaluări
- Scholl WebsiteDocument31 paginiScholl WebsiteJaldeepÎncă nu există evaluări
- "Railway Management System": Submitted in Partial Fulfillment For The Award of TheDocument32 pagini"Railway Management System": Submitted in Partial Fulfillment For The Award of Thepreeti nigamÎncă nu există evaluări
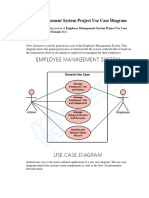
- Employee Management System Use Case DiagramDocument4 paginiEmployee Management System Use Case DiagramTezera TesfayeÎncă nu există evaluări
- Final Proposal Online Doctor AppointmentDocument22 paginiFinal Proposal Online Doctor AppointmentMc SquareÎncă nu există evaluări
- Library Management System Activity DiagramDocument20 paginiLibrary Management System Activity DiagramSaroj Kumar RajakÎncă nu există evaluări
- OOSAD Project - Guid - LineDocument18 paginiOOSAD Project - Guid - LineyibeltalÎncă nu există evaluări
- ArbindDocument64 paginiArbindrishabhmaithaniÎncă nu există evaluări
- Doctor Management VB Project ReportDocument91 paginiDoctor Management VB Project ReportBhushan Chendekar100% (3)
- Tyagi SrsDocument21 paginiTyagi SrsMuskan SharmaÎncă nu există evaluări
- ML AssignmentDocument2 paginiML AssignmentMuqadas HassanÎncă nu există evaluări
- Hospital Manage-WPS OfficeDocument20 paginiHospital Manage-WPS OfficePranita PawarÎncă nu există evaluări
- Class Diagram For Hospital Management System: Hospital Appointment RejectedDocument8 paginiClass Diagram For Hospital Management System: Hospital Appointment RejectedAjay PawarÎncă nu există evaluări
- Project On G.S.R.T.C. by Rahesh and Parag-B.k.m.i.b.a.-H.l.b.b.a.-AhmedabadDocument72 paginiProject On G.S.R.T.C. by Rahesh and Parag-B.k.m.i.b.a.-H.l.b.b.a.-Ahmedabadrahesh sutariya75% (4)
- Sample - Software Requirements Specification For Hospital Info Management SystemDocument6 paginiSample - Software Requirements Specification For Hospital Info Management SystemMohamed FaroukÎncă nu există evaluări
- Tourism SrsDocument22 paginiTourism SrsKundan Kumar100% (1)
- Library Management SystemDocument17 paginiLibrary Management Systemvishal kumarÎncă nu există evaluări
- of MP (Banking REcord SystemDocument38 paginiof MP (Banking REcord SystemAjit TiwariÎncă nu există evaluări
- Computer Shop Management SystemDocument62 paginiComputer Shop Management Systemvickram jainÎncă nu există evaluări
- Design of Online - ShopDocument48 paginiDesign of Online - Shopshaik haseenaÎncă nu există evaluări
- Hospital Management System ProposalDocument11 paginiHospital Management System ProposalAce WolverineÎncă nu există evaluări
- SRS FOR HOSPITAL MANAGEMENT SYSTEM - OdtDocument4 paginiSRS FOR HOSPITAL MANAGEMENT SYSTEM - OdtHaxham NadeemÎncă nu există evaluări
- OOP Lab-8Document7 paginiOOP Lab-8Mujahid Malik ArainÎncă nu există evaluări
- Online Food Ordering System Using Cloud TechnologyDocument8 paginiOnline Food Ordering System Using Cloud Technologybenz bhenzÎncă nu există evaluări
- Project Report On Image SegmentationDocument6 paginiProject Report On Image SegmentationSAURABH RAJÎncă nu există evaluări
- Software Design Document Testing Deploym PDFDocument117 paginiSoftware Design Document Testing Deploym PDFSo RineatzaÎncă nu există evaluări
- Database Engineering (EC-240) : Lab Manual # 04Document9 paginiDatabase Engineering (EC-240) : Lab Manual # 04AMINA QADEERÎncă nu există evaluări
- Qdoc - Tips - Synopsis of Fitness Center Management SystemDocument29 paginiQdoc - Tips - Synopsis of Fitness Center Management SystemSaurabh NalawadeÎncă nu există evaluări
- College Management SystemDocument125 paginiCollege Management SystemAnsh Jain100% (1)
- CRC Model Group-7Document11 paginiCRC Model Group-7Misganaw TadesseÎncă nu există evaluări
- Online Doctor Appointment SystemDocument5 paginiOnline Doctor Appointment SystemdmusudaÎncă nu există evaluări
- Online Quiz SystemDocument58 paginiOnline Quiz SystemSarfaraz ali SyedÎncă nu există evaluări
- Cosmetic Store Management System Project ReportDocument77 paginiCosmetic Store Management System Project ReportApoorvaÎncă nu există evaluări
- Blood Bank Management SystemDocument68 paginiBlood Bank Management SystemAshish VinodÎncă nu există evaluări
- Srs of AppoloDocument7 paginiSrs of AppoloAwaneesh RajÎncă nu există evaluări
- Final Project ProposalDocument36 paginiFinal Project ProposalbrhaneÎncă nu există evaluări
- Online Course ReservationDocument23 paginiOnline Course Reservationthebhas1954Încă nu există evaluări
- Benefits of Class DiagramDocument17 paginiBenefits of Class DiagramAadam Yuusuf100% (1)
- Edoc ReportDocument12 paginiEdoc ReportHighlights Mania100% (1)
- Rdbms SlipDocument7 paginiRdbms Slipnimeshmaheshwari6Încă nu există evaluări
- Introduction To MongodbDocument50 paginiIntroduction To MongodbPonnusamy S PichaimuthuÎncă nu există evaluări
- Database Vocabulary 28ylmm4Document2 paginiDatabase Vocabulary 28ylmm4John WilderÎncă nu există evaluări
- Data WarehousingDocument41 paginiData WarehousingshadybrockÎncă nu există evaluări
- SQL Cheat SheetDocument15 paginiSQL Cheat SheetSteven BlackÎncă nu există evaluări
- Lecture-2 Fundamentals of RDB - Basic SQLDocument14 paginiLecture-2 Fundamentals of RDB - Basic SQLsesaza52Încă nu există evaluări
- Information Technology (IT) : Computers Telecommunications EquipmentDocument5 paginiInformation Technology (IT) : Computers Telecommunications EquipmentThomas JohnsonÎncă nu există evaluări
- Master ICT CurriculumDocument50 paginiMaster ICT CurriculumDr Patrick CernaÎncă nu există evaluări
- Computer and Communication - 2018Document27 paginiComputer and Communication - 2018VaishaliÎncă nu există evaluări
- Kuliah M1 - TEKREK - Komputasi Big DataDocument55 paginiKuliah M1 - TEKREK - Komputasi Big DataMohamad Iqbal AlamsyahÎncă nu există evaluări
- Wedding PlannerDocument23 paginiWedding PlannerShamsher Khan100% (2)
- Data Science SkillsDocument31 paginiData Science SkillsSASIKUMAR BÎncă nu există evaluări
- Azure Data Fundamentals Explore Non Relational Data in Azure - Explore Non-Relational Data Offerings in AzureDocument20 paginiAzure Data Fundamentals Explore Non Relational Data in Azure - Explore Non-Relational Data Offerings in AzureHanifah NurfitriyantiÎncă nu există evaluări
- ¡Let's Get The Point! - Topics, Main Ideas and Supporting Details PDFDocument27 pagini¡Let's Get The Point! - Topics, Main Ideas and Supporting Details PDFBetzalel Emprendimiento50% (2)
- Important Question For DBMSDocument34 paginiImportant Question For DBMSpreet patelÎncă nu există evaluări
- Mysql For BeginnersDocument313 paginiMysql For BeginnersvaibhavikanthariaÎncă nu există evaluări
- Database Management SystemDocument24 paginiDatabase Management SystemHamza BasharatÎncă nu există evaluări
- International Journal of Applied Information Systems (IJAIS)Document11 paginiInternational Journal of Applied Information Systems (IJAIS)cendy oktariÎncă nu există evaluări
- 10-Step Methodology To Creating A Single View of Your BusinessDocument14 pagini10-Step Methodology To Creating A Single View of Your BusinessSrz CreationsÎncă nu există evaluări
- Database Management Systems Lab ManualDocument40 paginiDatabase Management Systems Lab ManualBanumathi JayarajÎncă nu există evaluări
- PL SQL Interview QnsDocument182 paginiPL SQL Interview Qnsmustafa2376100% (1)
- Social Networking SitesDocument160 paginiSocial Networking SitesNishith SahaniÎncă nu există evaluări
- 11g New Features For Administrators Student Guide-4Document50 pagini11g New Features For Administrators Student Guide-4shafeeq1985gmailÎncă nu există evaluări
- ICCA Volume 5Document235 paginiICCA Volume 5kk3934Încă nu există evaluări
- HEC MS Computer Science CurriculumDocument215 paginiHEC MS Computer Science Curriculumadnan0% (1)
- Ibm Infosphere Datastage Essentials V11.5: Course GuideDocument622 paginiIbm Infosphere Datastage Essentials V11.5: Course Guideshubham neve100% (1)
- Multimedia Systems DesignDocument88 paginiMultimedia Systems Designvenkatarangan rajuluÎncă nu există evaluări
- Introduction To MS Access Without AnswersDocument92 paginiIntroduction To MS Access Without AnswersLeslyn BonachitaÎncă nu există evaluări
- Entity Relationship ModelDocument85 paginiEntity Relationship Modelteam 8Încă nu există evaluări
- Unit Vi Working With Internet, Databases and Publishing AppDocument11 paginiUnit Vi Working With Internet, Databases and Publishing AppSakshi HulgundeÎncă nu există evaluări
- University of Chicago Press Fall 2009 CatalogueDe la EverandUniversity of Chicago Press Fall 2009 CatalogueEvaluare: 5 din 5 stele5/5 (1)
- University of Chicago Press Fall 2009 Distributed TitlesDe la EverandUniversity of Chicago Press Fall 2009 Distributed TitlesEvaluare: 1 din 5 stele1/5 (1)