S-ar putea să vă placă și
- Applications of Derivatives Errors and Approximation (Calculus) Mathematics Question BankDe la EverandApplications of Derivatives Errors and Approximation (Calculus) Mathematics Question BankÎncă nu există evaluări
- RL Complete Unit-5Document30 paginiRL Complete Unit-5Harpreet Singh BaggaÎncă nu există evaluări
- Sec 12Document5 paginiSec 12Prateer Kr RoyÎncă nu există evaluări
- Unit 4Document56 paginiUnit 4randyyÎncă nu există evaluări
- Con Reinforcement Aug Dec 2020Document52 paginiCon Reinforcement Aug Dec 2020acer asusÎncă nu există evaluări
- A Brief Introduction To Reinforcement LearningDocument4 paginiA Brief Introduction To Reinforcement LearningNarendra PatelÎncă nu există evaluări
- Problem Solving and SearchDocument100 paginiProblem Solving and SearchMohammad Omar FaruqÎncă nu există evaluări
- MDP PDFDocument37 paginiMDP PDFbsudheertecÎncă nu există evaluări
- Reinforcement Learning: Yijue HouDocument34 paginiReinforcement Learning: Yijue HouAnum KhawajaÎncă nu există evaluări
- Lecture 3 Problems Solving by SearchingDocument78 paginiLecture 3 Problems Solving by SearchingMd.Ashiqur RahmanÎncă nu există evaluări
- Local Search AlgorithmsDocument34 paginiLocal Search AlgorithmsMubasher ShahzadÎncă nu există evaluări
- Zeyu Tan AI Assessment ReportDocument14 paginiZeyu Tan AI Assessment ReportAnna LionÎncă nu există evaluări
- Question: Devise A Hill Climbing Search Based Approach To Solve N-City Tsps. You Must de Ne All Req..Document4 paginiQuestion: Devise A Hill Climbing Search Based Approach To Solve N-City Tsps. You Must de Ne All Req..Malik AsadÎncă nu există evaluări
- Markov Decision Processes & Reinforcement Learning: Megan Smith Lehigh University, Fall 2006Document40 paginiMarkov Decision Processes & Reinforcement Learning: Megan Smith Lehigh University, Fall 2006Sanja Lazarova-MolnarÎncă nu există evaluări
- POMDP Tutoria POMDP - TutoriallDocument55 paginiPOMDP Tutoria POMDP - TutoriallEhsan Elahi BashirÎncă nu există evaluări
- Lecture Notes Deep Reinforcement Learning: Generalizability in Deep RLDocument7 paginiLecture Notes Deep Reinforcement Learning: Generalizability in Deep RLRajat RaiÎncă nu există evaluări
- Reinforcement LearningDocument32 paginiReinforcement Learningvedang maheshwariÎncă nu există evaluări
- Reinforcement LearningDocument45 paginiReinforcement LearningPooja AngolkarÎncă nu există evaluări
- Stochastic Process - Markov Property - Markov Chain - Markov Decision Process - Reinforcement Learning - RL Techniques - Example ApplicationsDocument39 paginiStochastic Process - Markov Property - Markov Chain - Markov Decision Process - Reinforcement Learning - RL Techniques - Example ApplicationsSarmi HarshaÎncă nu există evaluări
- Lecture-3 Problems Solving by SearchingDocument79 paginiLecture-3 Problems Solving by SearchingmusaÎncă nu există evaluări
- SP05Document55 paginiSP05Sao SiÎncă nu există evaluări
- Reinforcement LearningDocument46 paginiReinforcement LearningShagunÎncă nu există evaluări
- RL Theory TutorialDocument80 paginiRL Theory Tutorialpupilo74Încă nu există evaluări
- DD2431 Machine Learning Lab 4: Reinforcement Learning Python VersionDocument9 paginiDD2431 Machine Learning Lab 4: Reinforcement Learning Python VersionbboyvnÎncă nu există evaluări
- Artificial Intelligence Chapter 3: Problem Solving and SearchingDocument94 paginiArtificial Intelligence Chapter 3: Problem Solving and SearchingZeeshan Bhatti100% (1)
- Q LearningDocument9 paginiQ LearningSurya MudaliarÎncă nu există evaluări
- Markov Decision Processes: Stochastic, Sequential EnvironmentsDocument20 paginiMarkov Decision Processes: Stochastic, Sequential Environmentsmikey61Încă nu există evaluări
- AI2 Problem-SolvingDocument30 paginiAI2 Problem-SolvingAfan AffaidinÎncă nu există evaluări
- Reinforcement Learning: Russell and Norvig: CH 21Document16 paginiReinforcement Learning: Russell and Norvig: CH 21ZuzarÎncă nu există evaluări
- Reinforcement Learning: Amulya Viswambaran (202090007) Kehkashan Fatima (202090202) Sruthi Krishnan (202090333)Document40 paginiReinforcement Learning: Amulya Viswambaran (202090007) Kehkashan Fatima (202090202) Sruthi Krishnan (202090333)AmulyaÎncă nu există evaluări
- AI 11 Reinforcement Learning IIDocument35 paginiAI 11 Reinforcement Learning IIhumanbody22Încă nu există evaluări
- FALLSEM2022-23 CBS3004 ETH VL2022230104390 Reference Material I 10-08-2022 2.1 Problem Solving in AIDocument36 paginiFALLSEM2022-23 CBS3004 ETH VL2022230104390 Reference Material I 10-08-2022 2.1 Problem Solving in AIBhimavarapu Sreekar ReddyÎncă nu există evaluări
- CH 5,6,7Document110 paginiCH 5,6,7shikha jainÎncă nu există evaluări
- ML Unit 4Document9 paginiML Unit 4themojlvlÎncă nu există evaluări
- Unit-5 Genetic Reinforcement Markov Q-LearningDocument39 paginiUnit-5 Genetic Reinforcement Markov Q-LearningAyush Rao RajputÎncă nu există evaluări
- CS361 AI Week2 Lecture1Document21 paginiCS361 AI Week2 Lecture1Mohamed HanyÎncă nu există evaluări
- Rewards in Reinforcement LearningDocument12 paginiRewards in Reinforcement LearningJack LumberÎncă nu există evaluări
- NIPS 2004 Experts in A Markov Decision Process Paper CompressedDocument8 paginiNIPS 2004 Experts in A Markov Decision Process Paper CompressedTasya Syifa AltanzaniaÎncă nu există evaluări
- Lecture RLDocument37 paginiLecture RLprakuld04Încă nu există evaluări
- A Beginner's Guide To Deep Reinforcement Learning: Skymind - AiDocument23 paginiA Beginner's Guide To Deep Reinforcement Learning: Skymind - AiNIKHILESH M NAIK 1827521Încă nu există evaluări
- Reinforcement LearningDocument35 paginiReinforcement Learningfull entertainmentÎncă nu există evaluări
- Reinforcement LearningDocument15 paginiReinforcement Learning21dce106Încă nu există evaluări
- An Analytic Approach: Abilities?Document6 paginiAn Analytic Approach: Abilities?nguyensyhuyÎncă nu există evaluări
- AI A Z HandBookDocument12 paginiAI A Z HandBookEsteban Ignacio Melendez OsechasÎncă nu există evaluări
- Sp14 Cs188 Lecture 8 - Mdps IDocument50 paginiSp14 Cs188 Lecture 8 - Mdps Ixixip66099Încă nu există evaluări
- RL 10 QUESTIONS FOR MID II Scheme of EvaluvationDocument15 paginiRL 10 QUESTIONS FOR MID II Scheme of EvaluvationmovatehireÎncă nu există evaluări
- SP14 CS188 Lecture 10 - Reinforcement Learning IDocument35 paginiSP14 CS188 Lecture 10 - Reinforcement Learning Iuser84541561Încă nu există evaluări
- Reinforcement Learning 1Document11 paginiReinforcement Learning 1Mark RichardÎncă nu există evaluări
- 02 MarkovDecisionProcessDocument51 pagini02 MarkovDecisionProcessKerry BeachÎncă nu există evaluări
- CSD311: Artificial IntelligenceDocument11 paginiCSD311: Artificial IntelligenceAyaan KhanÎncă nu există evaluări
- AI File - 03 PDFDocument43 paginiAI File - 03 PDFNahim's kitchenÎncă nu există evaluări
- 17 MDPDocument28 pagini17 MDPnada abdelrahmanÎncă nu există evaluări
- Reinforcement Learning: Russell and Norvig: CH 21Document16 paginiReinforcement Learning: Russell and Norvig: CH 21ZuzarÎncă nu există evaluări
- To Build A System To Solve A ProblemDocument60 paginiTo Build A System To Solve A ProblemPiyush DatirÎncă nu există evaluări
- State Space Search: Week 3Document47 paginiState Space Search: Week 3tech surgeonsÎncă nu există evaluări
- Reinforcement Learning - Ipynb - ColaboratoryDocument7 paginiReinforcement Learning - Ipynb - Colaboratoryzb laiÎncă nu există evaluări
- Solving Problems by SearchingDocument67 paginiSolving Problems by SearchingDawit Shimeles TesfayeÎncă nu există evaluări
- 2024 Lecture03 P1 ProblemSolvingBySearchingDocument48 pagini2024 Lecture03 P1 ProblemSolvingBySearchingTrương Thuận KiệtÎncă nu există evaluări
- New CZ3005 Module 5 - Reinforcement LearningDocument31 paginiNew CZ3005 Module 5 - Reinforcement Learningkellen tseÎncă nu există evaluări
- A Tutorial For Reinforcement LearningDocument17 paginiA Tutorial For Reinforcement LearningNirajDhotreÎncă nu există evaluări
- GAM DistributionOfLoads 2 Horizontal TorsionDocument48 paginiGAM DistributionOfLoads 2 Horizontal TorsionFelipe Carrasco Durán100% (1)
- Foundation Design For Dynamic Equipment Based On ACI 351.3 & ACI 318-19Document12 paginiFoundation Design For Dynamic Equipment Based On ACI 351.3 & ACI 318-19ZuzarÎncă nu există evaluări
- DFDFDocument31 paginiDFDFZuzarÎncă nu există evaluări
- 250 MM 350 MM: Check For Crack Width As Per Is 456-2000Document3 pagini250 MM 350 MM: Check For Crack Width As Per Is 456-2000ZuzarÎncă nu există evaluări
- Aci 351 3R 04Document12 paginiAci 351 3R 04ZuzarÎncă nu există evaluări
- Common Retaining Walls: Dr. Mohammed E. Haque, P.E. Retaining WallsDocument18 paginiCommon Retaining Walls: Dr. Mohammed E. Haque, P.E. Retaining WallsandyhrÎncă nu există evaluări
- CC 1352 PDocument61 paginiCC 1352 PGiampaolo CiardielloÎncă nu există evaluări
- DC Motors and Generatos QuestionsDocument2 paginiDC Motors and Generatos QuestionsvpzfarisÎncă nu există evaluări
- Plant and Maintenance Managers Desk BookDocument477 paginiPlant and Maintenance Managers Desk BookHugoCabanillasÎncă nu există evaluări
- J Proc CTRL Vol 19 2009 Q Wang K Astrom - Guaranteed Dominant Pole PlacementDocument4 paginiJ Proc CTRL Vol 19 2009 Q Wang K Astrom - Guaranteed Dominant Pole PlacementmtichyscribdÎncă nu există evaluări
- African Music Re-Examined in The Light of New Materials From The Belgian Congo and Ruanda Urundi Akab P Merriam African Music Re-ExaminedDocument9 paginiAfrican Music Re-Examined in The Light of New Materials From The Belgian Congo and Ruanda Urundi Akab P Merriam African Music Re-Examinedberimbau8Încă nu există evaluări
- Multilateral Drilling and Completions - Applications in Practice D. ThemigDocument12 paginiMultilateral Drilling and Completions - Applications in Practice D. ThemigFaiz TalpurÎncă nu există evaluări
- Getting Familiar With Microsoft Word 2007 For WindowsDocument3 paginiGetting Familiar With Microsoft Word 2007 For WindowsRaymel HernandezÎncă nu există evaluări
- Unity For Mobile Games: Solution GuideDocument9 paginiUnity For Mobile Games: Solution GuideAlexaÎncă nu există evaluări
- Issues in Timing: Digital Integrated Circuits © Prentice Hall 1995 TimingDocument14 paginiIssues in Timing: Digital Integrated Circuits © Prentice Hall 1995 TimingAbhishek BhardwajÎncă nu există evaluări
- Msamb Rules and Japan GuidelinesDocument3 paginiMsamb Rules and Japan GuidelineslawrgeoÎncă nu există evaluări
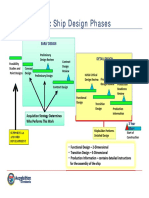
- Basic Ship Design PhasesDocument1 paginăBasic Ship Design PhasesJhon GreigÎncă nu există evaluări
- York R410ADocument2 paginiYork R410AArabiat76Încă nu există evaluări
- Amces 2020Document1 paginăAmces 2020Karthik GootyÎncă nu există evaluări
- Pete443 Chapter3 PDFDocument38 paginiPete443 Chapter3 PDFQaiser HafeezÎncă nu există evaluări
- POCLP010101 Wood PelletsDocument1 paginăPOCLP010101 Wood PelletsPratiwi CocoÎncă nu există evaluări
- Rahul BhartiDocument3 paginiRahul BhartirahuldearestÎncă nu există evaluări
- Ansi z245 2 1997Document31 paginiAnsi z245 2 1997camohunter71Încă nu există evaluări
- Global Trends 2030 Preview: Interactive Le MenuDocument5 paginiGlobal Trends 2030 Preview: Interactive Le MenuOffice of the Director of National Intelligence100% (1)
- Steel Reinforcement For WallsDocument7 paginiSteel Reinforcement For WallsSurinderPalSinghGillÎncă nu există evaluări
- Mariveles ChlorinatorDocument1 paginăMariveles ChlorinatorJhn Cbllr BqngÎncă nu există evaluări
- Introduction To Matlab - Simulink Control Systems: & Their Application inDocument13 paginiIntroduction To Matlab - Simulink Control Systems: & Their Application inTom ArmstrongÎncă nu există evaluări
- TMB 60Document2 paginiTMB 60oac08Încă nu există evaluări
- Coloumns & StrutsDocument14 paginiColoumns & StrutsWaseem AhmedÎncă nu există evaluări
- Auto Chassis NotesDocument90 paginiAuto Chassis Notesanishsukumar000gmailcomÎncă nu există evaluări
- A Research Instrument Is A SurveyDocument1 paginăA Research Instrument Is A SurveyHasan YusuvÎncă nu există evaluări
- Y y Y Y Y: Design of Machinery 86Document1 paginăY y Y Y Y: Design of Machinery 86Star GlacierÎncă nu există evaluări
- ASTM D 3786 Bursting Strength, Diaphragm MethodDocument1 paginăASTM D 3786 Bursting Strength, Diaphragm MethodAfzal Sarfaraz100% (1)
- Aalco StocklistDocument36 paginiAalco StocklistjsfscibdÎncă nu există evaluări
- Hfe Panasonic Sa-Akx50 PH PN Service enDocument132 paginiHfe Panasonic Sa-Akx50 PH PN Service enJohntec nuñezÎncă nu există evaluări
- Computer Viruses: What Is A Virus?Document4 paginiComputer Viruses: What Is A Virus?Ako GwapoÎncă nu există evaluări