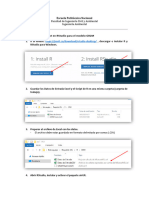
S-ar putea să vă placă și
- Determinación de Las Especificaciones Objetivo para El ProductoDocument6 paginiDeterminación de Las Especificaciones Objetivo para El ProductoJacquelineStempÎncă nu există evaluări
- STORED PROCEDURES (Implementacion) SQL SERVER PDFDocument6 paginiSTORED PROCEDURES (Implementacion) SQL SERVER PDFJulieP.ShulterbrondtÎncă nu există evaluări
- Manual de PreciosDocument169 paginiManual de PreciosJuan Salvador Meza Cruz100% (1)
- Prueba Tecnica (RicardoManceraPardo)Document6 paginiPrueba Tecnica (RicardoManceraPardo)Daibeth DuranÎncă nu există evaluări
- Base de datos taller mecánicoDocument15 paginiBase de datos taller mecánicojorgeleo22Încă nu există evaluări
- Manual técnico del sistema ADAMDocument85 paginiManual técnico del sistema ADAMJeffeers Prieto33% (3)
- 3-Examen Machine Learning EngineerDocument4 pagini3-Examen Machine Learning Engineerfercho120Încă nu există evaluări
- Laboratorio BI PDFDocument47 paginiLaboratorio BI PDFFátima Rodríguez LlicánÎncă nu există evaluări
- Guía 6Document15 paginiGuía 6Luis Hubert Ipanaqué MuñozÎncă nu există evaluări
- Manual de AutomatismosDocument16 paginiManual de AutomatismosDaniel Hidalgo VerzobiasÎncă nu există evaluări
- Contadores y Puntos de Medida en SAP (PM)Document28 paginiContadores y Puntos de Medida en SAP (PM)UrloNegro100% (1)
- Ejemplo - Aplicación Del Proceso Software Personal PSPDocument29 paginiEjemplo - Aplicación Del Proceso Software Personal PSPGerdis MartinezÎncă nu există evaluări
- Ejemplos SQLDocument15 paginiEjemplos SQLLUXÎncă nu există evaluări
- Estructura de Control OracleDocument24 paginiEstructura de Control OracleMax75Încă nu există evaluări
- BD Practica12Document8 paginiBD Practica12Alexis Rafael Del Valle AragónÎncă nu există evaluări
- Solucion Taller Procedimientos Almacenados1Document6 paginiSolucion Taller Procedimientos Almacenados1lady-morenoÎncă nu există evaluări
- Estimaciones PF y COCOMODocument6 paginiEstimaciones PF y COCOMOLuis TacillaÎncă nu există evaluări
- Test Carga BD K6Document9 paginiTest Carga BD K6Hermes MonteiroÎncă nu există evaluări
- Prueba - Analista Junior de Desarrollo Java v2.1Document4 paginiPrueba - Analista Junior de Desarrollo Java v2.1moisesmendezÎncă nu există evaluări
- Manual Informes PersonalizadosDocument8 paginiManual Informes PersonalizadosFernando BernardezÎncă nu există evaluări
- Programación Transact Estructura Condicional IfDocument9 paginiProgramación Transact Estructura Condicional IfRumiche GjosueÎncă nu există evaluări
- Lab ETL PentahoDocument47 paginiLab ETL PentahoJosé Vicente Zambrano100% (2)
- CM SapDocument12 paginiCM Sapruzuriaga2Încă nu există evaluări
- Framework para VFP Conexion Con SQLServer MySQL PostgreSQL y Oracle IIIDocument8 paginiFramework para VFP Conexion Con SQLServer MySQL PostgreSQL y Oracle IIISheilla Lin Morales MercadoÎncă nu există evaluări
- Laboratorio 6 - BDII - 2021Document13 paginiLaboratorio 6 - BDII - 2021Luis SamaniegoÎncă nu există evaluări
- Ajuste Estacional Usando X-13ARIMA-SEATSDocument18 paginiAjuste Estacional Usando X-13ARIMA-SEATSmanuÎncă nu există evaluări
- Laboratorio 6 - BDII - 2021Document13 paginiLaboratorio 6 - BDII - 2021Antonio ReynaÎncă nu există evaluări
- Procedimientos Almacenados en FirebirdDocument6 paginiProcedimientos Almacenados en FirebirdSergio HdzÎncă nu există evaluări
- Pasos para La Creacion de BD OLTP y OLAPDocument13 paginiPasos para La Creacion de BD OLTP y OLAPJog GutÎncă nu există evaluări
- Procesamiento de datos y estructuras condicionales en programaciónDocument5 paginiProcesamiento de datos y estructuras condicionales en programaciónjheison guevaraÎncă nu există evaluări
- Modelado de DatosDocument14 paginiModelado de Datosjuan aguirreÎncă nu există evaluări
- Tarea gbd03Document4 paginiTarea gbd03mbs85Încă nu există evaluări
- 00 PresentaciónDocument21 pagini00 PresentaciónLisseth LevanoÎncă nu există evaluări
- Procedimientos Almacenados BDDocument39 paginiProcedimientos Almacenados BDcesard103Încă nu există evaluări
- Monográfia AlgoritmosDocument12 paginiMonográfia AlgoritmosFranco GutierrezÎncă nu există evaluări
- Evaluacion Final Base de Datos Camilo Vega PDFDocument7 paginiEvaluacion Final Base de Datos Camilo Vega PDFCAMILO SIMON VEGA HINOJOSAÎncă nu există evaluări
- Ejercicio Practico de BiDocument16 paginiEjercicio Practico de BijminguicÎncă nu există evaluări
- TransacSQL PDFDocument14 paginiTransacSQL PDFr01061gÎncă nu există evaluări
- Contabilidad Electronica SAPDocument19 paginiContabilidad Electronica SAPOmar MerinoÎncă nu există evaluări
- BD S04b Guia ProcAlmacDocument21 paginiBD S04b Guia ProcAlmacInes Ramos CcoaÎncă nu există evaluări
- Solucion Taller Procedimientos Almacenados1Document6 paginiSolucion Taller Procedimientos Almacenados1lady-morenoÎncă nu există evaluări
- SQL Northwind BD Ejemplo ConsultasDocument27 paginiSQL Northwind BD Ejemplo ConsultasJeko EgÎncă nu există evaluări
- TutoDocument8 paginiTutoWilliam FernandoÎncă nu există evaluări
- Introducción al Proceso Software Personal (PSPDocument28 paginiIntroducción al Proceso Software Personal (PSPJose Fernando Murillo ArangoÎncă nu există evaluări
- Adc TivaDocument7 paginiAdc TivaJ Ivan RinconÎncă nu există evaluări
- Apuntes PostgresqlDocument8 paginiApuntes PostgresqlbizzyrapÎncă nu există evaluări
- GPE - Modificaciones en Archivos, Cálculos y Archivos Magnéticos para Ecuador PDFDocument7 paginiGPE - Modificaciones en Archivos, Cálculos y Archivos Magnéticos para Ecuador PDFalima601Încă nu există evaluări
- FuncUsuProceAlmacenadosDocument42 paginiFuncUsuProceAlmacenadosJohn Graciano PalominoÎncă nu există evaluări
- Taller 3 Modelos de Colas y SimulacionDocument17 paginiTaller 3 Modelos de Colas y SimulacionClau ChavezÎncă nu există evaluări
- Curso Power BiDocument86 paginiCurso Power Bikwm9fkt8czÎncă nu există evaluări
- Prueba - Python para El Análisis de DatosDocument3 paginiPrueba - Python para El Análisis de Datosrodrigo_ibaceta_1983Încă nu există evaluări
- Guia Didactica Estructura SecuencialesDocument13 paginiGuia Didactica Estructura SecuencialesSullin SantaellaÎncă nu există evaluări
- Configurar A2billing en Menos de 10 MinutosDocument10 paginiConfigurar A2billing en Menos de 10 Minutosyimbi2001Încă nu există evaluări
- 51 Caso - Recopilación de Datos y Tamaño de MuestraDocument9 pagini51 Caso - Recopilación de Datos y Tamaño de MuestraJose Alonso Zeballos PintoÎncă nu există evaluări
- UF1306 - Pruebas de funcionalidades y optimización de páginas webDe la EverandUF1306 - Pruebas de funcionalidades y optimización de páginas webÎncă nu există evaluări
- Sistemas de pruebas y control de la maquetación. ARGP0110De la EverandSistemas de pruebas y control de la maquetación. ARGP0110Încă nu există evaluări
- 115 Ejercicios resueltos de programación C++De la Everand115 Ejercicios resueltos de programación C++Evaluare: 3.5 din 5 stele3.5/5 (7)
- Comprobación y optimización del programa cnc para el mecanizado por arranque de viruta. FMEH0109De la EverandComprobación y optimización del programa cnc para el mecanizado por arranque de viruta. FMEH0109Încă nu există evaluări
- 2do Nivel-Programa de Temas - CATEQUESISDocument7 pagini2do Nivel-Programa de Temas - CATEQUESISgavp2023Încă nu există evaluări
- Solucion Lunes 14 Agosto 2023 Turno Tarde Matematica RM Repaso MCD MCM AptitudDocument19 paginiSolucion Lunes 14 Agosto 2023 Turno Tarde Matematica RM Repaso MCD MCM AptitudanicolleoharaÎncă nu există evaluări
- Procedimiento de Seguridad para Realizar Trabajos en AlturasDocument9 paginiProcedimiento de Seguridad para Realizar Trabajos en AlturasAgueda Herrera EscobedoÎncă nu există evaluări
- Consultas e InformesDocument12 paginiConsultas e InformesDaniel Gaviria HenaoÎncă nu există evaluări
- Estrategias de negociación y resolución de conflictosDocument16 paginiEstrategias de negociación y resolución de conflictosFrancisco Jose Fermin CoffiÎncă nu există evaluări
- Marco Teorico IISDocument12 paginiMarco Teorico IISCristian Gustavo VillcaÎncă nu există evaluări
- SuicidioDocument19 paginiSuicidioJM SalinasÎncă nu există evaluări
- Inteligencia Emocional IiiencuentropatazDocument32 paginiInteligencia Emocional IiiencuentropatazarmidaÎncă nu există evaluări
- PIGB-068x-02 FCT 900-1100MKIIDocument56 paginiPIGB-068x-02 FCT 900-1100MKIIAna Valentina Peila PantojaÎncă nu există evaluări
- Historia de las computadorasDocument9 paginiHistoria de las computadorasLuz Eliana Martinez RamosÎncă nu există evaluări
- La Fiesta de PinkieDocument48 paginiLa Fiesta de PinkieLarzer D LoverlingÎncă nu există evaluări
- Presentación PADRES BACHILLERATO DUAL 2021-2022Document30 paginiPresentación PADRES BACHILLERATO DUAL 2021-2022BasuraÎncă nu există evaluări
- PPP2 Parte 1Document10 paginiPPP2 Parte 1Laura MamaniÎncă nu există evaluări
- Corrección neuropsicológica de alteraciones visoespaciales y su impacto en el aprendizajeDocument11 paginiCorrección neuropsicológica de alteraciones visoespaciales y su impacto en el aprendizajesamsoto86Încă nu există evaluări
- Anexo N°3. MASPS-MN1-IN-3-FR-2 BALANCE DEL ESTADO SOCIALDocument6 paginiAnexo N°3. MASPS-MN1-IN-3-FR-2 BALANCE DEL ESTADO SOCIALangelÎncă nu există evaluări
- Proyecto Pasarela Peatonal AvDocument12 paginiProyecto Pasarela Peatonal AvJhonatan Tejerina BlancoÎncă nu există evaluări
- Límites y ContinuidadDocument7 paginiLímites y ContinuidadDiana Torres100% (1)
- Reporteec Ficharuc 20610449957 20230123154722Document3 paginiReporteec Ficharuc 20610449957 20230123154722George Henry Breña TorresÎncă nu există evaluări
- Ejercicios Aplicación Primera Ley TermodinámicaDocument2 paginiEjercicios Aplicación Primera Ley Termodinámicaxiomara camargoÎncă nu există evaluări
- Los JoniosDocument3 paginiLos JoniosRoss Mery DianaÎncă nu există evaluări
- Al Pueblo Nunca Le Toca 1Document4 paginiAl Pueblo Nunca Le Toca 1Leidy SalamancaÎncă nu există evaluări
- Informe psicopedagógico con diagnóstico de déficit cognitivo leveDocument3 paginiInforme psicopedagógico con diagnóstico de déficit cognitivo leveLu PeñaÎncă nu există evaluări
- Otros Grupos Sanguíneos V2Document36 paginiOtros Grupos Sanguíneos V2Tec Lab BoliviaÎncă nu există evaluări
- Regiones Motoras de La Corteza Cerebral y Vías MotorasDocument37 paginiRegiones Motoras de La Corteza Cerebral y Vías MotorasJUAN SEBASTIAN CHAVERRA APRAEZÎncă nu există evaluări
- Respiración Hapkido PDFDocument14 paginiRespiración Hapkido PDFJEmberVillarroel75% (4)
- Norma Juridica - InformeDocument22 paginiNorma Juridica - InformeMassiel BustillosÎncă nu există evaluări
- PultrusiónDocument8 paginiPultrusiónDaniel VelázquezÎncă nu există evaluări
- Presentación Direccion EstrategicaDocument6 paginiPresentación Direccion EstrategicaCindy Paola Pargas De FreitasÎncă nu există evaluări
- La ColecistitisDocument15 paginiLa ColecistitisMirian MamaniÎncă nu există evaluări
- Trabajo de TermodinámicaDocument9 paginiTrabajo de TermodinámicaCristina IsabelÎncă nu există evaluări