S-ar putea să vă placă și
- IFTTT and Socket ProgrammingDocument4 paginiIFTTT and Socket ProgrammingRagini GuptaÎncă nu există evaluări
- 04-Displays-KeyPad Interfacing PDFDocument35 pagini04-Displays-KeyPad Interfacing PDFRagini GuptaÎncă nu există evaluări
- 11 Output SCC Drivers PDFDocument15 pagini11 Output SCC Drivers PDFRagini GuptaÎncă nu există evaluări
- An Iot Based Smart Energy Management of Hvac SystemDocument9 paginiAn Iot Based Smart Energy Management of Hvac SystemRagini GuptaÎncă nu există evaluări
- FinalWebSockets Final RPiDocument29 paginiFinalWebSockets Final RPiRagini GuptaÎncă nu există evaluări
- 08 Photon IOs Slides PDFDocument27 pagini08 Photon IOs Slides PDFRagini GuptaÎncă nu există evaluări
- 241F2016 Mid2 Keys PDFDocument6 pagini241F2016 Mid2 Keys PDFRagini GuptaÎncă nu există evaluări
- Code-Based Testing of Extended Finite State Machine Models - PPT - v4Document36 paginiCode-Based Testing of Extended Finite State Machine Models - PPT - v4Ragini GuptaÎncă nu există evaluări
- 11 Publish Subscribe - FinalDocument16 pagini11 Publish Subscribe - FinalRagini GuptaÎncă nu există evaluări
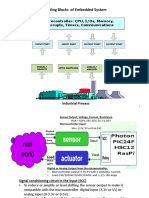
- Basic Building Blocks of Embedded System: Microcontroller: CPU, I/Os, Memory, Interrupts, Timers, CommunicationsDocument23 paginiBasic Building Blocks of Embedded System: Microcontroller: CPU, I/Os, Memory, Interrupts, Timers, CommunicationsRagini GuptaÎncă nu există evaluări
- COE491 Final ReportDocument89 paginiCOE491 Final ReportRagini GuptaÎncă nu există evaluări
- Camera PresentationDocument11 paginiCamera PresentationRagini GuptaÎncă nu există evaluări
- 241F2016 Mid2 Keys PDFDocument6 pagini241F2016 Mid2 Keys PDFRagini GuptaÎncă nu există evaluări
- 03 Interrupts PDFDocument13 pagini03 Interrupts PDFRagini GuptaÎncă nu există evaluări
- 09-Photon-Access Via Cloud PDFDocument20 pagini09-Photon-Access Via Cloud PDFRagini GuptaÎncă nu există evaluări
- 08 Photon IOs Slides PDFDocument27 pagini08 Photon IOs Slides PDFRagini GuptaÎncă nu există evaluări
- 03 Timers Slides PDFDocument69 pagini03 Timers Slides PDFRagini GuptaÎncă nu există evaluări
- 04-Displays-KeyPad Interfacing PDFDocument35 pagini04-Displays-KeyPad Interfacing PDFRagini GuptaÎncă nu există evaluări
- 7-Raspberry Pi Camera Interface-Final PDFDocument27 pagini7-Raspberry Pi Camera Interface-Final PDFRagini Gupta100% (1)
- COE 490 Report22222Document64 paginiCOE 490 Report22222Ragini GuptaÎncă nu există evaluări
- COE341 - Major1 Key - Sp09Document4 paginiCOE341 - Major1 Key - Sp09Ragini GuptaÎncă nu există evaluări
- 02 PIC ADC Final PDFDocument68 pagini02 PIC ADC Final PDFRagini GuptaÎncă nu există evaluări
- 09-Photon-Access Via Cloud PDFDocument20 pagini09-Photon-Access Via Cloud PDFRagini GuptaÎncă nu există evaluări
- COE341 - Major2 Key - Sp09Document3 paginiCOE341 - Major2 Key - Sp09Ragini GuptaÎncă nu există evaluări
- COE341 - Major1 - f08Document3 paginiCOE341 - Major1 - f08Ragini GuptaÎncă nu există evaluări
- COE341 - Major2 Key - f08Document3 paginiCOE341 - Major2 Key - f08Ragini GuptaÎncă nu există evaluări
- 02-Ras Pi Intro and GPIO Interfng-ProgngDocument63 pagini02-Ras Pi Intro and GPIO Interfng-ProgngRagini GuptaÎncă nu există evaluări
- Camera PresentationDocument11 paginiCamera PresentationRagini GuptaÎncă nu există evaluări
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (120)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Session3 EngDocument44 paginiSession3 EngHadare IdrissouÎncă nu există evaluări
- Credit Card Fraud Detection Using Predictive Modeling: A ReviewDocument7 paginiCredit Card Fraud Detection Using Predictive Modeling: A ReviewSampath TÎncă nu există evaluări
- ML Studio OverviewDocument1 paginăML Studio OverviewFulga BogdanÎncă nu există evaluări
- Paper 31-Educational Data Mining Students Performance PredictionDocument9 paginiPaper 31-Educational Data Mining Students Performance PredictionAaron SwartzÎncă nu există evaluări
- E-Commerce Customer PredictionDocument5 paginiE-Commerce Customer PredictionKpsmurugesan KpsmÎncă nu există evaluări
- 06 Data Mining-Data Preprocessing-CleaningDocument6 pagini06 Data Mining-Data Preprocessing-CleaningRaj EndranÎncă nu există evaluări
- Handwritten Digit Recognition Project PaperDocument15 paginiHandwritten Digit Recognition Project PaperSwifty SpotÎncă nu există evaluări
- Area of SPSS Application in ManufacturingDocument21 paginiArea of SPSS Application in ManufacturingppdatÎncă nu există evaluări
- Tests: Implicit CombinationalDocument8 paginiTests: Implicit CombinationalBINOD KUMARÎncă nu există evaluări
- AI Unit 2 NotesDocument37 paginiAI Unit 2 NotesRomaldoÎncă nu există evaluări
- ML Introduction - CLASSIFICATION DECISION TREEDocument18 paginiML Introduction - CLASSIFICATION DECISION TREERijo Jackson TomÎncă nu există evaluări
- Projects2021c3 PDFDocument95 paginiProjects2021c3 PDFSouvik RoyÎncă nu există evaluări
- Course Flyer Course Overview and Sample Certificate Together For Data Science CourseDocument4 paginiCourse Flyer Course Overview and Sample Certificate Together For Data Science CourseBikash MahasethÎncă nu există evaluări
- Module 2 Notes v1 PDFDocument20 paginiModule 2 Notes v1 PDFsuryaÎncă nu există evaluări
- DWDM Unit-3: What Is Classification? What Is Prediction?Document12 paginiDWDM Unit-3: What Is Classification? What Is Prediction?Sai Venkat GudlaÎncă nu există evaluări
- Regression: UNIT - V Regression ModelDocument21 paginiRegression: UNIT - V Regression ModelMadhura PardeshiÎncă nu există evaluări
- S Clémençon ML PDFDocument73 paginiS Clémençon ML PDFAdan OliveiraÎncă nu există evaluări
- RB's ML2 NotesDocument5 paginiRB's ML2 NotesPrasanna ShivakamatÎncă nu există evaluări
- Breast Cancerr MainDocument47 paginiBreast Cancerr MainShreya Panduranga100% (1)
- Geodma For Image ClassificationDocument17 paginiGeodma For Image ClassificationjanetpyÎncă nu există evaluări
- Decision TreeDocument12 paginiDecision TreeshrikrishnaÎncă nu există evaluări
- A Machine Learning Approach To Predict Price of Airlines TicketsDocument7 paginiA Machine Learning Approach To Predict Price of Airlines TicketsIJRASETPublicationsÎncă nu există evaluări
- Machine Learning Lab: Delhi Technological UniversityDocument6 paginiMachine Learning Lab: Delhi Technological UniversityHimanshu SinghÎncă nu există evaluări
- Phoenix API DocumentationDocument16 paginiPhoenix API Documentationwocak64417Încă nu există evaluări
- Machine Learning Methods in Finance: Recent Applications and ProspectsDocument81 paginiMachine Learning Methods in Finance: Recent Applications and ProspectsMilad Ebrahimi DastgerdiÎncă nu există evaluări
- DWMDocument19 paginiDWMrajakammarak100% (1)
- Edureka Data Science Masters Program CurriculumDocument41 paginiEdureka Data Science Masters Program CurriculumMeenal Luther NhürÎncă nu există evaluări
- ML in MedicineDocument5 paginiML in MedicineSanaÎncă nu există evaluări
- Cluster Credit Risk R PDFDocument13 paginiCluster Credit Risk R PDFFabian ChahinÎncă nu există evaluări
- R18B Tech CSE (AIML) IIIIVYearTentativeSyllabusDocument72 paginiR18B Tech CSE (AIML) IIIIVYearTentativeSyllabusPaulson RajuÎncă nu există evaluări