S-ar putea să vă placă și
- Exp 4Document9 paginiExp 4yallasanjay1Încă nu există evaluări
- Exp 3Document9 paginiExp 3Swastik guptaÎncă nu există evaluări
- Back Propagation Learning AlgorithmDocument15 paginiBack Propagation Learning Algorithmমিশা রবিÎncă nu există evaluări
- Adaline Madaline Comes Under The Supervised Learning NetworksDocument8 paginiAdaline Madaline Comes Under The Supervised Learning NetworksNETHALA ANUSHA (N151064)Încă nu există evaluări
- Neural Net 3rdclassDocument35 paginiNeural Net 3rdclassUttam SatapathyÎncă nu există evaluări
- Business Intelligence & Data Mining-10Document39 paginiBusiness Intelligence & Data Mining-10binzidd007Încă nu există evaluări
- Learning Rules of ANNDocument25 paginiLearning Rules of ANNbukyaravindarÎncă nu există evaluări
- Kevin Swingler - Lecture 3: Delta RuleDocument10 paginiKevin Swingler - Lecture 3: Delta RuleRoots999Încă nu există evaluări
- ADALINE For Pattern Classification: Polytechnic University Department of Computer and Information ScienceDocument27 paginiADALINE For Pattern Classification: Polytechnic University Department of Computer and Information ScienceDahlia DevapriyaÎncă nu există evaluări
- Neural NetworksDocument54 paginiNeural NetworksJay AjwaniÎncă nu există evaluări
- 4 Multilayer Perceptrons and Radial Basis FunctionsDocument6 pagini4 Multilayer Perceptrons and Radial Basis FunctionsVivekÎncă nu există evaluări
- Lecture 2.1.2 Single Layer NetworkDocument4 paginiLecture 2.1.2 Single Layer NetworkMuskan GahlawatÎncă nu există evaluări
- Lecture Notes To Neural Networks in Electrical EngineeringDocument11 paginiLecture Notes To Neural Networks in Electrical EngineeringNaeem Ali SajadÎncă nu există evaluări
- DeepLearning Practice Question AnswersDocument43 paginiDeepLearning Practice Question AnswersPaul GeorgeÎncă nu există evaluări
- Soft ComputingDocument40 paginiSoft ComputingEco Frnd Nikhil ChÎncă nu există evaluări
- Ci - Adaline & Madaline NetworkDocument35 paginiCi - Adaline & Madaline NetworkBhavisha SutharÎncă nu există evaluări
- DWDM Lab1Document3 paginiDWDM Lab1shreyastha2058Încă nu există evaluări
- Soft Computing Perceptron Neural Network in MATLABDocument8 paginiSoft Computing Perceptron Neural Network in MATLABSainath ParkarÎncă nu există evaluări
- 3-ADALINE (Adaptive Linear Neuron) (Widrow & Hoff, 1960) : W X T EDocument8 pagini3-ADALINE (Adaptive Linear Neuron) (Widrow & Hoff, 1960) : W X T Emuhanad alkhalisyÎncă nu există evaluări
- Adaptive Linear NeuronDocument4 paginiAdaptive Linear NeuronSelvamÎncă nu există evaluări
- Adaptive Linear NeuronDocument4 paginiAdaptive Linear NeuronSelvamÎncă nu există evaluări
- Back PropagationDocument52 paginiBack PropagationEman zakriaÎncă nu există evaluări
- ARTIFICIAL NEURAL NETWORKS-moduleIIIDocument61 paginiARTIFICIAL NEURAL NETWORKS-moduleIIIelakkadanÎncă nu există evaluări
- The Failure of The Perceptron To Successfully Simple Problem Such As XOR (Minsky and Papert)Document13 paginiThe Failure of The Perceptron To Successfully Simple Problem Such As XOR (Minsky and Papert)iamumpidiÎncă nu există evaluări
- Fast Training of Multilayer PerceptronsDocument15 paginiFast Training of Multilayer Perceptronsgarima_rathiÎncă nu există evaluări
- Multilayer Perceptron Neural NetworkDocument8 paginiMultilayer Perceptron Neural NetworkMaryam FarisÎncă nu există evaluări
- Unsupervised Learning With Artificial Neural NetworksDocument18 paginiUnsupervised Learning With Artificial Neural Networksjimshy123Încă nu există evaluări
- Applicable Artificial Intelligence Back Propagation: Academic Session 2022/2023Document20 paginiApplicable Artificial Intelligence Back Propagation: Academic Session 2022/2023muhammed suhailÎncă nu există evaluări
- AI-Lecture 12 - Simple PerceptronDocument24 paginiAI-Lecture 12 - Simple PerceptronMadiha Nasrullah100% (1)
- Classification AdvancedDocument51 paginiClassification AdvancedBHADORIYA ADITYASINHÎncă nu există evaluări
- Lecture 10 Neural NetworkDocument34 paginiLecture 10 Neural NetworkMohsin IqbalÎncă nu există evaluări
- Week 2Document17 paginiWeek 2madhuÎncă nu există evaluări
- 3 DeltaRule PDFDocument10 pagini3 DeltaRule PDFKrishnamohanÎncă nu există evaluări
- Perceptons Neural NetworksDocument33 paginiPerceptons Neural Networksvasu_koneti5124Încă nu există evaluări
- 3 DeltaRule PDFDocument10 pagini3 DeltaRule PDFEs EÎncă nu există evaluări
- Kohonen Self-Organized Maps: Polytechnic University Department of Computer and Information ScienceDocument20 paginiKohonen Self-Organized Maps: Polytechnic University Department of Computer and Information ScienceZeeShan AnsariÎncă nu există evaluări
- 1 - Single Layer Perceptron ANN SDocument40 pagini1 - Single Layer Perceptron ANN SDumidu GhanasekaraÎncă nu există evaluări
- Or Ve, Tor Referred Re - Peren, e (OrDocument9 paginiOr Ve, Tor Referred Re - Peren, e (OrDHARSHINI SAMPATH KUMARÎncă nu există evaluări
- شبكات عصبية ٢Document6 paginiشبكات عصبية ٢Afkir Al-HusaineÎncă nu există evaluări
- Neural Network and Fuzzy LogicDocument54 paginiNeural Network and Fuzzy Logicshreyas sr100% (1)
- 18au503 123Document28 pagini18au503 123RAJA TÎncă nu există evaluări
- Matlab CodesDocument92 paginiMatlab Codesonlymag4u75% (8)
- Training of Weights: Artificial Neural NetworksDocument12 paginiTraining of Weights: Artificial Neural NetworkstaliqaÎncă nu există evaluări
- Ci - Perceptron Networks1Document43 paginiCi - Perceptron Networks1Bhavisha SutharÎncă nu există evaluări
- Neuron ModelDocument8 paginiNeuron Modelعبد السلام حسينÎncă nu există evaluări
- Adaline and KDocument29 paginiAdaline and KBHAVNA AGARWAL0% (1)
- Manual For Neural and Matlab ApplicationsDocument37 paginiManual For Neural and Matlab ApplicationsKiran Jot SinghÎncă nu există evaluări
- Presentation On: Neural NetworkDocument30 paginiPresentation On: Neural NetworkMuhanad Al-khalisyÎncă nu există evaluări
- Back PropDocument2 paginiBack PropNader Nashat NashedÎncă nu există evaluări
- BackpropergationDocument4 paginiBackpropergationParasecÎncă nu există evaluări
- Lec 2 - Neural Network Perceptron Adaline PDFDocument7 paginiLec 2 - Neural Network Perceptron Adaline PDFLoris FranchiÎncă nu există evaluări
- Supervised Learning Networks: Perceptron Networks Back Propagation NetworksDocument22 paginiSupervised Learning Networks: Perceptron Networks Back Propagation NetworksmohitÎncă nu există evaluări
- CSD311: Artificial IntelligenceDocument12 paginiCSD311: Artificial IntelligenceAyaan KhanÎncă nu există evaluări
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)De la EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)Încă nu există evaluări
- Real Analysis and Probability: Solutions to ProblemsDe la EverandReal Analysis and Probability: Solutions to ProblemsÎncă nu există evaluări
- Understanding Vector Calculus: Practical Development and Solved ProblemsDe la EverandUnderstanding Vector Calculus: Practical Development and Solved ProblemsÎncă nu există evaluări
- Lecture 3. Boolean Algebra, Logic Gates: Prof. Sin-Min Lee Department of Computer ScienceDocument63 paginiLecture 3. Boolean Algebra, Logic Gates: Prof. Sin-Min Lee Department of Computer ScienceMary MorseÎncă nu există evaluări
- Electrical HeatingDocument109 paginiElectrical HeatingMary MorseÎncă nu există evaluări
- Vijay Balu Raskar (BE Electrical)Document25 paginiVijay Balu Raskar (BE Electrical)Mary MorseÎncă nu există evaluări
- Lecture 3 Fuzzy LogicDocument19 paginiLecture 3 Fuzzy LogicMary Morse100% (1)
- Uee Notes-1Document292 paginiUee Notes-1Mary Morse100% (1)
- Professor MD Dutt: Reading Material For B.E. Students of RGPV Affiliated Engineering CollegesDocument20 paginiProfessor MD Dutt: Reading Material For B.E. Students of RGPV Affiliated Engineering CollegesMary MorseÎncă nu există evaluări
- 42 GCSC PDFDocument6 pagini42 GCSC PDFMary MorseÎncă nu există evaluări
- Be CVKR TSSCDocument7 paginiBe CVKR TSSCMary MorseÎncă nu există evaluări
- Deld SylubusDocument2 paginiDeld SylubusMary MorseÎncă nu există evaluări
- Software and Hardware Selection Guide ADRV9001 Adrv9001 Software and Hardware Selection GuideDocument2 paginiSoftware and Hardware Selection Guide ADRV9001 Adrv9001 Software and Hardware Selection GuiderajÎncă nu există evaluări
- M&S Conceptual MapDocument1 paginăM&S Conceptual MapAndres Velez ZapataÎncă nu există evaluări
- Apis PHP en PDFDocument714 paginiApis PHP en PDFAdediran IfeoluwaÎncă nu există evaluări
- Csol 580 Week 7Document8 paginiCsol 580 Week 7api-487513274Încă nu există evaluări
- HANA Master Guide 2.0Document60 paginiHANA Master Guide 2.0BarasatLocal PassengersÎncă nu există evaluări
- Rufus - Create Bootable USB Drives The Easy WayDocument6 paginiRufus - Create Bootable USB Drives The Easy WayÑiechztQS20% (5)
- Call of Duty - Black Ops - Manual - PS3Document14 paginiCall of Duty - Black Ops - Manual - PS3Anonymous utXYfMAXÎncă nu există evaluări
- Game Developer ResumeDocument8 paginiGame Developer Resumedthtrtlfg100% (2)
- 101 Ways To Get Backlinks PDFDocument27 pagini101 Ways To Get Backlinks PDFBilal AhmedÎncă nu există evaluări
- Callister Solution Manual 8th Edition-1Document5 paginiCallister Solution Manual 8th Edition-1Zed TaguilingÎncă nu există evaluări
- Manual PDFDocument202 paginiManual PDFPear KnightÎncă nu există evaluări
- Carlson Software Retail Price List 03-24-15Document29 paginiCarlson Software Retail Price List 03-24-15bechki5Încă nu există evaluări
- AdvanCloud - 170710 - Template DevelopmentDocument60 paginiAdvanCloud - 170710 - Template DevelopmentBrÎncă nu există evaluări
- Keystroke Logging KeyloggingDocument14 paginiKeystroke Logging KeyloggingAnjali100% (1)
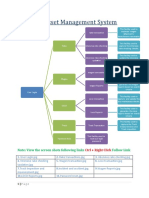
- Rail Asset Management System: Follow LinkDocument4 paginiRail Asset Management System: Follow LinkAbhiroop AwasthiÎncă nu există evaluări
- Sacco SystemDocument65 paginiSacco SystemKamau Wa Wanja50% (2)
- FAQ - Rockwell Automation and Microsoft Product CompatibilityDocument4 paginiFAQ - Rockwell Automation and Microsoft Product CompatibilityjaysonlkhÎncă nu există evaluări
- How To Fix A Windows (Vista, 7 or 10) Corrupt User Profile - The User Profile Service Failed The Logon - Expert ReviewsDocument19 paginiHow To Fix A Windows (Vista, 7 or 10) Corrupt User Profile - The User Profile Service Failed The Logon - Expert ReviewsIzajulianaBintiMohdIhsanÎncă nu există evaluări
- SAM Coupe Users ManualDocument194 paginiSAM Coupe Users ManualcraigmgÎncă nu există evaluări
- Logix 5000 Controlers I/O & Tag DataDocument76 paginiLogix 5000 Controlers I/O & Tag Datafrancois lecreuxÎncă nu există evaluări
- SafariDocument3 paginiSafariAntony MervinÎncă nu există evaluări
- Post Processing Framework (PPF) - SAP Quick GuideDocument6 paginiPost Processing Framework (PPF) - SAP Quick GuideYogitha Balasubramanian100% (1)
- Connection & Operation of RS-232 Option For BF250 Mark 8 ControlDocument17 paginiConnection & Operation of RS-232 Option For BF250 Mark 8 Controlnigh_tmareÎncă nu există evaluări
- MDM 103HF1 BusinessEntityServicesGuide enDocument193 paginiMDM 103HF1 BusinessEntityServicesGuide enjeremy depazÎncă nu există evaluări
- Windows10 Commercial ComparisonDocument1 paginăWindows10 Commercial ComparisoncetelecÎncă nu există evaluări
- NCSC-TG-023 A Guide To Security Testing and Test Documentation in Trusted Systems (Bright Orange Book)Document124 paginiNCSC-TG-023 A Guide To Security Testing and Test Documentation in Trusted Systems (Bright Orange Book)Robert ValeÎncă nu există evaluări
- Apache Jack Rabbit OAK On MongoDB PDFDocument51 paginiApache Jack Rabbit OAK On MongoDB PDFrohitjandialÎncă nu există evaluări
- Ism Prerecorded Training MaterialDocument35 paginiIsm Prerecorded Training MaterialHendra SetiawanÎncă nu există evaluări
- CoP027 Power Point StandardsDocument2 paginiCoP027 Power Point StandardsORBeducationÎncă nu există evaluări
- Zünd Cut Center: Digital Cutting WorkflowDocument6 paginiZünd Cut Center: Digital Cutting WorkflowMirjana EricÎncă nu există evaluări