S-ar putea să vă placă și
- Logarithmic Functions Week 7Document20 paginiLogarithmic Functions Week 7gadraÎncă nu există evaluări
- Instructor's Manual to Accompany CALCULUS WITH ANALYTIC GEOMETRYDe la EverandInstructor's Manual to Accompany CALCULUS WITH ANALYTIC GEOMETRYÎncă nu există evaluări
- Mathematics 1St First Order Linear Differential Equations 2Nd Second Order Linear Differential Equations Laplace Fourier Bessel MathematicsDe la EverandMathematics 1St First Order Linear Differential Equations 2Nd Second Order Linear Differential Equations Laplace Fourier Bessel MathematicsÎncă nu există evaluări
- Normal DistributionDocument59 paginiNormal DistributionAkash Katariya100% (1)
- Application of Derivatives Tangents and Normals (Calculus) Mathematics E-Book For Public ExamsDe la EverandApplication of Derivatives Tangents and Normals (Calculus) Mathematics E-Book For Public ExamsEvaluare: 5 din 5 stele5/5 (1)
- Chapter 1 - Part 1 Introduction To Organic ChemistryDocument43 paginiChapter 1 - Part 1 Introduction To Organic ChemistryqilahmazlanÎncă nu există evaluări
- IMCI UpdatedDocument5 paginiIMCI UpdatedMalak RagehÎncă nu există evaluări
- Lecture3 NaDocument73 paginiLecture3 NaMJ RoxasÎncă nu există evaluări
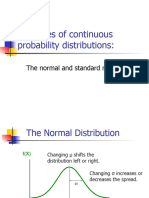
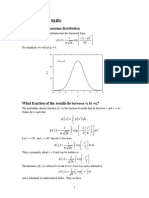
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument21 paginiExamples of Continuous Probability Distributions:: The Normal and Standard NormalAbhilash RudraÎncă nu există evaluări
- Normal Distribution: It'S A Normal Thing!Document20 paginiNormal Distribution: It'S A Normal Thing!Arjun NkÎncă nu există evaluări
- WINSEM2023-24 BMAT202L TH VL2023240502271 2024-03-06 Reference-Material-IDocument19 paginiWINSEM2023-24 BMAT202L TH VL2023240502271 2024-03-06 Reference-Material-Impkvarun69Încă nu există evaluări
- WINSEM2019 20 MAT2001 ELA VL2019205002696 Reference Material I 31 Jan 2020 7 R LAB Normal DistributionDocument39 paginiWINSEM2019 20 MAT2001 ELA VL2019205002696 Reference Material I 31 Jan 2020 7 R LAB Normal DistributionasÎncă nu există evaluări
- WINSEM2019-20 MAT2001 ELA VL2019205002696 Reference Material I 31-Jan-2020 7 R LAB - Normal DistributionDocument38 paginiWINSEM2019-20 MAT2001 ELA VL2019205002696 Reference Material I 31-Jan-2020 7 R LAB - Normal Distributionjeevan saiÎncă nu există evaluări
- Probability DistributionDocument21 paginiProbability DistributionBintay HawaÎncă nu există evaluări
- BS UNIT 2 Normal Distribution NewDocument41 paginiBS UNIT 2 Normal Distribution NewSherona ReidÎncă nu există evaluări
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument57 paginiExamples of Continuous Probability Distributions:: The Normal and Standard NormalAkshay VetalÎncă nu există evaluări
- Lekcija 5 - VjerovatnocaDocument60 paginiLekcija 5 - VjerovatnocaАнђела МијановићÎncă nu există evaluări
- Examples of Continuous Probability Distributions:: The Normal and Standard NormalDocument57 paginiExamples of Continuous Probability Distributions:: The Normal and Standard NormalPawan JajuÎncă nu există evaluări
- Analisis Regresi Sederhana Dan Berganda (Teori Dan Praktik)Document53 paginiAnalisis Regresi Sederhana Dan Berganda (Teori Dan Praktik)Rizki Fadlina HarahapÎncă nu există evaluări
- Normal: A Random Variable X Having A Probability Density Function Given by The FormulaDocument38 paginiNormal: A Random Variable X Having A Probability Density Function Given by The FormulaShruti KapoorÎncă nu există evaluări
- Normal Distribution 2003Document22 paginiNormal Distribution 2003judefrances100% (1)
- Orientation Programme To Promote Use of ICTDocument26 paginiOrientation Programme To Promote Use of ICTshalukprÎncă nu există evaluări
- QTM Cycle 7 Session 4Document79 paginiQTM Cycle 7 Session 4OttilieÎncă nu există evaluări
- Statistik Norm Distribution: Lab. Teknologi Dan Manajemen Agroindustri Fakultas Teknologi Pertanian Universitas JemberDocument44 paginiStatistik Norm Distribution: Lab. Teknologi Dan Manajemen Agroindustri Fakultas Teknologi Pertanian Universitas JemberviayÎncă nu există evaluări
- CHAPTER 2. Random Variables and Probability DistributionsDocument22 paginiCHAPTER 2. Random Variables and Probability DistributionsQuyên Nguyễn HảiÎncă nu există evaluări
- Cauchy-Euler Equation:: Dy D Y Dy Ax Ax Ax Ayq DX DX DX Aa Aa Xe DT X E T X DX X Xe T X D D DX D DT XDDocument9 paginiCauchy-Euler Equation:: Dy D Y Dy Ax Ax Ax Ayq DX DX DX Aa Aa Xe DT X E T X DX X Xe T X D D DX D DT XDSanjar AbbasiÎncă nu există evaluări
- Expectation and VarianceDocument16 paginiExpectation and VarianceWahab HassanÎncă nu există evaluări
- Ordinary Differential EquationDocument17 paginiOrdinary Differential EquationAnang KadarsahÎncă nu există evaluări
- This Study Resource Was: Operations ResearchDocument6 paginiThis Study Resource Was: Operations ResearchReyal MohanÎncă nu există evaluări
- 6592 - A1 QuestionsDocument14 pagini6592 - A1 QuestionsYuhan KEÎncă nu există evaluări
- 1B40 Practical Skills: Properties of The Gaussian DistributionDocument3 pagini1B40 Practical Skills: Properties of The Gaussian DistributionRoy VeseyÎncă nu există evaluări
- Materi Statistik 2Document27 paginiMateri Statistik 2ERISTRA NUNGSATRIA TRESNA ERNAWANÎncă nu există evaluări
- Multistat PV PCADocument42 paginiMultistat PV PCAFTQCDO DamauliÎncă nu există evaluări
- Lecture 6Document28 paginiLecture 6Angel Borbon GabaldonÎncă nu există evaluări
- 5 DispersionDocument33 pagini5 DispersionZunaeid Mahmud LamÎncă nu există evaluări
- Term 1: Business Statistics: Session 4: Continuous Probability DistributionsDocument26 paginiTerm 1: Business Statistics: Session 4: Continuous Probability DistributionsTanuj LalchandaniÎncă nu există evaluări
- Patter Recognition (Spring 2013) Midterm ExamDocument4 paginiPatter Recognition (Spring 2013) Midterm ExamranaÎncă nu există evaluări
- Chapter 1Document27 paginiChapter 1Bereket Desalegn0% (1)
- Covariance, Correlation CoefficientDocument4 paginiCovariance, Correlation CoefficientIvan ZhuravlevÎncă nu există evaluări
- Stat 100a: Introduction To ProbabilityDocument9 paginiStat 100a: Introduction To ProbabilityJun Kai OngÎncă nu există evaluări
- Continuous Probability DistributionsDocument38 paginiContinuous Probability DistributionsraachelongÎncă nu există evaluări
- ClassDocument35 paginiClassBoukezoula Med AliÎncă nu există evaluări
- Differential Equations: Definition 1Document9 paginiDifferential Equations: Definition 1Marielle Lucas GabrielÎncă nu există evaluări
- Ch5 - Response of MDOF Systems PDFDocument37 paginiCh5 - Response of MDOF Systems PDFRicky AriyantoÎncă nu există evaluări
- Homework 1 SolutionDocument6 paginiHomework 1 SolutionDante CristoÎncă nu există evaluări
- Chapter 04 Systems of ODEs. Phase Plane. Qualitative MethodsDocument6 paginiChapter 04 Systems of ODEs. Phase Plane. Qualitative MethodsSider HsiaoÎncă nu există evaluări
- Lecture II - NormaldsitDocument43 paginiLecture II - Normaldsitmanuelmbiawa30Încă nu există evaluări
- Stat 110, Lecture 7 Continuous Probability Distributions: Bheavlin@stat - Stanford.eduDocument35 paginiStat 110, Lecture 7 Continuous Probability Distributions: Bheavlin@stat - Stanford.edujamesyuÎncă nu există evaluări
- Numerical Methods: Marisa Villano, Tom Fagan, Dave Fairburn, Chris Savino, David Goldberg, Daniel RaveDocument44 paginiNumerical Methods: Marisa Villano, Tom Fagan, Dave Fairburn, Chris Savino, David Goldberg, Daniel RaveSanjeev DwivediÎncă nu există evaluări
- Variation and Quality: MIT 2.008xDocument80 paginiVariation and Quality: MIT 2.008xNurlanÎncă nu există evaluări
- Models For Control Part I: Overview: CBE341 Professor Jay H. Lee KaistDocument99 paginiModels For Control Part I: Overview: CBE341 Professor Jay H. Lee Kaist이정우Încă nu există evaluări
- Math 285 Formula SheetDocument2 paginiMath 285 Formula SheetjosiahgerberÎncă nu există evaluări
- Quiz 3 Solution (No 1-4)Document3 paginiQuiz 3 Solution (No 1-4)irhamÎncă nu există evaluări
- Harvesting in A Competitive Environment FinalDocument11 paginiHarvesting in A Competitive Environment FinalEugene LiÎncă nu există evaluări
- Statistical Inference For Engineers and Data Scientists Solutions ManualDocument12 paginiStatistical Inference For Engineers and Data Scientists Solutions ManualJashaswini bhuyanÎncă nu există evaluări
- Math644 - Chapter 1 - Part2 PDFDocument14 paginiMath644 - Chapter 1 - Part2 PDFaftab20Încă nu există evaluări
- Pr (X ≤x) =F (x) = 1 2πσ 1 2πσ: Φ (z) = e dtDocument8 paginiPr (X ≤x) =F (x) = 1 2πσ 1 2πσ: Φ (z) = e dtKimondo KingÎncă nu există evaluări
- Chapter 1 SolutionDocument5 paginiChapter 1 SolutionFaraa BellaÎncă nu există evaluări
- 5 5weDocument7 pagini5 5weJhonatan AguirreÎncă nu există evaluări
- 24-01-22 Marked SlidesDocument50 pagini24-01-22 Marked Slideselyan.dummyaccÎncă nu există evaluări
- Setting Times of ConcreteDocument3 paginiSetting Times of ConcreteP DhanunjayaÎncă nu există evaluări
- Operating Manual CSDPR-V2-200-NDocument19 paginiOperating Manual CSDPR-V2-200-NJohnTPÎncă nu există evaluări
- A Collection of Ideas For The Chemistry Classroom by Jeff HepburnDocument14 paginiA Collection of Ideas For The Chemistry Classroom by Jeff HepburnPaul SchumannÎncă nu există evaluări
- Introduction To The New 8-Bit PIC MCU Hardware Peripherals (CLC, Nco, Cog)Document161 paginiIntroduction To The New 8-Bit PIC MCU Hardware Peripherals (CLC, Nco, Cog)Andres Bruno SaraviaÎncă nu există evaluări
- Curso VII Lectura 2. New Rural Social MovementsDocument12 paginiCurso VII Lectura 2. New Rural Social MovementsFausto Inzunza100% (1)
- Nitofloor NDocument3 paginiNitofloor Nkiranmisale7Încă nu există evaluări
- Company Profile Pt. KPT PDFDocument23 paginiCompany Profile Pt. KPT PDFfery buyaÎncă nu există evaluări
- API Casing Collapse CalcsDocument8 paginiAPI Casing Collapse CalcsJay SadÎncă nu există evaluări
- CM Bu9000 Eng Bushings 3Document36 paginiCM Bu9000 Eng Bushings 3ing.dmanriq27100% (1)
- Camouflage Lesson PlanDocument4 paginiCamouflage Lesson Planapi-344569443Încă nu există evaluări
- Need For Advanced Suspension SystemsDocument10 paginiNeed For Advanced Suspension SystemsIQPC GmbHÎncă nu există evaluări
- Practical 3.1 Determining The Specific Heat CapacityDocument3 paginiPractical 3.1 Determining The Specific Heat CapacityiAlex11Încă nu există evaluări
- Technical Design of The Bukwimba Open Pit Final 12042017Document31 paginiTechnical Design of The Bukwimba Open Pit Final 12042017Rozalia PengoÎncă nu există evaluări
- What A Wonderful WorldDocument3 paginiWhat A Wonderful Worldapi-333684519Încă nu există evaluări
- Pertanyaan TK PDBDocument4 paginiPertanyaan TK PDBHardenÎncă nu există evaluări
- MAP V6.3: Reference ManualDocument106 paginiMAP V6.3: Reference ManualGkou DojkuÎncă nu există evaluări
- Burst Abdomen 3Document12 paginiBurst Abdomen 3Satvik BansalÎncă nu există evaluări
- Massage Techniques in SpaDocument1 paginăMassage Techniques in SpaALISA SAITAÎncă nu există evaluări
- Habitat Preference of Great Argus Pheasant ArgusiaDocument11 paginiHabitat Preference of Great Argus Pheasant ArgusiaFaradlina MuftiÎncă nu există evaluări
- The Moon That Embrace The SunDocument36 paginiThe Moon That Embrace The SunNorma PuspitaÎncă nu există evaluări
- DUPIXENT Doctor Discussion GuideDocument4 paginiDUPIXENT Doctor Discussion GuideTAP THANH CHAUÎncă nu există evaluări
- American Pile Driving Equipment Equipment CatalogDocument25 paginiAmerican Pile Driving Equipment Equipment CatalogW Morales100% (1)
- Prakab Export 20.8.2018 UkDocument260 paginiPrakab Export 20.8.2018 UkREN JTNÎncă nu există evaluări
- Design of Cycle Rickshaw For School ChildrenDocument23 paginiDesign of Cycle Rickshaw For School ChildrenAditya GuptaÎncă nu există evaluări
- ReagentsDocument12 paginiReagentsKimscey Yvan DZ SulitÎncă nu există evaluări
- Accessories 162-USDocument20 paginiAccessories 162-USعايد التعزيÎncă nu există evaluări
- Mechanism Design: A SeriesDocument3 paginiMechanism Design: A Seriesamirmasood kholojiniÎncă nu există evaluări