S-ar putea să vă placă și
- WEF Future of Jobs MarkedDocument167 paginiWEF Future of Jobs Markedharuhi.karasunoÎncă nu există evaluări
- The Petrolist - DIY - How To Make A BuzzcoilDocument4 paginiThe Petrolist - DIY - How To Make A BuzzcoilDerrick KimaniÎncă nu există evaluări
- Software License: Offline ActivationDocument3 paginiSoftware License: Offline ActivationDerrick KimaniÎncă nu există evaluări
- The Productivity of Working Hours, John Pencal - Standford UniversityDocument57 paginiThe Productivity of Working Hours, John Pencal - Standford UniversityMihai IvaşcuÎncă nu există evaluări
- Books - TheOldScientistDocument9 paginiBooks - TheOldScientistDerrick KimaniÎncă nu există evaluări
- Flavor Water For About $20 - FacebookDocument6 paginiFlavor Water For About $20 - FacebookDerrick KimaniÎncă nu există evaluări
- PDFDocument1 paginăPDFDerrick KimaniÎncă nu există evaluări
- Career Success PDFDocument22 paginiCareer Success PDFDerrick KimaniÎncă nu există evaluări
- Helping Your Child Learn Science - US Dept. of EducationDocument39 paginiHelping Your Child Learn Science - US Dept. of EducationScarlettNyxÎncă nu există evaluări
- HDocument2 paginiHDerrick KimaniÎncă nu există evaluări
- The Gospel Witness of The Stars: 2Nd ComingDocument1 paginăThe Gospel Witness of The Stars: 2Nd ComingDerrick KimaniÎncă nu există evaluări
- 2089Document10 pagini2089Derrick KimaniÎncă nu există evaluări
- 7f39f8317fbdb1988ef4c628eba02591Document1 pagină7f39f8317fbdb1988ef4c628eba02591Derrick KimaniÎncă nu există evaluări
- Cyclos PRO Prices: Classification Number of Users Turnover Initial Fee Yearly FeeDocument1 paginăCyclos PRO Prices: Classification Number of Users Turnover Initial Fee Yearly FeeDerrick KimaniÎncă nu există evaluări
- Sirius Times 2006 ModifiedDocument30 paginiSirius Times 2006 ModifiedDerrick Kimani100% (5)
- Mpe Saw RapperDocument29 paginiMpe Saw RapperDerrick KimaniÎncă nu există evaluări
- Râna and The Hakras: Theosophy Presented in Graphical FormDocument22 paginiRâna and The Hakras: Theosophy Presented in Graphical Formpankarvi6Încă nu există evaluări
- Indian Forest Act 1927Document26 paginiIndian Forest Act 1927Dinesh GuptaÎncă nu există evaluări
- The Banishing Ritual of The Hexagram: y H W HDocument4 paginiThe Banishing Ritual of The Hexagram: y H W HDerrick KimaniÎncă nu există evaluări
- Science PDFDocument32 paginiScience PDFDerrick KimaniÎncă nu există evaluări
- ScienceDocument8 paginiScienceDerrick KimaniÎncă nu există evaluări
- Indian Forest ActDocument9 paginiIndian Forest ActDerrick KimaniÎncă nu există evaluări
- What Is ScienceDocument22 paginiWhat Is SciencerebeccabarrowÎncă nu există evaluări
- MT Sacred MissionDocument44 paginiMT Sacred MissionLouis De BroglieÎncă nu există evaluări
- Llewellyn Practical Psychic Powers PDFDocument250 paginiLlewellyn Practical Psychic Powers PDFicanadaa100% (1)
- Advanced High-School - David B. SurowskiDocument435 paginiAdvanced High-School - David B. SurowskiSanotestÎncă nu există evaluări
- POLANYI, M. The Republic of Science.Document20 paginiPOLANYI, M. The Republic of Science.Suzi Da Costa TeixeiraÎncă nu există evaluări
- SECTION 1 - Instructions To The Individual and State-Licensed PhysicianDocument9 paginiSECTION 1 - Instructions To The Individual and State-Licensed PhysicianDerrick KimaniÎncă nu există evaluări
- I Just Learned How To Say Something HugeDocument1 paginăI Just Learned How To Say Something HugeDerrick KimaniÎncă nu există evaluări
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Paraphrasing ExercisesDocument4 paginiParaphrasing ExercisesPaulinaÎncă nu există evaluări
- 2 Forex Game TheoryDocument36 pagini2 Forex Game TheoryKareem El Malki100% (1)
- Back To Basics - The Fundamentals of 4-20 MA Current Loops - Precision DigitalDocument5 paginiBack To Basics - The Fundamentals of 4-20 MA Current Loops - Precision DigitalJason FloydÎncă nu există evaluări
- 2023 Occ 1ST ExamDocument3 pagini2023 Occ 1ST ExamSamantha LaboÎncă nu există evaluări
- General Awareness Questions Asked CGL17 - 10 PDFDocument13 paginiGeneral Awareness Questions Asked CGL17 - 10 PDFKishorMehtaÎncă nu există evaluări
- Anthropology and Architecture: A Misplaced Conversation: Architectural Theory ReviewDocument4 paginiAnthropology and Architecture: A Misplaced Conversation: Architectural Theory ReviewSonora GuantánamoÎncă nu există evaluări
- ManualVsk5 enDocument23 paginiManualVsk5 ent0manÎncă nu există evaluări
- Art EducationDocument13 paginiArt EducationJaime MorrisÎncă nu există evaluări
- Physics of CheerleadingDocument1 paginăPhysics of CheerleadingMarniella BeridoÎncă nu există evaluări
- E3 - Identify Purpose of Components and Build CircuitsDocument2 paginiE3 - Identify Purpose of Components and Build Circuitsapi-316704749Încă nu există evaluări
- Face Recognition Using Artificial Neural NetworkDocument10 paginiFace Recognition Using Artificial Neural NetworkMayankÎncă nu există evaluări
- Joseph Cote WeeblyDocument2 paginiJoseph Cote Weeblyapi-232220181Încă nu există evaluări
- Practices of A MultiplierDocument24 paginiPractices of A MultiplierBarry FeldmanÎncă nu există evaluări
- Proceedings of The Society For Medieval Logic & Metaphysics 3Document81 paginiProceedings of The Society For Medieval Logic & Metaphysics 3MeatredÎncă nu există evaluări
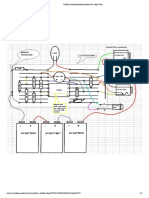
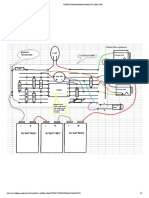
- Volt White DocumentationDocument2 paginiVolt White DocumentationSantiago Rodriguez ArenasÎncă nu există evaluări
- (YDM) Ambo University Phy ExamDocument8 pagini(YDM) Ambo University Phy ExamYdm DmaÎncă nu există evaluări
- CharacterSheet - Slayer LVL 7 - AlexDocument2 paginiCharacterSheet - Slayer LVL 7 - AlexMariano de la PeñaÎncă nu există evaluări
- Elaine Risley's Character DevelopmentDocument12 paginiElaine Risley's Character Developmenterlooay100% (1)
- Basic ConceptsDocument96 paginiBasic ConceptsMuthu KumarÎncă nu există evaluări
- Chap 1 Abhiram RanadeDocument40 paginiChap 1 Abhiram RanadeSagar Addepalli0% (1)
- UT Dallas Syllabus For cs4349.001 05f Taught by Ovidiu Daescu (Daescu)Document4 paginiUT Dallas Syllabus For cs4349.001 05f Taught by Ovidiu Daescu (Daescu)UT Dallas Provost's Technology GroupÎncă nu există evaluări
- Gestalt Peeling The Onion Csi Presentatin March 12 2011Document6 paginiGestalt Peeling The Onion Csi Presentatin March 12 2011Adriana Bogdanovska ToskicÎncă nu există evaluări
- Gas Laws Physics Lab ReportDocument10 paginiGas Laws Physics Lab Reportشاہ سعودÎncă nu există evaluări
- Automatic Selection by Penalized Asymmetric L - Norm in An High-Dimensional Model With Grouped VariablesDocument39 paginiAutomatic Selection by Penalized Asymmetric L - Norm in An High-Dimensional Model With Grouped VariablesMarcelo Marcy Majstruk CimilloÎncă nu există evaluări
- Recovering The Essence in Language - EssayDocument3 paginiRecovering The Essence in Language - EssayOnel1Încă nu există evaluări
- HSE Communication ProcedureDocument7 paginiHSE Communication ProcedureWanda QurniaÎncă nu există evaluări
- Global DemographyDocument4 paginiGlobal DemographyCantes C. VincentÎncă nu există evaluări
- Colegio Tecnico Profesional Santo DomingoDocument3 paginiColegio Tecnico Profesional Santo DomingoStaling BFloresÎncă nu există evaluări
- An Understanding of Psychometric ToolsDocument4 paginiAn Understanding of Psychometric ToolsAntariksh Bhandari100% (1)
- OdorizationDocument5 paginiOdorizationShreya Sahajpal KaushalÎncă nu există evaluări