S-ar putea să vă placă și
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (120)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- SSP-NR 550 The Passat GTE PDFDocument72 paginiSSP-NR 550 The Passat GTE PDFan89% (9)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Forensic BallisticDocument18 paginiForensic BallisticFranco Angelo ReyesÎncă nu există evaluări
- Coconut Fibre Reinforced Concrete: April 2015Document77 paginiCoconut Fibre Reinforced Concrete: April 2015mohammed shoaibÎncă nu există evaluări
- KeyDocument1 paginăKeyTechnico TechnocratsÎncă nu există evaluări
- 3Document1 pagină3Technico TechnocratsÎncă nu există evaluări
- 1Document1 pagină1Technico TechnocratsÎncă nu există evaluări
- Coconut Fibre Reinforced Concrete: April 2015Document77 paginiCoconut Fibre Reinforced Concrete: April 2015mohammed shoaibÎncă nu există evaluări
- Secure Distributed Deduplication Systems With Improved Reliability PDFDocument11 paginiSecure Distributed Deduplication Systems With Improved Reliability PDFTechnico TechnocratsÎncă nu există evaluări
- PasswordDocument44 paginiPasswordTechnico TechnocratsÎncă nu există evaluări
- PrismDocument12 paginiPrismTechnico TechnocratsÎncă nu există evaluări
- Civil Engineering Projects TittlesDocument5 paginiCivil Engineering Projects TittlesTechnico TechnocratsÎncă nu există evaluări
- 6 ChaptersDocument39 pagini6 ChaptersTechnico TechnocratsÎncă nu există evaluări
- Apartment Footing, Staircase DetailsDocument4 paginiApartment Footing, Staircase DetailsTechnico TechnocratsÎncă nu există evaluări
- Finger Print Based Students Attendance SystemsDocument44 paginiFinger Print Based Students Attendance SystemsTechnico TechnocratsÎncă nu există evaluări
- Doctors Assistive System Using Augumented Reality For Critical AnalysisDocument2 paginiDoctors Assistive System Using Augumented Reality For Critical AnalysisTechnico TechnocratsÎncă nu există evaluări
- An Adaptive Filtering Based Enhancement of Hand Vein Images With Random Transform For User IdentificationDocument1 paginăAn Adaptive Filtering Based Enhancement of Hand Vein Images With Random Transform For User IdentificationTechnico TechnocratsÎncă nu există evaluări
- Steganography Based File HidingDocument35 paginiSteganography Based File HidingTechnico TechnocratsÎncă nu există evaluări
- Screen ShootsDocument10 paginiScreen ShootsTechnico TechnocratsÎncă nu există evaluări
- Health Care MonitorDocument67 paginiHealth Care MonitorTechnico TechnocratsÎncă nu există evaluări
- Data HidingDocument67 paginiData HidingTechnico TechnocratsÎncă nu există evaluări
- Face-To-Face Proximity Estimation Using Bluetooth On SmartphonesDocument3 paginiFace-To-Face Proximity Estimation Using Bluetooth On SmartphonesTechnico TechnocratsÎncă nu există evaluări
- Physical Layer Security in ThreeDocument5 paginiPhysical Layer Security in ThreeTechnico TechnocratsÎncă nu există evaluări
- Data Hidding WavDocument2 paginiData Hidding WavTechnico TechnocratsÎncă nu există evaluări
- Vehicle Monitering and Security SystemDocument36 paginiVehicle Monitering and Security SystemTechnico TechnocratsÎncă nu există evaluări
- SNO Title Pageno Indroduction: Project DescriptionDocument3 paginiSNO Title Pageno Indroduction: Project DescriptionTechnico TechnocratsÎncă nu există evaluări
- Warehouse Management SystemDocument3 paginiWarehouse Management SystemTechnico TechnocratsÎncă nu există evaluări
- MP3Stego Hiding Text in MP3 Files SCREENSHOTDocument22 paginiMP3Stego Hiding Text in MP3 Files SCREENSHOTTechnico TechnocratsÎncă nu există evaluări
- A New Technology Electrolyte Fueling Chemical For Industry'sDocument14 paginiA New Technology Electrolyte Fueling Chemical For Industry'sTechnico TechnocratsÎncă nu există evaluări
- Working Principle Atm Based OtpDocument21 paginiWorking Principle Atm Based OtpTechnico TechnocratsÎncă nu există evaluări
- Automatic Gear Shifting Mechanism For Two WheelerDocument28 paginiAutomatic Gear Shifting Mechanism For Two WheelerTechnico TechnocratsÎncă nu există evaluări
- A New Class of Corrosion Inhibition of HighDocument14 paginiA New Class of Corrosion Inhibition of HighTechnico TechnocratsÎncă nu există evaluări
- Document FlywheelDocument42 paginiDocument FlywheelTechnico TechnocratsÎncă nu există evaluări
- Hybrid Nanophotonics: Review of Actual ProblemsDocument68 paginiHybrid Nanophotonics: Review of Actual ProblemsTarun SinghalÎncă nu există evaluări
- ReportDocument1 paginăReportDrew DacanayÎncă nu există evaluări
- Quadratic Equation - MATH IS FUNDocument8 paginiQuadratic Equation - MATH IS FUNChanchan LebumfacilÎncă nu există evaluări
- Example 1 Strip Method VitalDocument15 paginiExample 1 Strip Method Vitalbini122150% (2)
- Beckman Coulter GenomeLab TroubleshootDocument56 paginiBeckman Coulter GenomeLab TroubleshootChrisÎncă nu există evaluări
- Fangming Heng Thesis 2015Document147 paginiFangming Heng Thesis 2015keanshengÎncă nu există evaluări
- Fdot Modifications To LRFD Specifications For Structural Supports For Highway Signs, Luminaires and Traffic Signals (Lrfdlts-1)Document26 paginiFdot Modifications To LRFD Specifications For Structural Supports For Highway Signs, Luminaires and Traffic Signals (Lrfdlts-1)kayshephÎncă nu există evaluări
- 5Document20 pagini5AndriansyahÎncă nu există evaluări
- 5000 KW Gearbox High Pinion Bearing Temperatures 1644227029Document7 pagini5000 KW Gearbox High Pinion Bearing Temperatures 1644227029MC AÎncă nu există evaluări
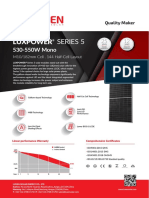
- LUXEN SERIES 5 182 144cells 530-550w MONOFACIALDocument2 paginiLUXEN SERIES 5 182 144cells 530-550w MONOFACIALOscar DuduÎncă nu există evaluări
- Miestamo Wagner-Nagy 08Document15 paginiMiestamo Wagner-Nagy 08AdjepoleÎncă nu există evaluări
- 2200SRM1266 (06 2006) Uk enDocument28 pagini2200SRM1266 (06 2006) Uk enEbied Yousif Aly100% (9)
- Survey CE1011Document34 paginiSurvey CE1011san htet aung100% (3)
- Dawood University of Engineering & Technology Karachi Department of Basic Sciences & HumanitiesDocument4 paginiDawood University of Engineering & Technology Karachi Department of Basic Sciences & HumanitiessamadÎncă nu există evaluări
- GravimetryDocument31 paginiGravimetrysvsaikumarÎncă nu există evaluări
- ArticleDocument10 paginiArticlePrachiÎncă nu există evaluări
- R134a HXWC Series Water Cooled Screw Flooded Chillers Cooling Capacity 200 To 740 Tons 703 To 2603 KW Products That Perform PDFDocument16 paginiR134a HXWC Series Water Cooled Screw Flooded Chillers Cooling Capacity 200 To 740 Tons 703 To 2603 KW Products That Perform PDFmohamad chaudhariÎncă nu există evaluări
- Research MethodsDocument10 paginiResearch MethodsAhimbisibwe BenyaÎncă nu există evaluări
- TRM Reb670Document490 paginiTRM Reb670jayapalÎncă nu există evaluări
- Handout Basic Electrical and Electronics AllisonDocument6 paginiHandout Basic Electrical and Electronics AllisonSRIREKHAÎncă nu există evaluări
- Digital Image ProcessingDocument156 paginiDigital Image ProcessingAnushka BajpaiÎncă nu există evaluări
- Topcon GLS 2200Document2 paginiTopcon GLS 2200asepali005Încă nu există evaluări
- LuK Tractor Diagnosis LQDocument20 paginiLuK Tractor Diagnosis LQZam BiloiuÎncă nu există evaluări
- GEM4D Geotech Block Models Process DescriptionDocument5 paginiGEM4D Geotech Block Models Process DescriptionMarcos GuimarãesÎncă nu există evaluări
- Computer Programming: College of Civil Engineering - First StageDocument5 paginiComputer Programming: College of Civil Engineering - First StageAli AÎncă nu există evaluări
- Case Study - CCNA - Sem1 - Cosmin Daniel POCRISTEDocument7 paginiCase Study - CCNA - Sem1 - Cosmin Daniel POCRISTEcosmin_horusÎncă nu există evaluări
- Ch02HullOFOD9thEdition - EditedDocument31 paginiCh02HullOFOD9thEdition - EditedHarshvardhan MohataÎncă nu există evaluări
- UNIX Intro and Basic C Shell Scripting: Khaldoun Makhoul Khaldoun@nmr - Mgh.harvard - EduDocument36 paginiUNIX Intro and Basic C Shell Scripting: Khaldoun Makhoul Khaldoun@nmr - Mgh.harvard - Edudaitoan402Încă nu există evaluări