S-ar putea să vă placă și
- Statistics - Conditional Probability - Bayes' Theorem - Mathematics Stack ExchangeDocument3 paginiStatistics - Conditional Probability - Bayes' Theorem - Mathematics Stack ExchangeAmitÎncă nu există evaluări
- Staticstical Induction Probability of Sample Spaces and EventsDocument17 paginiStaticstical Induction Probability of Sample Spaces and EventsArt IjbÎncă nu există evaluări
- Bayes TheoremDocument10 paginiBayes TheoremHussain NJÎncă nu există evaluări
- Bayes TheoremDocument9 paginiBayes TheoremhariputarÎncă nu există evaluări
- Group No 3 AssignmentDocument4 paginiGroup No 3 AssignmentWinifridaÎncă nu există evaluări
- Powerpoint Trial Class 16.1.2021Document65 paginiPowerpoint Trial Class 16.1.2021Ktc Desa CemerlangÎncă nu există evaluări
- Managerial CommunicationDocument25 paginiManagerial CommunicationMuhammad Achar BozdarÎncă nu există evaluări
- Excel Example BomsDocument11 paginiExcel Example BomsTueÎncă nu există evaluări
- SSau ExercisesDocument6 paginiSSau Exercisessweetie05Încă nu există evaluări
- Anger ManagementDocument5 paginiAnger ManagementVaibhav RatraÎncă nu există evaluări
- A Survey of Probability ConceptsDocument42 paginiA Survey of Probability ConceptsJacquelynne SjostromÎncă nu există evaluări
- Question3 MckinseyDocument1 paginăQuestion3 MckinseyGloryÎncă nu există evaluări
- Bayes' TheoremDocument10 paginiBayes' TheoremYuri SagalaÎncă nu există evaluări
- 16-Ethics and BusinessDocument2 pagini16-Ethics and Businessbruce_doÎncă nu există evaluări
- Organizational BehaviorDocument7 paginiOrganizational Behaviorswaroop666Încă nu există evaluări
- JachimoDocument28 paginiJachimo'mCharity ToniiÎncă nu există evaluări
- Production and Operations Management Core Course Teaching at The Top 20 MBA Programmes in The USADocument36 paginiProduction and Operations Management Core Course Teaching at The Top 20 MBA Programmes in The USApateldeaÎncă nu există evaluări
- Jacobs - 2e Prefácio PDFDocument33 paginiJacobs - 2e Prefácio PDFNum ToukaÎncă nu există evaluări
- SP1208Document71 paginiSP1208Ajay KumarÎncă nu există evaluări
- Bad BanksDocument18 paginiBad Banksdivyansh thakreÎncă nu există evaluări
- Cover Letter Inspection EngineerDocument1 paginăCover Letter Inspection EngineerTina MillerÎncă nu există evaluări
- Chapter 3 Excercise With SolutionDocument18 paginiChapter 3 Excercise With SolutionSyed Ali100% (1)
- AQ - Word Document TemplateDocument4 paginiAQ - Word Document TemplateAdeel QurashiÎncă nu există evaluări
- FastfoodDocument98 paginiFastfoodkabibhandariÎncă nu există evaluări
- BS 7079-F8-3 Surface Preparation.Document19 paginiBS 7079-F8-3 Surface Preparation.Rajan SteeveÎncă nu există evaluări
- Barcelona Has Become One of The First Tourist Destination of SpainDocument6 paginiBarcelona Has Become One of The First Tourist Destination of SpainMarjorie Batrinescu MoteauÎncă nu există evaluări
- SSPC Pa2 02Document7 paginiSSPC Pa2 02Cristian Espinoza100% (1)
- Acleda Bank Case StudyDocument15 paginiAcleda Bank Case StudySophie LamÎncă nu există evaluări
- DID GUIDELINE - Gas Pipeline CrossingDocument11 paginiDID GUIDELINE - Gas Pipeline CrossingDeraman AbdullahÎncă nu există evaluări
- Basic Business Statistics: Statistical Applications in Quality and Productivity ManagementDocument67 paginiBasic Business Statistics: Statistical Applications in Quality and Productivity ManagementToufiq Khan MajlisÎncă nu există evaluări
- Case (2) Gravity PaymentsDocument15 paginiCase (2) Gravity PaymentsQuality AssuranceÎncă nu există evaluări
- Read The Following Case Study Carefully and Answer The Questions Given at The End: Case # 3. ElectroluxDocument3 paginiRead The Following Case Study Carefully and Answer The Questions Given at The End: Case # 3. ElectroluxDarkest DarkÎncă nu există evaluări
- Ace AutomotiveDocument9 paginiAce AutomotiveGlory0% (1)
- Group 8 Section A - Shoe Corporation of Illinois CaseDocument2 paginiGroup 8 Section A - Shoe Corporation of Illinois CaseSuchita SuryanarayananÎncă nu există evaluări
- Nigerian Bureau of Statistics, Furniture ReportDocument19 paginiNigerian Bureau of Statistics, Furniture ReportChike ChukudebeluÎncă nu există evaluări
- Cost and Management AccountingDocument23 paginiCost and Management Accountingsexi_dilip100% (1)
- Api-570 Authorized Piping Inspector (API102) : Programme OverviewDocument1 paginăApi-570 Authorized Piping Inspector (API102) : Programme OverviewSyamim AzmiÎncă nu există evaluări
- NCR - ATF Accredited Testing FacilityDocument5 paginiNCR - ATF Accredited Testing FacilityjesycubanÎncă nu există evaluări
- Unit 5 TQMDocument6 paginiUnit 5 TQMpddsivaÎncă nu există evaluări
- Supplier Manual TribarDocument17 paginiSupplier Manual TribarAvyan Kelan100% (1)
- P370 Sample Questions Midterm: TH TH TH STDocument5 paginiP370 Sample Questions Midterm: TH TH TH STSehoon OhÎncă nu există evaluări
- Levofloxacin - Wikipedia, The Free EncyclopediaDocument19 paginiLevofloxacin - Wikipedia, The Free EncyclopediaAnkan PalÎncă nu există evaluări
- Bankruptcy PredictionDocument33 paginiBankruptcy PredictionRagavi RzÎncă nu există evaluări
- Project Charter Template: Purpose of The DocumentDocument4 paginiProject Charter Template: Purpose of The DocumentBakhtawar RahmanÎncă nu există evaluări
- HBK - Fatigue and Durability ExplainedDocument111 paginiHBK - Fatigue and Durability ExplainedsengozkÎncă nu există evaluări
- Provision of Non Audit Services To Audit Clients - Impact On Auditors' Independence and Quality of WorkDocument42 paginiProvision of Non Audit Services To Audit Clients - Impact On Auditors' Independence and Quality of Workpapaboamah100% (1)
- CWB Encoding TutorialDocument13 paginiCWB Encoding TutorialTonka3cÎncă nu există evaluări
- Developments in International Safety Glass Test Method StandardsDocument30 paginiDevelopments in International Safety Glass Test Method StandardsKedar A. MalusareÎncă nu există evaluări
- Revised Marketing PlanDocument33 paginiRevised Marketing PlanMohamed SalahÎncă nu există evaluări
- Decision Making Robbins Coulter Ch06Document7 paginiDecision Making Robbins Coulter Ch06SHAKEEL IQBALÎncă nu există evaluări
- Cracks in Nuclear Reactor Pressure Vessels of Doel3/Tihange2 Power PlantsDocument9 paginiCracks in Nuclear Reactor Pressure Vessels of Doel3/Tihange2 Power PlantsWBÎncă nu există evaluări
- Iso 9000Document57 paginiIso 9000vinniieeÎncă nu există evaluări
- RFID in Healthcare A Six Sigma DMAIC and Simulation Case StudyDocument31 paginiRFID in Healthcare A Six Sigma DMAIC and Simulation Case StudydrustagiÎncă nu există evaluări
- Full Ring TestDocument5 paginiFull Ring Testchellahari292250% (2)
- Financial StatementDocument36 paginiFinancial StatementKopal GargÎncă nu există evaluări
- Riqas ExplainedDocument36 paginiRiqas ExplainedJulianÎncă nu există evaluări
- Remaining Life Evaluation of Coke DrumsDocument15 paginiRemaining Life Evaluation of Coke DrumsRohit KaleÎncă nu există evaluări
- Assignment of Corporate FinanceDocument3 paginiAssignment of Corporate FinanceSakshi PanwarÎncă nu există evaluări
- Articulo de RbiDocument23 paginiArticulo de RbiALberto AriasÎncă nu există evaluări
- Naive Bayes..and OtherDocument50 paginiNaive Bayes..and OtherManushiÎncă nu există evaluări
- Resources Download Materialize: CDN PathsDocument3 paginiResources Download Materialize: CDN PathskolliganeshÎncă nu există evaluări
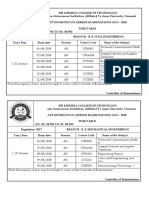
- IV Sem Time Table (Reg 16)Document4 paginiIV Sem Time Table (Reg 16)16TUCS228 SRIDHAR T.SÎncă nu există evaluări
- Unit - 4: Building IOT With Galileo/ArdunioDocument41 paginiUnit - 4: Building IOT With Galileo/Ardunio16TUCS228 SRIDHAR T.SÎncă nu există evaluări
- Anna University Sports Board Details of PlayersDocument1 paginăAnna University Sports Board Details of Players16TUCS228 SRIDHAR T.SÎncă nu există evaluări
- JuijDocument4 paginiJuij16TUCS228 SRIDHAR T.SÎncă nu există evaluări
- CIA I Answer KeyDocument8 paginiCIA I Answer Key16TUCS228 SRIDHAR T.SÎncă nu există evaluări
- FDocument3 paginiFCiobanu StefanÎncă nu există evaluări
- Maharaja Engineering College, Coimbatore - 2001: Degree Branch Institute YearDocument4 paginiMaharaja Engineering College, Coimbatore - 2001: Degree Branch Institute Year16TUCS228 SRIDHAR T.SÎncă nu există evaluări
- Most Misunderstood Basketball RulesDocument5 paginiMost Misunderstood Basketball RulesAnonymous wBkDTcFsÎncă nu există evaluări
- CIA I Answer KeyDocument8 paginiCIA I Answer Key16TUCS228 SRIDHAR T.SÎncă nu există evaluări
- Unix Basics For TestersDocument8 paginiUnix Basics For Testersrajesh_shriÎncă nu există evaluări
- PACKAGE 1 (RS.125+ 18% GST) - 207 Channels: Hindi News TamilDocument7 paginiPACKAGE 1 (RS.125+ 18% GST) - 207 Channels: Hindi News TamilRAMACHANDIRANÎncă nu există evaluări
- Cooooommmmuutt AssignmentDocument3 paginiCooooommmmuutt Assignment16TUCS228 SRIDHAR T.SÎncă nu există evaluări
- Cooooommmmuutt AssignmentDocument3 paginiCooooommmmuutt Assignment16TUCS228 SRIDHAR T.SÎncă nu există evaluări
- PACKAGE 1 (RS.125+ 18% GST) - 207 Channels: Hindi News TamilDocument7 paginiPACKAGE 1 (RS.125+ 18% GST) - 207 Channels: Hindi News TamilRAMACHANDIRANÎncă nu există evaluări
- Quantitative Aptitude PDFDocument5 paginiQuantitative Aptitude PDFrouf86inÎncă nu există evaluări
- Proforma For Ug/Pg Autonomous Practical Examinations - Nov/Dec 2019Document2 paginiProforma For Ug/Pg Autonomous Practical Examinations - Nov/Dec 201916TUCS228 SRIDHAR T.SÎncă nu există evaluări
- Proforma For Ug/Pg Autonomous Practical Examinations - Nov/Dec 2019Document2 paginiProforma For Ug/Pg Autonomous Practical Examinations - Nov/Dec 201916TUCS228 SRIDHAR T.SÎncă nu există evaluări
- PACKAGE 1 (RS.125+ 18% GST) - 207 Channels: Hindi News TamilDocument7 paginiPACKAGE 1 (RS.125+ 18% GST) - 207 Channels: Hindi News TamilRAMACHANDIRANÎncă nu există evaluări
- Unix Basics For TestersDocument8 paginiUnix Basics For Testersrajesh_shriÎncă nu există evaluări
- CIA I Answer KeyDocument8 paginiCIA I Answer Key16TUCS228 SRIDHAR T.SÎncă nu există evaluări
- Quantitative Aptitude PDFDocument5 paginiQuantitative Aptitude PDFrouf86inÎncă nu există evaluări
- JuijDocument4 paginiJuij16TUCS228 SRIDHAR T.SÎncă nu există evaluări
- 16Cs318 Data Analytics: Ecosystem For BigdataDocument36 pagini16Cs318 Data Analytics: Ecosystem For Bigdata16TUCS228 SRIDHAR T.SÎncă nu există evaluări
- CIA I Answer KeyDocument8 paginiCIA I Answer Key16TUCS228 SRIDHAR T.SÎncă nu există evaluări
- Array QuestionsDocument5 paginiArray Questions16TUCS228 SRIDHAR T.SÎncă nu există evaluări
- Johari WindowDocument7 paginiJohari WindowSarthak Priyank VermaÎncă nu există evaluări
- Chemical Classification of HormonesDocument65 paginiChemical Classification of HormonesetÎncă nu există evaluări
- 3.2.1 The Role of Market Research and Methods UsedDocument42 pagini3.2.1 The Role of Market Research and Methods Usedsana jaleelÎncă nu există evaluări
- A Sample Script For Public SpeakingDocument2 paginiA Sample Script For Public Speakingalmasodi100% (2)
- 120 Câu Tìm Từ Đồng Nghĩa-Trái Nghĩa-Dap AnDocument9 pagini120 Câu Tìm Từ Đồng Nghĩa-Trái Nghĩa-Dap AnAlex TranÎncă nu există evaluări
- Hot Rolled Coils Plates & SheetsDocument40 paginiHot Rolled Coils Plates & Sheetssreekanth6959646Încă nu există evaluări
- Amsterdam Pipe Museum - Snuff WorldwideDocument1 paginăAmsterdam Pipe Museum - Snuff Worldwideevon1Încă nu există evaluări
- Space Saving, Tight AccessibilityDocument4 paginiSpace Saving, Tight AccessibilityTran HuyÎncă nu există evaluări
- Elerick Ron Cynthia 1983 SouthAfricaDocument4 paginiElerick Ron Cynthia 1983 SouthAfricathe missions networkÎncă nu există evaluări
- Andromeda: Druid 3 Warborn06Document5 paginiAndromeda: Druid 3 Warborn06AlanÎncă nu există evaluări
- Catalogo HydronixDocument68 paginiCatalogo HydronixNANCHO77Încă nu există evaluări
- NSTP SlabDocument2 paginiNSTP SlabCherine Fates MangulabnanÎncă nu există evaluări
- RELATION AND FUNCTION - ModuleDocument5 paginiRELATION AND FUNCTION - ModuleAna Marie ValenzuelaÎncă nu există evaluări
- Starbucks Progressive Web App: Case StudyDocument2 paginiStarbucks Progressive Web App: Case StudyYesid SuárezÎncă nu există evaluări
- DISTRICT CENSUS HANDBOOK North GoaDocument190 paginiDISTRICT CENSUS HANDBOOK North Goants1020Încă nu există evaluări
- Haymne Uka@yahoo - Co.ukDocument1 paginăHaymne Uka@yahoo - Co.ukhaymne ukaÎncă nu există evaluări
- Little: PrinceDocument18 paginiLittle: PrinceNara Serrano94% (18)
- Adhesive Film & TapeDocument6 paginiAdhesive Film & TapeJothi Vel MuruganÎncă nu există evaluări
- Intergard 475HS - Part B - EVA046 - GBR - ENG PDFDocument10 paginiIntergard 475HS - Part B - EVA046 - GBR - ENG PDFMohamed NouzerÎncă nu există evaluări
- Virtual Feeder Segregation Using IIoT and Cloud TechnologiesDocument7 paginiVirtual Feeder Segregation Using IIoT and Cloud Technologiespjgandhi100% (2)
- Name: Mercado, Kath DATE: 01/15 Score: Activity Answer The Following Items On A Separate Sheet of Paper. Show Your Computations. (4 Items X 5 Points)Document2 paginiName: Mercado, Kath DATE: 01/15 Score: Activity Answer The Following Items On A Separate Sheet of Paper. Show Your Computations. (4 Items X 5 Points)Kathleen MercadoÎncă nu există evaluări
- Eco EssayDocument3 paginiEco EssaymanthanÎncă nu există evaluări
- Tylenol CrisisDocument2 paginiTylenol CrisisNida SweetÎncă nu există evaluări
- Differential Calculus ExamDocument6 paginiDifferential Calculus ExamCaro Kan LopezÎncă nu există evaluări
- 5070 s17 QP 22 PDFDocument20 pagini5070 s17 QP 22 PDFMustafa WaqarÎncă nu există evaluări
- 2018 H2 JC1 MSM Differential Equations (Solutions)Document31 pagini2018 H2 JC1 MSM Differential Equations (Solutions)VincentÎncă nu există evaluări
- Chemical Safety ChecklistDocument3 paginiChemical Safety ChecklistPillai Sreejith100% (10)
- EstoqueDocument56 paginiEstoqueGustavo OliveiraÎncă nu există evaluări
- TV Antenna Tower CollapseDocument4 paginiTV Antenna Tower CollapseImdaad ChuubbÎncă nu există evaluări
- Matokeo CBDocument4 paginiMatokeo CBHubert MubofuÎncă nu există evaluări