S-ar putea să vă placă și
- Tables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesDe la EverandTables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesÎncă nu există evaluări
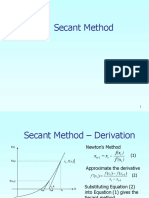
- Secant MethodDocument24 paginiSecant MethodMay May MagluyanÎncă nu există evaluări
- Secant Method: Major: All Engineering Majors Authors: Autar Kaw, Jai PaulDocument24 paginiSecant Method: Major: All Engineering Majors Authors: Autar Kaw, Jai PaulShivam PatilÎncă nu există evaluări
- Secant Method: Civil Engineering Majors Authors: Autar Kaw, Jai PaulDocument24 paginiSecant Method: Civil Engineering Majors Authors: Autar Kaw, Jai PaulJoven MadeloÎncă nu există evaluări
- Secant MethodDocument22 paginiSecant Methodjeffrey marapiaÎncă nu există evaluări
- Secant MethodDocument24 paginiSecant Methodp4omartinezÎncă nu există evaluări
- 4 SecantDocument22 pagini4 SecantTerrell LasamÎncă nu există evaluări
- Newton-Raphson Method: Simulasi NumerikDocument9 paginiNewton-Raphson Method: Simulasi NumerikAkbarNugratamaÎncă nu există evaluări
- Numerical AnalysisDocument21 paginiNumerical AnalysisMeiva Marthaulina LestariÎncă nu există evaluări
- Secant Method2Document21 paginiSecant Method2Willy AdrianÎncă nu există evaluări
- Secant MethodDocument24 paginiSecant Methodsoran najebÎncă nu există evaluări
- Approximation Theory PDFDocument24 paginiApproximation Theory PDFvigchaitanya4224Încă nu există evaluări
- Solution of Algebric Trancendental EquationDocument6 paginiSolution of Algebric Trancendental EquationEngineer JOÎncă nu există evaluări
- The Newton Raphson Method - 2017Document61 paginiThe Newton Raphson Method - 2017NajwaAinayaZawaidÎncă nu există evaluări
- NewtonDocument48 paginiNewtonArsene MawejaÎncă nu există evaluări
- Newton-Raphson MethodDocument32 paginiNewton-Raphson MethodnafisbadranÎncă nu există evaluări
- ID-20193007011 Presentation of Secant MethodDocument18 paginiID-20193007011 Presentation of Secant Methodabid raihanÎncă nu există evaluări
- UntitledDocument2 paginiUntitledritziscoolÎncă nu există evaluări
- LAB 2 Newton-Raphson MethodDocument3 paginiLAB 2 Newton-Raphson MethodJules Nikko Dela Cruz100% (1)
- Calculus 1 Topic 4Document9 paginiCalculus 1 Topic 4muradÎncă nu există evaluări
- Secant MethodDocument6 paginiSecant Methodcomunidad enkollÎncă nu există evaluări
- NM Lect2Document55 paginiNM Lect2خيري سمير كمالÎncă nu există evaluări
- Midterm MAT1025 Calculus I 2010gDocument10 paginiMidterm MAT1025 Calculus I 2010gZuhalÎncă nu există evaluări
- GradinetDocument51 paginiGradinetnabin PaudelÎncă nu există evaluări
- Surge and Logistic Functions InvestigationDocument19 paginiSurge and Logistic Functions InvestigationYaxuan Zhu50% (2)
- Newton-Raphson Method: Major: All Engineering Majors Authors: Autar Kaw, Jai PaulDocument32 paginiNewton-Raphson Method: Major: All Engineering Majors Authors: Autar Kaw, Jai PaulSonal GuptaÎncă nu există evaluări
- Maths IIT-JEE Best Approach' (MC SIR) : MonotonocityDocument11 paginiMaths IIT-JEE Best Approach' (MC SIR) : MonotonocityMohit KumarÎncă nu există evaluări
- CalTA-derivative (Drawn)Document4 paginiCalTA-derivative (Drawn)HowardÎncă nu există evaluări
- Maths Chap 4 Continuity of Functions NotesDocument10 paginiMaths Chap 4 Continuity of Functions NotesankushÎncă nu există evaluări
- Iran Olympiad 2003Document3 paginiIran Olympiad 2003KronÎncă nu există evaluări
- CG Ex6Document53 paginiCG Ex6Yasir ButtÎncă nu există evaluări
- Math 130 Course ReviewDocument4 paginiMath 130 Course ReviewJasonÎncă nu există evaluări
- Tabla y Propiedades de Las DerivadasDocument2 paginiTabla y Propiedades de Las DerivadasfelixespoÎncă nu există evaluări
- 3 Phy111Document11 pagini3 Phy111PARVATHY ANILÎncă nu există evaluări
- Math1520 HW2Document8 paginiMath1520 HW2trollergeistÎncă nu există evaluări
- Calculus I Formulas-Chapter-3-Dr. Wadii Hajji: 1 Steps To Graph A FunctionDocument1 paginăCalculus I Formulas-Chapter-3-Dr. Wadii Hajji: 1 Steps To Graph A FunctionInesÎncă nu există evaluări
- Numerical Analysis 4 Class Environmental Department College of Engineering 2016-2017Document46 paginiNumerical Analysis 4 Class Environmental Department College of Engineering 2016-2017AhmedÎncă nu există evaluări
- Differentiation TargetDocument113 paginiDifferentiation Targetipsita londheÎncă nu există evaluări
- Bab 5 - Vector SpacesDocument25 paginiBab 5 - Vector SpacesMonalisa Lestari SinabutarÎncă nu există evaluări
- Convex Functions and OptimizationDocument20 paginiConvex Functions and OptimizationhoalongkiemÎncă nu există evaluări
- Operations Research Letters: Claudia D'Ambrosio, Andrea Lodi, Silvano MartelloDocument8 paginiOperations Research Letters: Claudia D'Ambrosio, Andrea Lodi, Silvano MartelloJack HamiltonÎncă nu există evaluări
- Fourier Series TutorialDocument80 paginiFourier Series TutorialJose VillegasÎncă nu există evaluări
- Sistem Persamaan Non Linier (Metode Secant) - 2Document3 paginiSistem Persamaan Non Linier (Metode Secant) - 2Hilmi MubarokÎncă nu există evaluări
- Ch6 Open - Methods 10 10 2010Document47 paginiCh6 Open - Methods 10 10 2010No RaimaÎncă nu există evaluări
- Class 12 Revision Notes Continuity and DifferentiabilityDocument22 paginiClass 12 Revision Notes Continuity and DifferentiabilityAmaan ShaikhÎncă nu există evaluări
- Convex Functions: See P. 10 of The Handout On Preliminary MaterialDocument20 paginiConvex Functions: See P. 10 of The Handout On Preliminary MaterialClaribel Paola Serna CelinÎncă nu există evaluări
- Lecture NotesDocument3 paginiLecture NotesJustin Paul TumaliuanÎncă nu există evaluări
- Exam Diferential Calculus 4Document2 paginiExam Diferential Calculus 4lllloÎncă nu există evaluări
- Algebra1section3 3Document11 paginiAlgebra1section3 3api-358505269Încă nu există evaluări
- Lect 4 PDFDocument28 paginiLect 4 PDFTeferiÎncă nu există evaluări
- You Do Not Need To Explain How You Found The Example, But You Have To Verify That Your Example Satisfies The Conditions.Document1 paginăYou Do Not Need To Explain How You Found The Example, But You Have To Verify That Your Example Satisfies The Conditions.Aysu DemirtaşÎncă nu există evaluări
- ANUM 2012 Bracketing MethodsDocument31 paginiANUM 2012 Bracketing MethodsKukuh KurniadiÎncă nu există evaluări
- Lec5 - BM RFM SFPIDocument28 paginiLec5 - BM RFM SFPIWreiniele CosmeÎncă nu există evaluări
- 2015-GS-Session 2-Official Exam-Mathmatics-En-Functions-FunctionsDocument2 pagini2015-GS-Session 2-Official Exam-Mathmatics-En-Functions-FunctionsIce TechÎncă nu există evaluări
- Applied Numerical Methods MEE3005Document21 paginiApplied Numerical Methods MEE3005DeepanshuÎncă nu există evaluări
- Secant Method (Sauer)Document6 paginiSecant Method (Sauer)Ismael LinsÎncă nu există evaluări
- Cohomology Operations (AM-50), Volume 50: Lectures by N. E. Steenrod. (AM-50)De la EverandCohomology Operations (AM-50), Volume 50: Lectures by N. E. Steenrod. (AM-50)Încă nu există evaluări
- Nonlinear Functional Analysis and Applications: Proceedings of an Advanced Seminar Conducted by the Mathematics Research Center, the University of Wisconsin, Madison, October 12-14, 1970De la EverandNonlinear Functional Analysis and Applications: Proceedings of an Advanced Seminar Conducted by the Mathematics Research Center, the University of Wisconsin, Madison, October 12-14, 1970Louis B. RallÎncă nu există evaluări
- Functional Operators (AM-22), Volume 2: The Geometry of Orthogonal Spaces. (AM-22)De la EverandFunctional Operators (AM-22), Volume 2: The Geometry of Orthogonal Spaces. (AM-22)Încă nu există evaluări
- Fluid Statistics and Its ApplicationsDocument5 paginiFluid Statistics and Its Applicationskruthi_dhoriaÎncă nu există evaluări
- Modeling and Simulation of A Distillation Column Using ASPEN PLUS PDFDocument9 paginiModeling and Simulation of A Distillation Column Using ASPEN PLUS PDFkruthi_dhoriaÎncă nu există evaluări
- Flow of Incompressible Fluids in Conduits and ThinDocument81 paginiFlow of Incompressible Fluids in Conduits and Thinkruthi_dhoriaÎncă nu există evaluări
- Application of Fluid StatisticsDocument71 paginiApplication of Fluid Statisticskruthi_dhoria100% (1)
- Microbes Producing L-AsparaginaseDocument1 paginăMicrobes Producing L-Asparaginasekruthi_dhoriaÎncă nu există evaluări
- Artificial Neural NetworkDocument13 paginiArtificial Neural NetworkNitish SharmaÎncă nu există evaluări
- 4 Educ 115 Detailed Lesson PlanDocument29 pagini4 Educ 115 Detailed Lesson PlanEllen CatleÎncă nu există evaluări
- Chapter 7Document31 paginiChapter 7Fairooz TorosheÎncă nu există evaluări
- Experiment (7) Generating Waves Using Convolution: Conv InstructionDocument4 paginiExperiment (7) Generating Waves Using Convolution: Conv InstructionNaoo 0099Încă nu există evaluări
- Lecture 17Document2 paginiLecture 17Tấn Long LêÎncă nu există evaluări
- Machine Learning Primer 108796Document15 paginiMachine Learning Primer 108796Vinay Nagnath JokareÎncă nu există evaluări
- Lecture 10 - Supervised Learning in Neural Networks - (Part 3)Document2 paginiLecture 10 - Supervised Learning in Neural Networks - (Part 3)Ammar AlkindyÎncă nu există evaluări
- Image ReognitionDocument18 paginiImage Reognitiondheeptha rameshÎncă nu există evaluări
- Math - List Manipulation in Mathematica Pertaining To Lagrange Interpolation Polynomials in Mathematica - Stack OverflowDocument3 paginiMath - List Manipulation in Mathematica Pertaining To Lagrange Interpolation Polynomials in Mathematica - Stack OverflowAdebanjo Adeshina SamuelÎncă nu există evaluări
- Solution Manual For An Introduction To Optimization 4th Edition Edwin K P Chong Stanislaw H ZakDocument7 paginiSolution Manual For An Introduction To Optimization 4th Edition Edwin K P Chong Stanislaw H ZakDarla Lambe100% (30)
- Calyley Hamilton Theoram. Eigen NotesDocument8 paginiCalyley Hamilton Theoram. Eigen NotesPriyanka PÎncă nu există evaluări
- Phython Practical Notebook1Document14 paginiPhython Practical Notebook1babu royÎncă nu există evaluări
- Solution Methods For Eigenvalue Problems in Structural MechanicsDocument14 paginiSolution Methods For Eigenvalue Problems in Structural MechanicsMelita ĆališÎncă nu există evaluări
- Load Flow by Newton Raphson MethodDocument18 paginiLoad Flow by Newton Raphson Methoddiwakar92Încă nu există evaluări
- Rajalakshmi Engineering College, Chennai Department of Aeronautical Engineering AE 2402 - Computational Fluid Dynamics: Question BankDocument2 paginiRajalakshmi Engineering College, Chennai Department of Aeronautical Engineering AE 2402 - Computational Fluid Dynamics: Question BankSãröj ShâhÎncă nu există evaluări
- (1d) Linear Programming - Simplex MethodDocument32 pagini(1d) Linear Programming - Simplex MethodDennis NavaÎncă nu există evaluări
- Convex Constrained Optimization For The Seismic Reflection Tomography ProblemDocument9 paginiConvex Constrained Optimization For The Seismic Reflection Tomography ProblemIfan AzizÎncă nu există evaluări
- Numerical Methods For Engineers 7Document13 paginiNumerical Methods For Engineers 7najÎncă nu există evaluări
- Linear Algebra and Optimization For Machine LearningDocument18 paginiLinear Algebra and Optimization For Machine LearningSohail ZiaÎncă nu există evaluări
- Artificial Intelligence: An Introduction: Fabio Mart Inez, PH.DDocument20 paginiArtificial Intelligence: An Introduction: Fabio Mart Inez, PH.Ddavid2122910Încă nu există evaluări
- CS 203 Data Structure & Algorithms: Performance AnalysisDocument21 paginiCS 203 Data Structure & Algorithms: Performance AnalysisSreejaÎncă nu există evaluări
- Dynamic ProgrammingDocument2 paginiDynamic ProgrammingadesloopÎncă nu există evaluări
- Transportation Problem (TP) and Assignment Problem (AP) : (Special Cases of Linear Programming)Document37 paginiTransportation Problem (TP) and Assignment Problem (AP) : (Special Cases of Linear Programming)Ghadeer ShÎncă nu există evaluări
- Hyperparameter Tuning For Deep Learning in Natural Language ProcessingDocument7 paginiHyperparameter Tuning For Deep Learning in Natural Language ProcessingWardhana Halim KusumaÎncă nu există evaluări
- TutorialSheet 01Document2 paginiTutorialSheet 01fuckingÎncă nu există evaluări
- Manual Neuronica CalcDocument5 paginiManual Neuronica CalcAntonio ThyrsoÎncă nu există evaluări
- PRELIMDocument22 paginiPRELIMMarshall james G. RamirezÎncă nu există evaluări
- Problems For Chapter 2Document5 paginiProblems For Chapter 2Aldhi PrastyaÎncă nu există evaluări
- Lesson Plan in MathematicsDocument3 paginiLesson Plan in Mathematicsyasmine baldoÎncă nu există evaluări
- Artificial Intelligence in GamesDocument13 paginiArtificial Intelligence in GamesBenas LieÎncă nu există evaluări