S-ar putea să vă placă și
- EEG Brain Signal Classification for Epileptic Seizure Disorder DetectionDe la EverandEEG Brain Signal Classification for Epileptic Seizure Disorder DetectionÎncă nu există evaluări
- Genetic Algorithms in Artificial Neural Network (Autosaved)Document19 paginiGenetic Algorithms in Artificial Neural Network (Autosaved)andronache_costinÎncă nu există evaluări
- Neuroevolution: Fundamentals and Applications for Surpassing Human Intelligence with NeuroevolutionDe la EverandNeuroevolution: Fundamentals and Applications for Surpassing Human Intelligence with NeuroevolutionÎncă nu există evaluări
- Genetic Algorithm Based Feature Selection For Medical Diagnosing Using Artificial Neural NetworkDocument54 paginiGenetic Algorithm Based Feature Selection For Medical Diagnosing Using Artificial Neural NetworkpriyankaÎncă nu există evaluări
- DuongToGiangSon 517H0162 HW2 Nov-26Document17 paginiDuongToGiangSon 517H0162 HW2 Nov-26Son TranÎncă nu există evaluări
- An Efficient GA-based Clustering Technique: Hwei-Jen Lin, Fu-Wen Yang and Yang-Ta KaoDocument10 paginiAn Efficient GA-based Clustering Technique: Hwei-Jen Lin, Fu-Wen Yang and Yang-Ta Kaotamal3110Încă nu există evaluări
- EEG Signal Classification Using K-Means and Fuzzy C Means Clustering MethodsDocument5 paginiEEG Signal Classification Using K-Means and Fuzzy C Means Clustering MethodsIJSTEÎncă nu există evaluări
- Survey On GA and RulesDocument15 paginiSurvey On GA and RulesAnonymous TxPyX8cÎncă nu există evaluări
- Microarray FullDocument56 paginiMicroarray FullSyed MasudÎncă nu există evaluări
- Genetic Algorithms and The Search For Optimal Database Index SelectionDocument7 paginiGenetic Algorithms and The Search For Optimal Database Index SelectionAlHasanÎncă nu există evaluări
- Computational Methods For Genomic AnalysisDocument12 paginiComputational Methods For Genomic Analysissubhasree majumderÎncă nu există evaluări
- Name: Survey1 Title: Genetic Algorithm Based On Evolution Strategy and The Alication in Data Mining 2.issueDocument24 paginiName: Survey1 Title: Genetic Algorithm Based On Evolution Strategy and The Alication in Data Mining 2.issueindirasivakumarÎncă nu există evaluări
- Neural NetworksDocument4 paginiNeural Networksapi-26355935100% (1)
- Multi-Layer PerceptronsDocument8 paginiMulti-Layer PerceptronswarrengauciÎncă nu există evaluări
- An Approach of Hybrid Clustering Technique For Maximizing Similarity of Gene ExpressionDocument14 paginiAn Approach of Hybrid Clustering Technique For Maximizing Similarity of Gene Expressionvmurali.infoÎncă nu există evaluări
- Discovering Knowledge in Data: Lecture Review ofDocument20 paginiDiscovering Knowledge in Data: Lecture Review ofmofoelÎncă nu există evaluări
- Bio in For Matic SpcaDocument13 paginiBio in For Matic SpcaMonica ClementsÎncă nu există evaluări
- Comparison of Different Clustering Algorithms Using WEKA ToolDocument3 paginiComparison of Different Clustering Algorithms Using WEKA ToolIJARTESÎncă nu există evaluări
- Literature Survey On Genetic Algorithm Approach For Fuzzy Rule-Based SystemDocument4 paginiLiterature Survey On Genetic Algorithm Approach For Fuzzy Rule-Based SystemEditorijer IjerÎncă nu există evaluări
- Microsoft Word - JCD FinalDocument8 paginiMicrosoft Word - JCD Finaljkl316Încă nu există evaluări
- Trancriptome and Proteome AnalysisDocument68 paginiTrancriptome and Proteome AnalysisNeeru RedhuÎncă nu există evaluări
- Soft Computing 4Document23 paginiSoft Computing 4shivangiimishraa1819Încă nu există evaluări
- Clustering and Classification: - TaskDocument16 paginiClustering and Classification: - Taskasra18786Încă nu există evaluări
- An Introduction To Proteomics: The Protein Complement of The GenomeDocument40 paginiAn Introduction To Proteomics: The Protein Complement of The GenomeJohn Louie BarquerosÎncă nu există evaluări
- Module 5Document29 paginiModule 5ShrutiÎncă nu există evaluări
- GA ClusteringDocument6 paginiGA ClusteringJosueÎncă nu există evaluări
- Dietmar Heinke and Fred H. Hamker - Comparing Neural Networks: A Benchmark On Growing Neural Gas, Growing Cell Structures, and Fuzzy ARTMAPDocument13 paginiDietmar Heinke and Fred H. Hamker - Comparing Neural Networks: A Benchmark On Growing Neural Gas, Growing Cell Structures, and Fuzzy ARTMAPTuhmaÎncă nu există evaluări
- EEG Signal Classification Using K MeansDocument5 paginiEEG Signal Classification Using K MeansHarsh GandhiÎncă nu există evaluări
- Cheng Et Al. (2007)Document4 paginiCheng Et Al. (2007)apostolos katsafadosÎncă nu există evaluări
- Computational Biology and Biomedical Data AnalysisDocument34 paginiComputational Biology and Biomedical Data AnalysissanahujalidiaÎncă nu există evaluări
- Proclust:: Improved Clustering of Protein Sequences With An Extended Graph-Based ApproachDocument58 paginiProclust:: Improved Clustering of Protein Sequences With An Extended Graph-Based ApproachJJ EBÎncă nu există evaluări
- Resolving Gene Expression Data Using Multiobjective Optimization ApproachDocument7 paginiResolving Gene Expression Data Using Multiobjective Optimization ApproachIJIRSTÎncă nu există evaluări
- Classification of Iris Data Set: Mentor: Assist. Prof. Primož Potočnik Student: Vitaly BorovinskiyDocument21 paginiClassification of Iris Data Set: Mentor: Assist. Prof. Primož Potočnik Student: Vitaly BorovinskiyrajendraÎncă nu există evaluări
- A Versatile Genetic Algorithm For Network PlanningDocument7 paginiA Versatile Genetic Algorithm For Network PlanningquocnknetÎncă nu există evaluări
- 10 GaDocument20 pagini10 GaNoor WaleedÎncă nu există evaluări
- Chapter - 1: 1.1 OverviewDocument50 paginiChapter - 1: 1.1 Overviewkarthik0484Încă nu există evaluări
- (IJCT-V2I5P9) Authors :honorine Mutazinda A, Mary Sowjanya, O.MrudulaDocument9 pagini(IJCT-V2I5P9) Authors :honorine Mutazinda A, Mary Sowjanya, O.MrudulaIjctJournalsÎncă nu există evaluări
- End Sem PresentationDocument4 paginiEnd Sem PresentationShady dtÎncă nu există evaluări
- Classification of Iris Data Set PDFDocument21 paginiClassification of Iris Data Set PDFSofiene GuedriÎncă nu există evaluări
- Efficient Distributed Genetic Algorithm For Rule ExtractionDocument6 paginiEfficient Distributed Genetic Algorithm For Rule ExtractionmiguelangelwwwÎncă nu există evaluări
- Synthesis of Thinned Linear Antenna Arrays With Fixed Sidelobe Level Using Real-Coded Genetic Algorithm G. K. MahantiDocument10 paginiSynthesis of Thinned Linear Antenna Arrays With Fixed Sidelobe Level Using Real-Coded Genetic Algorithm G. K. MahantiNaren PathakÎncă nu există evaluări
- Classification of Iris Data SetDocument16 paginiClassification of Iris Data SetSofiene GuedriÎncă nu există evaluări
- Prepared By: Mayank Kothari (10BIT036) : Face Recognition Using Artificial Neural NetworkDocument36 paginiPrepared By: Mayank Kothari (10BIT036) : Face Recognition Using Artificial Neural Networkmayank036Încă nu există evaluări
- 1 s2.0 S0031320311005188 MainDocument15 pagini1 s2.0 S0031320311005188 MainRohhan RabariÎncă nu există evaluări
- Imbalanced K-Means: An Algorithm To Cluster Imbalanced-Distributed DataDocument9 paginiImbalanced K-Means: An Algorithm To Cluster Imbalanced-Distributed DataerpublicationÎncă nu există evaluări
- 1 - Introduction of AIDocument92 pagini1 - Introduction of AINaveena NagineniÎncă nu există evaluări
- An Improvement in K Means Clustering Algorithm IJERTV2IS1385Document6 paginiAn Improvement in K Means Clustering Algorithm IJERTV2IS1385David MorenoÎncă nu există evaluări
- Abstract - Genetic Algorithms (GA) Have Emerged As Practical, Robust Optimization and SearchDocument10 paginiAbstract - Genetic Algorithms (GA) Have Emerged As Practical, Robust Optimization and SearchAnonymous TxPyX8cÎncă nu există evaluări
- A Parallel Study On Clustering Algorithms in Data MiningDocument7 paginiA Parallel Study On Clustering Algorithms in Data MiningAnu IshwaryaÎncă nu există evaluări
- Cancer Detection - Formal VersionDocument38 paginiCancer Detection - Formal VersionMEOW41Încă nu există evaluări
- QnA - Business AnalyticsDocument6 paginiQnA - Business AnalyticsRumani ChakrabortyÎncă nu există evaluări
- A Survey of Cryptanalytic Works Based On Genetic AlgorithmsDocument5 paginiA Survey of Cryptanalytic Works Based On Genetic AlgorithmsInternational Journal of Application or Innovation in Engineering & ManagementÎncă nu există evaluări
- Multilevel Techniques For The Clustering ProblemDocument15 paginiMultilevel Techniques For The Clustering ProblemCS & ITÎncă nu există evaluări
- Genetic Algorithm Approach For Placement Optimization of FBG Sensors For A Diagnostic SystemDocument6 paginiGenetic Algorithm Approach For Placement Optimization of FBG Sensors For A Diagnostic SystemInternational Organization of Scientific Research (IOSR)Încă nu există evaluări
- Hierarchical Clustering PDFDocument5 paginiHierarchical Clustering PDFLikitha ReddyÎncă nu există evaluări
- Paper-2 Clustering Algorithms in Data Mining A ReviewDocument7 paginiPaper-2 Clustering Algorithms in Data Mining A ReviewRachel WheelerÎncă nu există evaluări
- Dchip, MAS e RMADocument8 paginiDchip, MAS e RMAYuri Nagamine UrataÎncă nu există evaluări
- Bioinspired Algorithms and ApplicationsDocument42 paginiBioinspired Algorithms and ApplicationsAdvith A JÎncă nu există evaluări
- Neural Network Weight Selection Using Genetic AlgorithmsDocument17 paginiNeural Network Weight Selection Using Genetic AlgorithmsChevalier De BalibariÎncă nu există evaluări
- An Assimilated Approach For Statistical Genome Streak Assay Between Matriclinous DatasetsDocument6 paginiAn Assimilated Approach For Statistical Genome Streak Assay Between Matriclinous Datasetsvol1no2Încă nu există evaluări
- Project Submitted ToDocument7 paginiProject Submitted ToGlobal info - tech KumbakonamÎncă nu există evaluări
- 3Document27 pagini3Global info - tech KumbakonamÎncă nu există evaluări
- Chapter 1Document101 paginiChapter 1Global info - tech KumbakonamÎncă nu există evaluări
- CHP 1Document97 paginiCHP 1Global info - tech KumbakonamÎncă nu există evaluări
- 21 FinalDocument1 pagină21 FinalGlobal info - tech KumbakonamÎncă nu există evaluări
- Project Submitted ToDocument7 paginiProject Submitted ToGlobal info - tech KumbakonamÎncă nu există evaluări
- Iot Based Real Time Traffic Monitoring System Using M/G/1 QueuingDocument5 paginiIot Based Real Time Traffic Monitoring System Using M/G/1 QueuingGlobal info - tech KumbakonamÎncă nu există evaluări
- Kanimozhi ContentDocument1 paginăKanimozhi ContentGlobal info - tech KumbakonamÎncă nu există evaluări
- Mphil Full Project - Kum PDFDocument84 paginiMphil Full Project - Kum PDFGlobal info - tech KumbakonamÎncă nu există evaluări
- Choose The Correct AnswerDocument1 paginăChoose The Correct AnswerGlobal info - tech KumbakonamÎncă nu există evaluări
- VII Q&aDocument2 paginiVII Q&aGlobal info - tech KumbakonamÎncă nu există evaluări
- A Project Work On "Detection of Adulterants in Some Common Food-Stuff"Document24 paginiA Project Work On "Detection of Adulterants in Some Common Food-Stuff"atultiwari8Încă nu există evaluări
- PHYSICAL PROPERTIES OF SPRAY DEPOSITED BaDocument2 paginiPHYSICAL PROPERTIES OF SPRAY DEPOSITED BaGlobal info - tech KumbakonamÎncă nu există evaluări
- PROJECTDocument63 paginiPROJECTGlobal info - tech KumbakonamÎncă nu există evaluări
- 2copies FrontDocument4 pagini2copies FrontGlobal info - tech KumbakonamÎncă nu există evaluări
- TeDocument1 paginăTeGlobal info - tech KumbakonamÎncă nu există evaluări
- Kalai All2Document65 paginiKalai All2Global info - tech KumbakonamÎncă nu există evaluări
- Proposed System: Need For Conference Management System Project ComputerizationDocument14 paginiProposed System: Need For Conference Management System Project ComputerizationGlobal info - tech KumbakonamÎncă nu există evaluări
- JavaDocument1 paginăJavaGlobal info - tech KumbakonamÎncă nu există evaluări
- MINI3Document34 paginiMINI3Global info - tech KumbakonamÎncă nu există evaluări
- The M/G/1 Retrial Queue With Feedback and Starting Failures: B. Krishna Kumar, S. Pavai Madheswari, A. VijayakumarDocument19 paginiThe M/G/1 Retrial Queue With Feedback and Starting Failures: B. Krishna Kumar, S. Pavai Madheswari, A. VijayakumarGlobal info - tech KumbakonamÎncă nu există evaluări
- Untitled 2Document1 paginăUntitled 2Global info - tech KumbakonamÎncă nu există evaluări
- PHD Question and AnswerDocument9 paginiPHD Question and AnswerGlobal info - tech KumbakonamÎncă nu există evaluări
- Final ReportDocument32 paginiFinal ReportGlobal info - tech KumbakonamÎncă nu există evaluări
- 1 1.1 ComputationDocument72 pagini1 1.1 ComputationGanesh KumarÎncă nu există evaluări
- VHDL CodesDocument9 paginiVHDL CodesSaneesh KarayilÎncă nu există evaluări
- Linear CongruenceDocument10 paginiLinear CongruenceQueenie PalenciaÎncă nu există evaluări
- GplayDocument9 paginiGplayΣατανάς ΣατανάςÎncă nu există evaluări
- How To Establish Sample Sizes For Process Validation Using Statistical T...Document10 paginiHow To Establish Sample Sizes For Process Validation Using Statistical T...Anh Tran Thi VanÎncă nu există evaluări
- Basic Math - 2011 PDFDocument6 paginiBasic Math - 2011 PDFLuqman Abdirazaq TukeÎncă nu există evaluări
- 55 The Vector Equation of A PlaneDocument37 pagini55 The Vector Equation of A PlaneShammus SultanÎncă nu există evaluări
- Ok Assessmente of PV Modules Shunt Resistence PDFDocument9 paginiOk Assessmente of PV Modules Shunt Resistence PDFOscar ChilcaÎncă nu există evaluări
- MM 212 Materials Evaluation Techniques Fall Semester 2020, FMCE, GIKIDocument30 paginiMM 212 Materials Evaluation Techniques Fall Semester 2020, FMCE, GIKIElbert VonVerimÎncă nu există evaluări
- Selection Course For Term 1626 - 22aug2016Document21 paginiSelection Course For Term 1626 - 22aug2016yvonneÎncă nu există evaluări
- HRM Report - Human Resource PlanningDocument32 paginiHRM Report - Human Resource PlanningKeith Amor100% (1)
- Mathematics HL Paper 3 TZ2 Sets Relations and GroupsDocument3 paginiMathematics HL Paper 3 TZ2 Sets Relations and GroupsAastha NagarÎncă nu există evaluări
- Tut2 PDFDocument3 paginiTut2 PDFanshuljain226Încă nu există evaluări
- Estimation Bertinoro09 Cristiano Porciani 1Document42 paginiEstimation Bertinoro09 Cristiano Porciani 1shikha singhÎncă nu există evaluări
- Fundamentals in ALGEBRADocument8 paginiFundamentals in ALGEBRACarlo BiongÎncă nu există evaluări
- 8 - Ce6101 Modified Cam Clay-09082019Document56 pagini8 - Ce6101 Modified Cam Clay-09082019rihongkeeÎncă nu există evaluări
- The "Big Bang" Is Just Religion Disguised As ScienceDocument6 paginiThe "Big Bang" Is Just Religion Disguised As ScienceSean BarryÎncă nu există evaluări
- Ai ML MCQ CombinedDocument54 paginiAi ML MCQ CombinedAbhinav JoshiÎncă nu există evaluări
- ASEU TEACHERFILE WEB 3936427542519593610.ppt 1608221424Document9 paginiASEU TEACHERFILE WEB 3936427542519593610.ppt 1608221424Emiraslan MhrrovÎncă nu există evaluări
- Introduccion: Encuentre La Segunda Derivada de Las Funciones Dadas: 1Document3 paginiIntroduccion: Encuentre La Segunda Derivada de Las Funciones Dadas: 1Miguel BautistaÎncă nu există evaluări
- Theta Geometry TestDocument6 paginiTheta Geometry TestJun Arro Estrella JoestarÎncă nu există evaluări
- Splay TreeDocument7 paginiSplay TreePraveen YadavÎncă nu există evaluări
- SyllabusDocument3 paginiSyllabuspan tatÎncă nu există evaluări
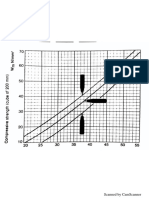
- Problem Set D: Attempt HistoryDocument10 paginiProblem Set D: Attempt HistoryHenryÎncă nu există evaluări
- DistanceMidpoint City Map ProjectDocument12 paginiDistanceMidpoint City Map ProjectGunazdeep SidhuÎncă nu există evaluări
- EC537 Microeconomic Theory For Research Students, Part II: Lecture 5Document50 paginiEC537 Microeconomic Theory For Research Students, Part II: Lecture 5Hitesh RathoreÎncă nu există evaluări
- Example of Perspective TransformationDocument2 paginiExample of Perspective TransformationNitin Suyan PanchalÎncă nu există evaluări
- Factors: How Time and Interest Affect MoneyDocument44 paginiFactors: How Time and Interest Affect Moneyomarsiddiqui8Încă nu există evaluări
- Math21-1 Assignment 2 (A2)Document2 paginiMath21-1 Assignment 2 (A2)patÎncă nu există evaluări
- Florin Curta: FEMALE DRESS AND "SLAVIC" BOW FIBULAE IN GREECEDocument46 paginiFlorin Curta: FEMALE DRESS AND "SLAVIC" BOW FIBULAE IN GREECEBeg1986Încă nu există evaluări