S-ar putea să vă placă și
- Routing Algorithms 1663584102198Document120 paginiRouting Algorithms 1663584102198Hari RamÎncă nu există evaluări
- CH 22Document43 paginiCH 22ADÎncă nu există evaluări
- Unit5 Part1Document34 paginiUnit5 Part1OutLaw LuciferÎncă nu există evaluări
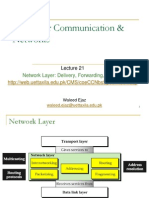
- Delivery, Forwarding, RoutingDocument47 paginiDelivery, Forwarding, RoutingARYAMAN DWIVEDIÎncă nu există evaluări
- Data Communication and Networking CHDocument83 paginiData Communication and Networking CHUzair KhanÎncă nu există evaluări
- Network Layer - RoutingDocument83 paginiNetwork Layer - RoutingRohan BhattadÎncă nu există evaluări
- Network Layer: Delivery, Forwarding, and RoutingDocument42 paginiNetwork Layer: Delivery, Forwarding, and RoutingAqsa IsmailÎncă nu există evaluări
- CH 22Document84 paginiCH 22Kumar BÎncă nu există evaluări
- L11CN :network Layer:Delivery, Forwarding, and Routing.Document23 paginiL11CN :network Layer:Delivery, Forwarding, and Routing.Ahmad Shdifat100% (1)
- Network Layer: Delivery, Forwarding, and Routing: Solutions To Review Questions and ExercisesDocument6 paginiNetwork Layer: Delivery, Forwarding, and Routing: Solutions To Review Questions and ExercisesDiponegoro Muhammad KhanÎncă nu există evaluări
- CLO 10 (Ch21, 22, 25)Document38 paginiCLO 10 (Ch21, 22, 25)LujainÎncă nu există evaluări
- Unit 3Document106 paginiUnit 3sona jainÎncă nu există evaluări
- Network Layer: Delivery, Forwarding, and RoutingDocument31 paginiNetwork Layer: Delivery, Forwarding, and Routingyuwee yiiiÎncă nu există evaluări
- Unit 5 Notes - Computer CommunicationDocument32 paginiUnit 5 Notes - Computer CommunicationCooldude 69Încă nu există evaluări
- RoutingDocument43 paginiRoutingJasÎncă nu există evaluări
- RoutingDocument27 paginiRoutingSirf VivekÎncă nu există evaluări
- Unicast RoutingDocument70 paginiUnicast RoutingKarthik YogeshÎncă nu există evaluări
- RoutingDocument42 paginiRoutingKumar MahadikÎncă nu există evaluări
- AssignmentDocument4 paginiAssignmentHima Bindhu BusireddyÎncă nu există evaluări
- Module 4 RoutingDocument104 paginiModule 4 RoutingsureshÎncă nu există evaluări
- 6 Delivery - Forwarding - and - Routing - of - IP - PacketsDocument33 pagini6 Delivery - Forwarding - and - Routing - of - IP - PacketsNatnael YosephÎncă nu există evaluări
- ch22 Network Layer Routing Forwarding and DeliveryDocument40 paginich22 Network Layer Routing Forwarding and Deliverysnehasikdar9279Încă nu există evaluări
- Unicast RoutingDocument58 paginiUnicast RoutingjoelanandrajÎncă nu există evaluări
- Network LayerDocument18 paginiNetwork LayerChamara PrasannaÎncă nu există evaluări
- Routing ProtocolsDocument28 paginiRouting ProtocolstiffÎncă nu există evaluări
- Advanced Wireless Networks: Technology and Business ModelsDe la EverandAdvanced Wireless Networks: Technology and Business ModelsÎncă nu există evaluări
- Delivery and Routing of IP Packets1 (Classless)Document28 paginiDelivery and Routing of IP Packets1 (Classless)mustafa kerramÎncă nu există evaluări
- COMPUTER NETWORKS Answers To Selected Exam QuestionsDocument38 paginiCOMPUTER NETWORKS Answers To Selected Exam QuestionsSaswat Kumar0% (1)
- Report Simulation Assignment 5Document22 paginiReport Simulation Assignment 5Ebraheem Alhaddad100% (5)
- Computer Communication & Networks: Network Layer: Delivery, Forwarding, RoutingDocument36 paginiComputer Communication & Networks: Network Layer: Delivery, Forwarding, RoutingAli AhmadÎncă nu există evaluări
- CnqaDocument33 paginiCnqaSuman AhujaÎncă nu există evaluări
- Network LayerDocument27 paginiNetwork Layerrktiwary256034Încă nu există evaluări
- Routing Information Protocol (RIP) : NETE0514 Presented by DR - Apichan KanjanavapastitDocument35 paginiRouting Information Protocol (RIP) : NETE0514 Presented by DR - Apichan KanjanavapastitRoystan DalmeidaÎncă nu există evaluări
- Ee534 Lab7 (Duong - Le)Document9 paginiEe534 Lab7 (Duong - Le)Rock RáchÎncă nu există evaluări
- Network Layer: Delivery, Forwarding, and RoutingDocument62 paginiNetwork Layer: Delivery, Forwarding, and RoutingAarti KhareÎncă nu există evaluări
- CNS Mod 3 NLDocument23 paginiCNS Mod 3 NLSamanthÎncă nu există evaluări
- Ospf Lab Opnet It GuruDocument3 paginiOspf Lab Opnet It GuruSheraz100% (1)
- CCNA 2:module 2: Options With Highlight Colours Are Correct AnswerDocument4 paginiCCNA 2:module 2: Options With Highlight Colours Are Correct Answertrp2529100% (2)
- L5 Table Driven Routing ProtocolsDocument7 paginiL5 Table Driven Routing ProtocolsSagar ChoudhuryÎncă nu există evaluări
- Ospf Lab Opnet It GuruDocument3 paginiOspf Lab Opnet It GuruMateo KeretićÎncă nu există evaluări
- Unit 5Document167 paginiUnit 5b628234Încă nu există evaluări
- 22 22 - 1 1 Delivery Delivery: Topics Discussed in This Section: Topics Discussed in This SectionDocument10 pagini22 22 - 1 1 Delivery Delivery: Topics Discussed in This Section: Topics Discussed in This SectionSai SileshÎncă nu există evaluări
- Unit-Iii: (Q) Explain Network Layer Design Issues? (2M/5M)Document28 paginiUnit-Iii: (Q) Explain Network Layer Design Issues? (2M/5M)karthik vaddiÎncă nu există evaluări
- Network Layer Delivery, Forwarding and RoutingDocument18 paginiNetwork Layer Delivery, Forwarding and RoutingVani TelluriÎncă nu există evaluări
- Chapter 4 Bit4001+q+ExDocument77 paginiChapter 4 Bit4001+q+ExĐình Đức PhạmÎncă nu există evaluări
- Routing Protocols (RIP, OSPF, and BGP) : Mi-Jung Choi Dept. of Computer Science and Engineering Mjchoi@postech - Ac.krDocument86 paginiRouting Protocols (RIP, OSPF, and BGP) : Mi-Jung Choi Dept. of Computer Science and Engineering Mjchoi@postech - Ac.krHafeez MohammedÎncă nu există evaluări
- Routing AlgorithmsDocument10 paginiRouting AlgorithmsBabita NaagarÎncă nu există evaluări
- Overview Network LayerDocument79 paginiOverview Network Layerrktiwary256034Încă nu există evaluări
- CNModel2 Answer KeyDocument27 paginiCNModel2 Answer KeyAnitha MÎncă nu există evaluări
- Case Study of Various Routing AlgorithmDocument25 paginiCase Study of Various Routing AlgorithmVijendra SolankiÎncă nu există evaluări
- Delivery, Forwarding, and Routing of IP PacketsDocument68 paginiDelivery, Forwarding, and Routing of IP PacketsYazanAlomariÎncă nu există evaluări
- CCNA Exploration 2: Module Final Exam Answers 2Document8 paginiCCNA Exploration 2: Module Final Exam Answers 2Peter PoelmansÎncă nu există evaluări
- What Is Routing AlgorithmDocument12 paginiWhat Is Routing AlgorithmTum BinÎncă nu există evaluări
- CN R20 Unit-3Document19 paginiCN R20 Unit-3Indreshbabu BoyaÎncă nu există evaluări
- Unit 3 Routing: CO3: Outline The Functionality of Each Layer of The NetworkDocument23 paginiUnit 3 Routing: CO3: Outline The Functionality of Each Layer of The NetworkB.BijuÎncă nu există evaluări
- TCP IP Protocol Suite Chap-06 Delivery and Routing of IP PacketsDocument58 paginiTCP IP Protocol Suite Chap-06 Delivery and Routing of IP PacketsRahul RajÎncă nu există evaluări
- Indoor Radio Planning: A Practical Guide for 2G, 3G and 4GDe la EverandIndoor Radio Planning: A Practical Guide for 2G, 3G and 4GEvaluare: 5 din 5 stele5/5 (1)
- Transportation and Power Grid in Smart Cities: Communication Networks and ServicesDe la EverandTransportation and Power Grid in Smart Cities: Communication Networks and ServicesÎncă nu există evaluări
- "Communication Skill & Personality Development": Four Week Online Faculty Development Programme (Mooc)Document2 pagini"Communication Skill & Personality Development": Four Week Online Faculty Development Programme (Mooc)SagarVanaraseÎncă nu există evaluări
- Vision - e - Insight 2019-20 PDFDocument155 paginiVision - e - Insight 2019-20 PDFSagarVanaraseÎncă nu există evaluări
- Diabetes Reversal by Plant Based Diet Dr. BiswaroopDocument7 paginiDiabetes Reversal by Plant Based Diet Dr. Biswaroopsatya_vanapalli3422100% (1)
- Rativilasjh PDFDocument225 paginiRativilasjh PDFSagarVanaraseÎncă nu există evaluări
- RativilasjhDocument225 paginiRativilasjhSagarVanaraseÎncă nu există evaluări
- E-Commerce Security: COEN 351 Thomas Schwarz, S.JDocument14 paginiE-Commerce Security: COEN 351 Thomas Schwarz, S.JSagarVanaraseÎncă nu există evaluări
- Pki 2Document55 paginiPki 2José Rocha RamirezÎncă nu există evaluări
- CMPS 319: Blueprint For SecurityDocument56 paginiCMPS 319: Blueprint For SecuritySagarVanaraseÎncă nu există evaluări
- Company Organization ChartDocument3 paginiCompany Organization ChartOm Prakash - AIPL(QC)Încă nu există evaluări
- Ch-7 Device ManagementDocument71 paginiCh-7 Device ManagementAmna AtiqÎncă nu există evaluări
- Project Synopsis SampleDocument7 paginiProject Synopsis SampleDhwani PatelÎncă nu există evaluări
- Global Absence FastFormula User Guide 20200908Document124 paginiGlobal Absence FastFormula User Guide 20200908Gopinath Nat100% (1)
- Bits g553 Real Time SystemsDocument2 paginiBits g553 Real Time SystemsUriti Venkata Naga KishoreÎncă nu există evaluări
- Walkthrough To Install and Operate The Hydrologic Evaluation of Landfill Performance (HELP) Model v3.07Document13 paginiWalkthrough To Install and Operate The Hydrologic Evaluation of Landfill Performance (HELP) Model v3.07Jorge_J_JÎncă nu există evaluări
- The LyX UserDocument211 paginiThe LyX UserPraveen KalkundriÎncă nu există evaluări
- Privacy, Security and Trust Issues Arising From Cloud ComputingDocument33 paginiPrivacy, Security and Trust Issues Arising From Cloud ComputingmohammedÎncă nu există evaluări
- SCADADocument6 paginiSCADAdseshireddyÎncă nu există evaluări
- Time Table For Summer 2024 Theory ExaminationDocument1 paginăTime Table For Summer 2024 Theory ExaminationDhvani MistryÎncă nu există evaluări
- Kenticocms Tutorial AspxDocument99 paginiKenticocms Tutorial Aspxapi-3816540Încă nu există evaluări
- Xeon 5400 AnimatedDocument12 paginiXeon 5400 AnimatedkshehzadÎncă nu există evaluări
- Mockito Vs EasyMock Mockito - Mockito WikiDocument1 paginăMockito Vs EasyMock Mockito - Mockito Wikiგენო მუმლაძეÎncă nu există evaluări
- ENOVIA VPM TrainingDocument190 paginiENOVIA VPM TrainingDan OpritaÎncă nu există evaluări
- Introduction To Advanced Operating SystemDocument27 paginiIntroduction To Advanced Operating SystemmadhurocksktmÎncă nu există evaluări
- Empowerment Technologies2Document33 paginiEmpowerment Technologies2joanna camaingÎncă nu există evaluări
- CHAPTER 05 - Public-Key CryptographyDocument29 paginiCHAPTER 05 - Public-Key CryptographyPÎncă nu există evaluări
- Class 6 Chapter 4 AI With Python 1Document5 paginiClass 6 Chapter 4 AI With Python 1namanpsinhaÎncă nu există evaluări
- HCIA-WLAN V3.0 Lab GuideDocument70 paginiHCIA-WLAN V3.0 Lab GuideStavros T.Încă nu există evaluări
- Post L1 - 2030Document32 paginiPost L1 - 2030Ya LanÎncă nu există evaluări
- DanBuss DNIPDocument26 paginiDanBuss DNIPAnwar CordovaÎncă nu există evaluări
- 30028Document16 pagini30028Syed Nadeem AhmedÎncă nu există evaluări
- MIS Development ProcessDocument13 paginiMIS Development ProcessDivesh Chandra100% (1)
- Social Media Safety For TeensDocument1 paginăSocial Media Safety For TeensActionNewsJaxÎncă nu există evaluări
- Google Adsense Beginners Guide Free e BookDocument10 paginiGoogle Adsense Beginners Guide Free e BookBeytown WorldÎncă nu există evaluări
- Uml Notes by Shaik Bilal AhmedDocument10 paginiUml Notes by Shaik Bilal AhmedShaik Bilal AhmedÎncă nu există evaluări
- Resume of Sangeetha RadhakrishnanDocument9 paginiResume of Sangeetha Radhakrishnansangee_radharishnanÎncă nu există evaluări
- ICAT Online Producer Quick Reference GuideDocument9 paginiICAT Online Producer Quick Reference GuideAlex FaubelÎncă nu există evaluări
- Creating 3-Tier ArchitectureDocument71 paginiCreating 3-Tier ArchitecturesoloÎncă nu există evaluări
- Red Hat Linux Version 9Document38 paginiRed Hat Linux Version 9zahimbÎncă nu există evaluări