S-ar putea să vă placă și
- How To Assemble ComputerDocument9 paginiHow To Assemble Computerapi-3801329100% (1)
- ErrataDocument42 paginiErrataTamára SalvatoriÎncă nu există evaluări
- Q6 SolutionDocument1 paginăQ6 Solutionapi-3801329Încă nu există evaluări
- Exercise Solution) 3Document10 paginiExercise Solution) 3api-3801329Încă nu există evaluări
- Pentium 4 Pipe LiningDocument7 paginiPentium 4 Pipe Liningapi-3801329100% (5)
- Q5 SolutionDocument1 paginăQ5 Solutionapi-3801329Încă nu există evaluări
- Q4 SolutionDocument2 paginiQ4 Solutionapi-3801329Încă nu există evaluări
- Q1 SolutionDocument3 paginiQ1 Solutionapi-3801329Încă nu există evaluări
- Q3 SolutionDocument1 paginăQ3 Solutionapi-3801329Încă nu există evaluări
- Q2 SolutionDocument1 paginăQ2 Solutionapi-3801329Încă nu există evaluări
- Exercise Solution) 1Document3 paginiExercise Solution) 1api-3801329Încă nu există evaluări
- Exercise Solution) 2Document7 paginiExercise Solution) 2api-3801329Încă nu există evaluări
- Height-Biased Leftist Heaps Advanced)Document91 paginiHeight-Biased Leftist Heaps Advanced)api-3801329Încă nu există evaluări
- Memory StructureDocument18 paginiMemory Structureapi-3801329Încă nu există evaluări
- Power PC (G5)Document28 paginiPower PC (G5)api-3801329100% (1)
- 2 3 TreesDocument69 pagini2 3 Treesapi-3801329Încă nu există evaluări
- Pentium 4 StructureDocument38 paginiPentium 4 Structureapi-3801329100% (6)
- Computer Structure and ComponentsDocument18 paginiComputer Structure and Componentsapi-3801329100% (1)
- Splay Trees Advanced)Document166 paginiSplay Trees Advanced)api-3801329Încă nu există evaluări
- History of ComputersDocument44 paginiHistory of Computersapi-3801329Încă nu există evaluări
- Weight-Biased Leftist Heaps Advanced)Document64 paginiWeight-Biased Leftist Heaps Advanced)api-3801329Încă nu există evaluări
- Multiple Interrupts and Buses StructureDocument17 paginiMultiple Interrupts and Buses Structureapi-3801329100% (2)
- Skew Heaps Advanced)Document61 paginiSkew Heaps Advanced)api-3801329100% (2)
- ProbingDocument5 paginiProbingapi-3801329Încă nu există evaluări
- Binomial & Fibonacci Heap Advanced)Document60 paginiBinomial & Fibonacci Heap Advanced)api-3801329100% (3)
- Graph Search Methods ExamplesDocument37 paginiGraph Search Methods Examplesapi-3801329Încă nu există evaluări
- Red-Black Trees Advanced)Document44 paginiRed-Black Trees Advanced)api-3801329100% (2)
- GraphsDocument32 paginiGraphsapi-3801329100% (1)
- HashingDocument42 paginiHashingapi-3801329Încă nu există evaluări
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5783)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (890)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (72)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (119)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- K Means Cluster Analysis in SPSSDocument2 paginiK Means Cluster Analysis in SPSSsureshexecutive0% (1)
- Polymorphism in OOP - How objects decide behavior at runtimeDocument4 paginiPolymorphism in OOP - How objects decide behavior at runtimeAmar DnÎncă nu există evaluări
- DotNet SQL Interview QuestionsDocument167 paginiDotNet SQL Interview QuestionsDuccati ZiÎncă nu există evaluări
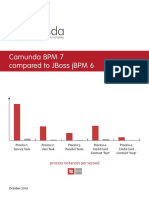
- 477 - Camunda BPM 7 Com Pared To JBossDocument17 pagini477 - Camunda BPM 7 Com Pared To JBossManojBhangaleÎncă nu există evaluări
- Configuring ANSYS CFX 16 Distributed with Platform or Intel MPIDocument9 paginiConfiguring ANSYS CFX 16 Distributed with Platform or Intel MPIOscar Choque JaqquehuaÎncă nu există evaluări
- (Dex7111) Python Programming For Beginners - Robert RichardsDocument53 pagini(Dex7111) Python Programming For Beginners - Robert RichardsAnkit PunjabiÎncă nu există evaluări
- Chemical Engineering Computation: 1: Introduction To MATLABDocument35 paginiChemical Engineering Computation: 1: Introduction To MATLABMuhammad Fakhrul IslamÎncă nu există evaluări
- L 2Document48 paginiL 2pinku0911Încă nu există evaluări
- Using The C Compilers On NetbeansDocument12 paginiUsing The C Compilers On NetbeansDoug RedÎncă nu există evaluări
- Memory Management 1 PDFDocument42 paginiMemory Management 1 PDFLijo Philip100% (1)
- Idle Time ProcessDocument7 paginiIdle Time ProcessAun RazaÎncă nu există evaluări
- Big BasketDocument13 paginiBig BasketHimanshu Thakur25% (4)
- Interface Between File System and IOCS Consists ofDocument5 paginiInterface Between File System and IOCS Consists ofSrinivasa Rao TÎncă nu există evaluări
- VSP SVDocument3 paginiVSP SVNur Akbar Dibyohusodo30% (10)
- Omninas Usermanual EnglishDocument170 paginiOmninas Usermanual EnglishEric WhitfieldÎncă nu există evaluări
- Manage hotels online with this systemDocument2 paginiManage hotels online with this systemsalahÎncă nu există evaluări
- IITD Exam SolutionDocument9 paginiIITD Exam SolutionRohit JoshiÎncă nu există evaluări
- Field Power: Work Force Management System For STC Network OperationsDocument17 paginiField Power: Work Force Management System For STC Network Operationsnadeemgza100% (3)
- Fabric OS TroubleshootingDocument120 paginiFabric OS TroubleshootingSayan GhoshÎncă nu există evaluări
- Veritas Backup Exec 16 DsDocument5 paginiVeritas Backup Exec 16 Dsjuan.pasion3696Încă nu există evaluări
- Linear ProgrammingDocument2 paginiLinear ProgrammingKareem MohdÎncă nu există evaluări
- TsiLang Users GuideDocument99 paginiTsiLang Users Guidestevecrk100% (1)
- Latihan Soal IDocument25 paginiLatihan Soal IHudan RamadhonaÎncă nu există evaluări
- Online Complaint Management SystemDocument15 paginiOnline Complaint Management Systemrohithreddy1234Încă nu există evaluări
- Configuring Terminal Services Core FunctionalityDocument20 paginiConfiguring Terminal Services Core FunctionalityNelsonbohrÎncă nu există evaluări
- Blue Pill for Your Phone: Reverse Engineering ARM TrustZone and HypervisorDocument62 paginiBlue Pill for Your Phone: Reverse Engineering ARM TrustZone and HypervisorSơn PhạmÎncă nu există evaluări
- Davidmc-Easydis Read This FirstDocument6 paginiDavidmc-Easydis Read This FirstsanistoroaeÎncă nu există evaluări
- MS DOS Ebook For BeginnerDocument19 paginiMS DOS Ebook For Beginnerramaisgod86% (7)
- Minimum Spanning TreeDocument20 paginiMinimum Spanning TreeRahul MishraÎncă nu există evaluări
- How To Interpolate Pressure Data Obtained by Other Tools Into Structure Fe Model Via Patran - v2010Document8 paginiHow To Interpolate Pressure Data Obtained by Other Tools Into Structure Fe Model Via Patran - v2010cen1510353Încă nu există evaluări