S-ar putea să vă placă și
- Modern Introduction to Object Oriented Programming for Prospective DevelopersDe la EverandModern Introduction to Object Oriented Programming for Prospective DevelopersÎncă nu există evaluări
- Digital Signal Processing (DSP) with Python ProgrammingDe la EverandDigital Signal Processing (DSP) with Python ProgrammingÎncă nu există evaluări
- Arithmetic CodingDocument6 paginiArithmetic CodingperhackerÎncă nu există evaluări
- Arithmetic Coding: Implementation Details and ExamplesDocument11 paginiArithmetic Coding: Implementation Details and ExamplesShunmuga PriyanÎncă nu există evaluări
- Compression IIDocument51 paginiCompression IIJagadeesh NaniÎncă nu există evaluări
- Why Needed?: Without Compression, These Applications Would Not Be FeasibleDocument11 paginiWhy Needed?: Without Compression, These Applications Would Not Be Feasiblesmile00972Încă nu există evaluări
- Capacity of The Binary Erasure Channel: 1 CommunicationDocument4 paginiCapacity of The Binary Erasure Channel: 1 CommunicationGeremu TilahunÎncă nu există evaluări
- Dis76crete Ch911Document16 paginiDis76crete Ch911narendraÎncă nu există evaluări
- Chapter 4 - Arithmetic CodingDocument66 paginiChapter 4 - Arithmetic Codingakshay patelÎncă nu există evaluări
- Lecture35-37 SourceCodingDocument20 paginiLecture35-37 SourceCodingParveen SwamiÎncă nu există evaluări
- Arithmetic Coding: EncodingDocument2 paginiArithmetic Coding: EncodingPriyanshuÎncă nu există evaluări
- CH 3 DatalinkDocument35 paginiCH 3 DatalinksimayyilmazÎncă nu există evaluări
- Huffman and Lempel-Ziv-WelchDocument14 paginiHuffman and Lempel-Ziv-WelchDavid SiegfriedÎncă nu există evaluări
- 5 Binary Codes: 5.1 Noise: Error DetectionDocument7 pagini5 Binary Codes: 5.1 Noise: Error DetectionKamalendu Kumar DasÎncă nu există evaluări
- Range CodingDocument6 paginiRange Codingnigel989Încă nu există evaluări
- S.72-227 Digital Communication Systems: Convolutional CodesDocument26 paginiS.72-227 Digital Communication Systems: Convolutional Codesjoydeep12Încă nu există evaluări
- Data Compression Data Compression: Chapter FourDocument22 paginiData Compression Data Compression: Chapter FourDawit BassaÎncă nu există evaluări
- Witten Acm 87 Ar It HM CodingDocument21 paginiWitten Acm 87 Ar It HM CodingfloriniiiÎncă nu există evaluări
- Low Density Parity Check Codes For Erasure Protection: Alexander Sennhauser April 22, 2005Document20 paginiLow Density Parity Check Codes For Erasure Protection: Alexander Sennhauser April 22, 2005Desikan SampathÎncă nu există evaluări
- A Short Course On Error-Correcting Codes: Mario Blaum C All Rights ReservedDocument104 paginiA Short Course On Error-Correcting Codes: Mario Blaum C All Rights ReservedGaston GBÎncă nu există evaluări
- Gray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8Document51 paginiGray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8kamnakhannaÎncă nu există evaluări
- Convolution Codes: 1.0 PrologueDocument26 paginiConvolution Codes: 1.0 PrologueGourgobinda Satyabrata AcharyaÎncă nu există evaluări
- Arithmetic CodingDocument5 paginiArithmetic CodingmiraclesureshÎncă nu există evaluări
- Problem Set 4: MAS160: Signals, Systems & Information For Media TechnologyDocument4 paginiProblem Set 4: MAS160: Signals, Systems & Information For Media TechnologyFatmir KelmendiÎncă nu există evaluări
- Data Compression ExplainedDocument92 paginiData Compression ExplainedLidia López100% (1)
- Problem Source Coding...Document7 paginiProblem Source Coding...Manoj KumarÎncă nu există evaluări
- Sequential Prog. Lec 1Document39 paginiSequential Prog. Lec 1aabdurrahaman647Încă nu există evaluări
- Decoding of Convolutional CodesDocument3 paginiDecoding of Convolutional CodesTân ChipÎncă nu există evaluări
- Error Unit3Document15 paginiError Unit3MOHAMMAD DANISH KHANÎncă nu există evaluări
- Notes 7 2013 - Arithmetic CodingDocument34 paginiNotes 7 2013 - Arithmetic CodingperhackerÎncă nu există evaluări
- Arithmetic Code Discussion and ImplementationDocument11 paginiArithmetic Code Discussion and ImplementationperhackerÎncă nu există evaluări
- Arithmetic CodingDocument12 paginiArithmetic CodingPrashast MehraÎncă nu există evaluări
- SV5: Error Correcting Codes: Fachpraktikum SignalverarbeitungDocument7 paginiSV5: Error Correcting Codes: Fachpraktikum SignalverarbeitungBshAekÎncă nu există evaluări
- S.72-3320 Advanced Digital Communication (4 CR) : Convolutional CodesDocument26 paginiS.72-3320 Advanced Digital Communication (4 CR) : Convolutional CodesBalagovind BaluÎncă nu există evaluări
- Information Theory and Coding 2marksDocument12 paginiInformation Theory and Coding 2marksPrashaant YerrapragadaÎncă nu există evaluări
- Implementation of SHA-1 Algorithm, Using VerilogDocument3 paginiImplementation of SHA-1 Algorithm, Using VerilogAnkit VarshneyÎncă nu există evaluări
- Source Coding OmpressionDocument34 paginiSource Coding Ompression최규범Încă nu există evaluări
- LDPCDocument15 paginiLDPCThivagarRagavihtÎncă nu există evaluări
- 1 Introduction To Linear Block CodesDocument13 pagini1 Introduction To Linear Block CodesRini KamilÎncă nu există evaluări
- Arithmetic Coding Algorithm and Implementation IssuesDocument7 paginiArithmetic Coding Algorithm and Implementation IssuesperhackerÎncă nu există evaluări
- Error-Free Compression: Variable Length CodingDocument13 paginiError-Free Compression: Variable Length CodingVanithaÎncă nu există evaluări
- Mad Unit 3-JntuworldDocument53 paginiMad Unit 3-JntuworldDilip TheLipÎncă nu există evaluări
- Coding TheoryDocument203 paginiCoding TheoryoayzÎncă nu există evaluări
- The Data Link LayerDocument35 paginiThe Data Link Layernitu2012Încă nu există evaluări
- CS112: Modeling Uncertainty in Information Systems Homework 3 Due Friday, May 18 (See Below For Times)Document6 paginiCS112: Modeling Uncertainty in Information Systems Homework 3 Due Friday, May 18 (See Below For Times)Anritsi AnÎncă nu există evaluări
- Error Control Coding3Document24 paginiError Control Coding3DuongMinhSOnÎncă nu există evaluări
- Detecting Bit Errors: EctureDocument6 paginiDetecting Bit Errors: EctureaadrikaÎncă nu există evaluări
- (Lecture Notes) Jyrki Lahtonen - Convolutional Codes (With Exercises in Finnish) (2013) PDFDocument76 pagini(Lecture Notes) Jyrki Lahtonen - Convolutional Codes (With Exercises in Finnish) (2013) PDFAhsan JameelÎncă nu există evaluări
- Assignment of SuccessfulDocument5 paginiAssignment of SuccessfulLe Tien Dat (K18 HL)Încă nu există evaluări
- Huffman Coding AssignmentDocument7 paginiHuffman Coding AssignmentMavine0% (1)
- Coding Theory and Its ApplicationsDocument45 paginiCoding Theory and Its Applicationsnavisingla100% (1)
- 062 Teorija Informacije Aritmeticko KodiranjeDocument22 pagini062 Teorija Informacije Aritmeticko KodiranjeAidaVeispahicÎncă nu există evaluări
- Question Bank: P A RT A Unit IDocument13 paginiQuestion Bank: P A RT A Unit Imgirish2kÎncă nu există evaluări
- HW 3 SolDocument9 paginiHW 3 Sol123rÎncă nu există evaluări
- Topics 2 To 5 ADM PDFDocument39 paginiTopics 2 To 5 ADM PDFdanÎncă nu există evaluări
- Introduction To Communications: Source CodingDocument20 paginiIntroduction To Communications: Source CodingHarshaÎncă nu există evaluări
- String CompressionDocument13 paginiString CompressionvatarplÎncă nu există evaluări
- SC 12Document45 paginiSC 12Warrior BroÎncă nu există evaluări
- A Huffman-Based Text Encryption Algorithm: H (X) Leads To Zero Redundancy, That Is, Has The ExactDocument7 paginiA Huffman-Based Text Encryption Algorithm: H (X) Leads To Zero Redundancy, That Is, Has The ExactMalik ImranÎncă nu există evaluări
- UNIT5 Part 2-1-19Document19 paginiUNIT5 Part 2-1-19Venkateswara RajuÎncă nu există evaluări
- Solar Powered LED Street Light With Auto - Intensity ControlDocument16 paginiSolar Powered LED Street Light With Auto - Intensity Controljigar16789Încă nu există evaluări
- ECP Practical ManualDocument69 paginiECP Practical Manualjigar16789Încă nu există evaluări
- Report NewDocument3 paginiReport Newjigar16789Încă nu există evaluări
- Embedded SystemDocument13 paginiEmbedded Systemjigar16789100% (1)
- Unit 3 Microwave Tubes and MeasurementsDocument6 paginiUnit 3 Microwave Tubes and Measurementsjigar16789Încă nu există evaluări
- Optical CommunicationDocument6 paginiOptical Communicationjigar16789Încă nu există evaluări
- Student Quick Reference Part1 - ADS2012Document51 paginiStudent Quick Reference Part1 - ADS2012jigar16789Încă nu există evaluări
- Guide Project AssessmentsDocument6 paginiGuide Project Assessmentsjigar16789Încă nu există evaluări
- A Seminar Report On 5GDocument17 paginiA Seminar Report On 5GSameer Tiwari100% (3)
- QB EcDocument212 paginiQB Ecjigar16789100% (1)
- Overview of Missile Flight Control Systems: Paul B. JacksonDocument16 paginiOverview of Missile Flight Control Systems: Paul B. JacksonrobjohniiiÎncă nu există evaluări
- Effect of Moisture Absorption On The Properties of Natural FiberDocument6 paginiEffect of Moisture Absorption On The Properties of Natural FiberIsmadi IsmadiÎncă nu există evaluări
- UNIT1-Demand Management in Supply Chain Demand Planning and ForecastingDocument20 paginiUNIT1-Demand Management in Supply Chain Demand Planning and Forecastingshenbha50% (2)
- Water Cooled Chiller Operation & Maintenance ManualDocument13 paginiWater Cooled Chiller Operation & Maintenance ManualPaul KwongÎncă nu există evaluări
- EWAD-CF EEDEN15-435 Data Books EnglishDocument42 paginiEWAD-CF EEDEN15-435 Data Books EnglishrpufitaÎncă nu există evaluări
- LTTS Corporate BrochureDocument20 paginiLTTS Corporate BrochureshountyÎncă nu există evaluări
- Part 1Document120 paginiPart 1Raju Halder0% (1)
- The Mathematical Society of Serbia - 60 YearsDocument23 paginiThe Mathematical Society of Serbia - 60 YearsBranko Ma Branko TadicÎncă nu există evaluări
- Abbott 2021 ApJL 915 L5Document24 paginiAbbott 2021 ApJL 915 L5Manju SanthakumariÎncă nu există evaluări
- X2IPI ManualDocument51 paginiX2IPI ManualFadiliAhmedÎncă nu există evaluări
- Reliability Analysis Center: Practical Considerations in Calculating Reliability of Fielded ProductsDocument24 paginiReliability Analysis Center: Practical Considerations in Calculating Reliability of Fielded ProductsNg Wei LihÎncă nu există evaluări
- Manual Dimmer BukeDocument10 paginiManual Dimmer BukeJavi KatzÎncă nu există evaluări
- Camshaft Recommendation FormDocument3 paginiCamshaft Recommendation Formcrower_scribdÎncă nu există evaluări
- Water Level Sensor (Submersible)Document4 paginiWater Level Sensor (Submersible)anon_975837510Încă nu există evaluări
- Evaluation and Selection of Sustainable Strategy For Green Supply Chain Management ImplementationDocument28 paginiEvaluation and Selection of Sustainable Strategy For Green Supply Chain Management ImplementationMuhammad Dzaky Alfajr DirantonaÎncă nu există evaluări
- Chapter 1 - Steam GenerationDocument23 paginiChapter 1 - Steam GenerationAzhan FikriÎncă nu există evaluări
- Reducing The Efficiency Gap by Optimal Allocation Using Modified Assignment Problem For Apparel Industry in Sri LankaDocument1 paginăReducing The Efficiency Gap by Optimal Allocation Using Modified Assignment Problem For Apparel Industry in Sri LankaShivam BhandariÎncă nu există evaluări
- Selecting EquipmentDocument7 paginiSelecting EquipmentZara ShireenÎncă nu există evaluări
- Nested LoopsDocument11 paginiNested LoopssivaabhilashÎncă nu există evaluări
- Active Mathematics PDFDocument22 paginiActive Mathematics PDFgoingforward77Încă nu există evaluări
- Laser in ProsthodonticsDocument84 paginiLaser in ProsthodonticsmarwaÎncă nu există evaluări
- Analytic Geometry Parabola ProblemsDocument14 paginiAnalytic Geometry Parabola ProblemsOjit QuizonÎncă nu există evaluări
- PDF To Image Converter v2 HOW TO USEDocument3 paginiPDF To Image Converter v2 HOW TO USEfairfaxcyclesÎncă nu există evaluări
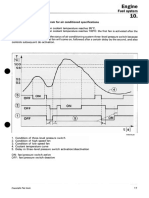
- Fiat Barchetta: EngineDocument20 paginiFiat Barchetta: EngineHallex OliveiraÎncă nu există evaluări
- Hemoglobin A1c: A) MES 2-Morpholinoethane Sulfonic Acid B) TRIS Tris (Hydroxymethyl) - AminomethaneDocument6 paginiHemoglobin A1c: A) MES 2-Morpholinoethane Sulfonic Acid B) TRIS Tris (Hydroxymethyl) - Aminomethanejoudi.jou95Încă nu există evaluări
- VI. HelicoptersDocument147 paginiVI. HelicopterssreekanthÎncă nu există evaluări
- Nylon Bag BisDocument13 paginiNylon Bag Bisbsnl.corp.pbÎncă nu există evaluări
- Rails BasicsDocument229 paginiRails BasicsachhuÎncă nu există evaluări
- Postmodernity in PiDocument2 paginiPostmodernity in Pixhardy27Încă nu există evaluări
- MCAT Uhs Past Paper (2008-2016)Document180 paginiMCAT Uhs Past Paper (2008-2016)Abdullah SheikhÎncă nu există evaluări