S-ar putea să vă placă și
- 3 - Interogari de SelectieDocument31 pagini3 - Interogari de SelectieSirbu OlgaÎncă nu există evaluări
- Modelele Autoregresive LiniareDocument10 paginiModelele Autoregresive LiniareMilu StefaniaÎncă nu există evaluări
- ASD2017 Curs3Document51 paginiASD2017 Curs3Andrei BulgaruÎncă nu există evaluări
- LpowerpoiititiDocument45 paginiLpowerpoiititiСтепа ПоповÎncă nu există evaluări
- Lucrarea 1Document4 paginiLucrarea 1Mihai PopescuÎncă nu există evaluări
- Regresie LiniaraDocument14 paginiRegresie Liniaratoiaemilia853Încă nu există evaluări
- Estimarea Parametrilor SistemelorDocument24 paginiEstimarea Parametrilor SistemelorGabriela Ecaterina Luca100% (1)
- Lab04 BD 2016Document7 paginiLab04 BD 2016CosminÎncă nu există evaluări
- RaportDocument13 paginiRaportАлина АмвÎncă nu există evaluări
- IS Lab1 IntroDocument6 paginiIS Lab1 IntroCostin PÎncă nu există evaluări
- KNN - Identificarea Claselor de Haine (Autosaved)Document20 paginiKNN - Identificarea Claselor de Haine (Autosaved)Livia GoldanÎncă nu există evaluări
- Prog. C++. Lab Nr. 7Document10 paginiProg. C++. Lab Nr. 7Andrian CiumacÎncă nu există evaluări
- Tema 1 MNDocument5 paginiTema 1 MNAndrei ErghelegiuÎncă nu există evaluări
- TI205 LescoStanislav laborator4TSDocument9 paginiTI205 LescoStanislav laborator4TSEliza CaramanÎncă nu există evaluări
- Raport 4Document11 paginiRaport 4Dan ZagoreanuÎncă nu există evaluări
- Structuri de Control În C++Document9 paginiStructuri de Control În C++DravenTTNÎncă nu există evaluări
- Utilizarea Tehnologiilor de Tip Data Mining in Inteligenta Computationala Invatarea NesupervizataDocument16 paginiUtilizarea Tehnologiilor de Tip Data Mining in Inteligenta Computationala Invatarea NesupervizataTudorÎncă nu există evaluări
- Curs 6Document61 paginiCurs 6VictorÎncă nu există evaluări
- PROCEDURI STOCATE ModificatDocument5 paginiPROCEDURI STOCATE ModificatCosmina BÎncă nu există evaluări
- Curs Fox ProDocument12 paginiCurs Fox PromeanbrakeÎncă nu există evaluări
- Sas 4Document10 paginiSas 4ralucaiordache103Încă nu există evaluări
- Lectii ANDocument111 paginiLectii ANAndreea ManoleÎncă nu există evaluări
- DoctCursS 2007Document16 paginiDoctCursS 2007Florin DobreÎncă nu există evaluări
- Modelare Si SimulareDocument19 paginiModelare Si Simulareza_napsterÎncă nu există evaluări
- 01-2 Etapele Realizarii Unui ModelDocument27 pagini01-2 Etapele Realizarii Unui ModelIonita IrinaÎncă nu există evaluări
- Lucrarea Nr. 3 - IdDocument10 paginiLucrarea Nr. 3 - Idnita.ioana.h4mÎncă nu există evaluări
- Laborator 1 Introducere in MatLABDocument5 paginiLaborator 1 Introducere in MatLABSergiu MoldovanÎncă nu există evaluări
- Laborator 1 - TS PDFDocument13 paginiLaborator 1 - TS PDFIoanaAlexandraÎncă nu există evaluări
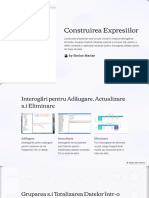
- Construirea ExpresiilorDocument8 paginiConstruirea ExpresiilorMarian SaneaÎncă nu există evaluări
- Capitol 6Document9 paginiCapitol 6luca ioanÎncă nu există evaluări
- Subiecte SCADocument23 paginiSubiecte SCASilvia Adelina MateescuÎncă nu există evaluări
- Curs 9 Reg Lineara 2Document36 paginiCurs 9 Reg Lineara 2Oana DrăganÎncă nu există evaluări
- Note Curs Lab 3Document11 paginiNote Curs Lab 3Adriana PadureÎncă nu există evaluări
- Curs 1 - SimulareaDocument13 paginiCurs 1 - SimulareaBanciuRomulusÎncă nu există evaluări
- PProiectAD Voloh Padure ApetreiDocument85 paginiPProiectAD Voloh Padure ApetreiDelia RaduÎncă nu există evaluări
- Teste FunctionaleDocument34 paginiTeste FunctionaleMarius BrătanÎncă nu există evaluări
- Asdc 4Document47 paginiAsdc 4Dan 421Încă nu există evaluări
- Curs 2Document11 paginiCurs 2Chioran MălinaÎncă nu există evaluări
- Curs POO Prof. Catalin Boja (Full)Document185 paginiCurs POO Prof. Catalin Boja (Full)Epuras Oana-Gabriela100% (1)
- Reprezentarea Unui Model de RezervorDocument9 paginiReprezentarea Unui Model de RezervorLaura Ghidia ElenaÎncă nu există evaluări
- Identificarea SISO Prin Algoritmul Online Metoda CMMPDocument30 paginiIdentificarea SISO Prin Algoritmul Online Metoda CMMPAndreea NovacescuÎncă nu există evaluări
- MatlabDocument216 paginiMatlabChiritoiu Tiberiu100% (1)
- Laborator PLSQL 2 PDFDocument12 paginiLaborator PLSQL 2 PDFCalin PopescuÎncă nu există evaluări
- Functii Categorii de FunctiiDocument19 paginiFunctii Categorii de FunctiiViorica TurcanÎncă nu există evaluări
- Anexa Excel - Formule Si FunctiiDocument9 paginiAnexa Excel - Formule Si Functiirotalin469Încă nu există evaluări
- Curs 10Document11 paginiCurs 10Maria RusuÎncă nu există evaluări
- L3 Java1Document8 paginiL3 Java1Alexandru GrigorițăÎncă nu există evaluări
- Programa Modul Excel 2019 AvansatDocument4 paginiPrograma Modul Excel 2019 Avansatmarius ivanÎncă nu există evaluări
- Slide Curs 5 Programare SAS 4Document30 paginiSlide Curs 5 Programare SAS 4Diana Alina AÎncă nu există evaluări
- Isi SC4Document29 paginiIsi SC4Miruna -AlondraÎncă nu există evaluări
- Analiza AlgoritmilorDocument11 paginiAnaliza AlgoritmilorLuchian CristinaÎncă nu există evaluări
- Proiect Statistica IDDocument4 paginiProiect Statistica IDBompa Calin Andrei100% (1)
- Laborator NR 4 TestareDocument5 paginiLaborator NR 4 TestareTina CrisÎncă nu există evaluări
- Metoda Six Sigma: Creșterea calității și consecvenței afacerii dvs.De la EverandMetoda Six Sigma: Creșterea calității și consecvenței afacerii dvs.Încă nu există evaluări