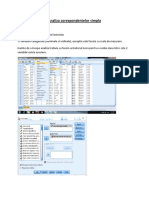
S-ar putea să vă placă și
- General Linear ModelDocument169 paginiGeneral Linear ModelDarwin12100% (1)
- Analiza Multivariata A VariatieiDocument8 paginiAnaliza Multivariata A VariatieiChirita VasiÎncă nu există evaluări
- Teorie Analiza VariatieiDocument4 paginiTeorie Analiza VariatieiInes AndrasiÎncă nu există evaluări
- AnovaDocument4 paginiAnovaOana StefanÎncă nu există evaluări
- Regresie MultivariataDocument9 paginiRegresie MultivariataMadalina DragomirÎncă nu există evaluări
- MANCOVADocument4 paginiMANCOVAmarriaÎncă nu există evaluări
- AnovaDocument9 paginiAnovaDiana Lepadatu0% (1)
- Regresia MultiplaDocument14 paginiRegresia MultiplaAdy NemesÎncă nu există evaluări
- Ancova PDFDocument9 paginiAncova PDFAndra Ceanca100% (1)
- Regresia MultiplaDocument10 paginiRegresia MultiplaDiana MartonÎncă nu există evaluări
- AnovaDocument3 paginiAnovaSimion G. Dragoş-MihaiÎncă nu există evaluări
- Regresia Liniara MultiplaDocument4 paginiRegresia Liniara MultiplaDaiana CiobanuÎncă nu există evaluări
- Subiecte Examen Metodologia Cercetarii PsihologiceDocument2 paginiSubiecte Examen Metodologia Cercetarii PsihologicePopa RemusÎncă nu există evaluări
- Analiza DiscriminantuluiDocument7 paginiAnaliza DiscriminantuluikikaidanÎncă nu există evaluări
- Designuri ExperimentaleDocument10 paginiDesignuri ExperimentaleCla OanaÎncă nu există evaluări
- 5 UI5 Elemente de Analiza Dispersion AlaDocument24 pagini5 UI5 Elemente de Analiza Dispersion AlaRazvan AsaveiÎncă nu există evaluări
- Design ExperimentalDocument7 paginiDesign ExperimentalileanasinzianaÎncă nu există evaluări
- Anova - Note de Curs 2Document31 paginiAnova - Note de Curs 2avratÎncă nu există evaluări
- Analiza Multivariata A DatelorDocument17 paginiAnaliza Multivariata A DatelorDaniel NegruÎncă nu există evaluări
- AnovaDocument56 paginiAnovaAna JumaraÎncă nu există evaluări
- Curs AnovaDocument35 paginiCurs AnovaVasile Rotaru100% (1)
- StatWork 5Document9 paginiStatWork 5Bianca MoldovanÎncă nu există evaluări
- Interpret AriDocument7 paginiInterpret AriMihaela DraghiciÎncă nu există evaluări
- Analiza Datelor de MKDocument33 paginiAnaliza Datelor de MKvoinicutzaÎncă nu există evaluări
- Note de Curs Modele Si Programe de Analiza A DatelorDocument30 paginiNote de Curs Modele Si Programe de Analiza A DatelorNarcisa MariaÎncă nu există evaluări
- Spss Curs 10 (Autosaved)Document29 paginiSpss Curs 10 (Autosaved)Stan Adelina-MihaelaÎncă nu există evaluări
- Mihaela Moscalu ANOVADocument34 paginiMihaela Moscalu ANOVAAndaPintilie100% (3)
- Mihaela Moscalu ANOVA PDFDocument34 paginiMihaela Moscalu ANOVA PDFDaniela DnÎncă nu există evaluări
- Metoda de Regresie Liniara SimplaDocument22 paginiMetoda de Regresie Liniara SimplaDragoi CristianÎncă nu există evaluări
- Cap 55 Analiza Functiei DiscriminantDocument18 paginiCap 55 Analiza Functiei DiscriminantAlin Iustinian ToderitaÎncă nu există evaluări
- Analiza UnivariataDocument11 paginiAnaliza UnivariataMIRCEAÎncă nu există evaluări
- Proiectarea Experimentelor in Economie - AnovaDocument14 paginiProiectarea Experimentelor in Economie - AnovaAlex VlÎncă nu există evaluări
- Referat SPSSDocument73 paginiReferat SPSSDaniel NegruÎncă nu există evaluări
- Cap. 22. Analiza FactorialaDocument30 paginiCap. 22. Analiza FactorialaLiviu Ioan HreniucÎncă nu există evaluări
- ProiectDocument16 paginiProiectCristina STÎncă nu există evaluări
- Itemi Care Poate Vor Fi La ExamenDocument7 paginiItemi Care Poate Vor Fi La ExamenAgdr AÎncă nu există evaluări
- ANOVA - Curs 2018Document5 paginiANOVA - Curs 2018violetaÎncă nu există evaluări
- ANOVA GeneralitatiDocument18 paginiANOVA GeneralitatiLevente DobaiÎncă nu există evaluări
- C Erori Model de Regresie LiniarăDocument11 paginiC Erori Model de Regresie LiniarăLupuț Aura LăcrimioaraÎncă nu există evaluări
- GLM Univariate - StatisticsDocument38 paginiGLM Univariate - StatisticsSorin AmurariteiÎncă nu există evaluări
- Anova One WayDocument9 paginiAnova One WayAntonia BarbuÎncă nu există evaluări
- Anova MRDocument31 paginiAnova MRMarilena ClaudiaÎncă nu există evaluări
- Curs 12 - PanelDocument21 paginiCurs 12 - PanelMistoiu NicolaeÎncă nu există evaluări
- ANALIZA FACORIAL - PrezentareDocument5 paginiANALIZA FACORIAL - PrezentareFlorin-AlinÎncă nu există evaluări
- StatisticaDocument13 paginiStatisticaIonela KoteleaÎncă nu există evaluări
- Curs Econometrie - Ultima ParteDocument23 paginiCurs Econometrie - Ultima Partealina mÎncă nu există evaluări
- Metode Avansate in Cercetarea SocialaDocument14 paginiMetode Avansate in Cercetarea Socialabdp_021Încă nu există evaluări
- Regresia Si CorelatiaDocument16 paginiRegresia Si CorelatiaAnamaria Cerasela AndreiÎncă nu există evaluări
- Analiza FactorialăDocument7 paginiAnaliza FactorialăJennifer Parker100% (1)
- Aspecte Importante EconometrieDocument6 paginiAspecte Importante EconometrieMihaela DraghiciÎncă nu există evaluări
- Popa M. - Elem Strategie A Analizei StatisticeDocument9 paginiPopa M. - Elem Strategie A Analizei StatisticeAlina Elena CîrsteaÎncă nu există evaluări
- Indicatorii VariatieiDocument11 paginiIndicatorii VariatieiAminaÎncă nu există evaluări
- Curs 12 Csa (2)Document5 paginiCurs 12 Csa (2)Ade AdriiÎncă nu există evaluări
- Modelarea MatematicaDocument13 paginiModelarea MatematicaGabriel Nanora100% (1)
- Aplicatie 1 ADDocument4 paginiAplicatie 1 ADCatalin CrisanÎncă nu există evaluări
- CURS NR. 13 Osteoporoza, 2, Ew Microsoft PowerPoint PresentationDocument36 paginiCURS NR. 13 Osteoporoza, 2, Ew Microsoft PowerPoint PresentationAlina RosioruÎncă nu există evaluări
- Teorie Analiza DiscriminantaDocument5 paginiTeorie Analiza DiscriminantaLaura ConstantinÎncă nu există evaluări
- Analiza Discriminanta FinalDocument25 paginiAnaliza Discriminanta FinalCatalin CrisanÎncă nu există evaluări
- Teorie Analiza DiscriminantaDocument5 paginiTeorie Analiza DiscriminantaLaura ConstantinÎncă nu există evaluări
- ACP TeorieDocument11 paginiACP TeorieCatalin CrisanÎncă nu există evaluări
- Analiza FactorialaDocument1 paginăAnaliza FactorialaCatalin CrisanÎncă nu există evaluări
- Analiza FactorialaDocument1 paginăAnaliza FactorialaCatalin CrisanÎncă nu există evaluări
- Analiza Corespondentelor SimplaDocument5 paginiAnaliza Corespondentelor SimplaCatalin CrisanÎncă nu există evaluări
- Analiza Corespondenţelor MultipleDocument12 paginiAnaliza Corespondenţelor MultiplezatharisÎncă nu există evaluări
- Analiza Corespondentelor MultiplaDocument5 paginiAnaliza Corespondentelor MultiplaCatalin CrisanÎncă nu există evaluări
- Onu R. Andrei - SiadDocument13 paginiOnu R. Andrei - SiadCatalin CrisanÎncă nu există evaluări
- Teorie AC 1Document14 paginiTeorie AC 1Larisa TomoaieÎncă nu există evaluări
- Mca 2008 6Document31 paginiMca 2008 6Catalin CrisanÎncă nu există evaluări
- Analiza ClusterDocument7 paginiAnaliza ClusterInes AndrasiÎncă nu există evaluări
- Analiza Cluster Ierarhica...Document4 paginiAnaliza Cluster Ierarhica...Catalin CrisanÎncă nu există evaluări
- Analiza Cluster IerarhicaDocument7 paginiAnaliza Cluster IerarhicaCatalin CrisanÎncă nu există evaluări
- Curs 8Document85 paginiCurs 8Ratiu SilviuÎncă nu există evaluări
- Analiza Cluster K MeansDocument14 paginiAnaliza Cluster K MeansCatalin CrisanÎncă nu există evaluări
- Analiza Cluster IMPORTANTDocument15 paginiAnaliza Cluster IMPORTANTCatalin CrisanÎncă nu există evaluări
- Arbori de ClasificareDocument4 paginiArbori de ClasificareCatalin CrisanÎncă nu există evaluări
- Arbori de DecizieDocument7 paginiArbori de DecizieAdriana Nicu0% (1)
- Analiza Two-Step ClusterDocument21 paginiAnaliza Two-Step ClusterhmaryusÎncă nu există evaluări
- Clusterisarea IerarhicaDocument16 paginiClusterisarea IerarhicaCatalin CrisanÎncă nu există evaluări
- Curs2 PDFDocument79 paginiCurs2 PDFCatalin CrisanÎncă nu există evaluări
- Art 01Document9 paginiArt 01Catalin CrisanÎncă nu există evaluări
- Sillabus - Disciplina Analiza DatelorDocument19 paginiSillabus - Disciplina Analiza DatelorCatalin CrisanÎncă nu există evaluări
- ESA - Statistica Actuariala - Probleme DiscutateDocument4 paginiESA - Statistica Actuariala - Probleme DiscutateCatalin CrisanÎncă nu există evaluări
- TestulKomogorov ExempluDocument1 paginăTestulKomogorov ExempluCatalin CrisanÎncă nu există evaluări