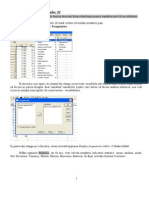
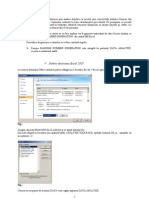
S-ar putea să vă placă și
- Proiect SPSS - CosmeticeDocument20 paginiProiect SPSS - CosmeticeAlinutza1998100% (1)
- SPSS ProiectDocument41 paginiSPSS ProiectGhicajanu IonelaÎncă nu există evaluări
- Proiect SPSSDocument48 paginiProiect SPSSgairamÎncă nu există evaluări
- Subiecte Rezolvate Econometrie 20015 PDFDocument14 paginiSubiecte Rezolvate Econometrie 20015 PDFDavid HartonÎncă nu există evaluări
- Sisteme Suport DecizieDocument9 paginiSisteme Suport DecizieLaura IoanaÎncă nu există evaluări
- Proiect SPSS EconometrieDocument8 paginiProiect SPSS EconometrieAdelina Maria CudlaÎncă nu există evaluări
- Proiect Semestrial SpssDocument26 paginiProiect Semestrial SpssMihaela PurușniucÎncă nu există evaluări
- Econometrie Subiecte Pentru ExamenDocument5 paginiEconometrie Subiecte Pentru ExamenOana RaduÎncă nu există evaluări
- Variabile HomoscedasticitateDocument20 paginiVariabile HomoscedasticitateDiana Alexandra VladÎncă nu există evaluări
- Seminar - Sapt3 - Studiul de Caz - Model ViabilDocument15 paginiSeminar - Sapt3 - Studiul de Caz - Model ViabilMatei Ruxandra MariaÎncă nu există evaluări
- Modelarea Riscului de CreditareDocument12 paginiModelarea Riscului de CreditareCosmin MihalceaÎncă nu există evaluări
- WWW - Aseonline.ro Probleme Rezolvate REGRESIEDocument22 paginiWWW - Aseonline.ro Probleme Rezolvate REGRESIEAntonescu Ioana0% (1)
- Analiza DatelorDocument15 paginiAnaliza DatelorGianina TeodoraÎncă nu există evaluări
- EconometrieeeeDocument13 paginiEconometrieeeeBianca BăhnăreanuÎncă nu există evaluări
- SIADDocument12 paginiSIADVictor CruceruÎncă nu există evaluări
- Econometria Seriilor de TimpDocument69 paginiEconometria Seriilor de TimpSergiu Martin100% (2)
- Temă EconometrieDocument4 paginiTemă EconometrieRoxana CarageaÎncă nu există evaluări
- Teme EconometrieDocument9 paginiTeme EconometrieJonas KleisÎncă nu există evaluări
- Analiza de Regresie Si CorelațieDocument7 paginiAnaliza de Regresie Si CorelațiePantofi la ComandaÎncă nu există evaluări
- Probleme Rezolvate Regresie Liniara SimplaDocument17 paginiProbleme Rezolvate Regresie Liniara SimplaYork NewÎncă nu există evaluări
- Econometrie Adriana 1Document54 paginiEconometrie Adriana 1MihaiÎncă nu există evaluări
- Proiect Model Liniar UnifactorialDocument14 paginiProiect Model Liniar UnifactorialAlina MateiaseviciÎncă nu există evaluări
- Exercitii Statistica - Partea 1Document30 paginiExercitii Statistica - Partea 1Brooke BrownÎncă nu există evaluări
- Analiza Componentelor PrincipaleDocument16 paginiAnaliza Componentelor Principalesimona100% (1)
- Moneda 1Document34 paginiMoneda 1Isabela BălașaÎncă nu există evaluări
- Proiect - Statistica Si EconometrieDocument20 paginiProiect - Statistica Si EconometrieDenisa GhiorghicăÎncă nu există evaluări
- Statistica Si Econometrie Cap 1-2Document31 paginiStatistica Si Econometrie Cap 1-2Elena-Camelia Mihai100% (1)
- Baze de Date Pentru MarketingDocument20 paginiBaze de Date Pentru MarketingStela FrineaÎncă nu există evaluări
- Econometrie AvansataDocument102 paginiEconometrie AvansataProdan IoanaÎncă nu există evaluări
- Tema 1 EconometrieDocument25 paginiTema 1 EconometrieRaduAlexandruDragoniciÎncă nu există evaluări
- Econometrie Set 1 - Probleme Rezolvate Testul T Facultatea de Marketing 2015-2016 PDFDocument9 paginiEconometrie Set 1 - Probleme Rezolvate Testul T Facultatea de Marketing 2015-2016 PDFAlexandra Cosmina ChiritaÎncă nu există evaluări
- Econometrie EViews 5Document113 paginiEconometrie EViews 5bulita69100% (2)
- Indicatorii EconomiciDocument48 paginiIndicatorii EconomiciAndrei CorladeÎncă nu există evaluări
- Formule SondajeDocument3 paginiFormule SondajeSean GilliamÎncă nu există evaluări
- Analiza Multidimensionala A DatelorDocument134 paginiAnaliza Multidimensionala A DatelorCrivat Madalina100% (1)
- Curs EconometrieDocument43 paginiCurs EconometriePaul GeorgescuÎncă nu există evaluări
- Model Bilet Statistica II Iunie 2015Document2 paginiModel Bilet Statistica II Iunie 2015Serban BogdanÎncă nu există evaluări
- Cele cinci forțe ale lui Porter: Înțelegeți forțele concurențiale și rămâneți în fața concurențeiDe la EverandCele cinci forțe ale lui Porter: Înțelegeți forțele concurențiale și rămâneți în fața concurențeiÎncă nu există evaluări
- Proiect SPSS.Document27 paginiProiect SPSS.Oana-Madalina BedregeanuÎncă nu există evaluări
- Proiect SPSSDocument50 paginiProiect SPSSNedelcu Gabriel CatalinÎncă nu există evaluări
- Aplicatie Simulare Monte Carlo VanzariDocument5 paginiAplicatie Simulare Monte Carlo VanzariAlina Paumen CravcencoÎncă nu există evaluări
- Aplicatie MLRS EViewsDocument10 paginiAplicatie MLRS EViewsAlexÎncă nu există evaluări
- Spss Curs Id2Document44 paginiSpss Curs Id2Alexandra PopaÎncă nu există evaluări
- Calcularea Indicatorilor Statistici DescriptiviDocument13 paginiCalcularea Indicatorilor Statistici DescriptiviDiana MafteiÎncă nu există evaluări
- Analiza ChestionaruluiDocument34 paginiAnaliza ChestionaruluiYzabela Isabela100% (3)
- Control Extern Interpretare Rapoarte Evaluare InfoDocument8 paginiControl Extern Interpretare Rapoarte Evaluare InfopsalminaÎncă nu există evaluări
- Ghid SPSSDocument65 paginiGhid SPSSOana ModreanuÎncă nu există evaluări
- Acd, S2, RDocument3 paginiAcd, S2, RSemida Adelina ChiriacÎncă nu există evaluări
- Descrierea Statistica A Unei Distributii Cu Variabile Categoriale Si NumericeDocument38 paginiDescrierea Statistica A Unei Distributii Cu Variabile Categoriale Si NumericeSimona Drg100% (1)
- Seminar 12Document4 paginiSeminar 12Maria GeorgescuÎncă nu există evaluări
- Proiect StatisticaDocument34 paginiProiect Statisticastudent91Încă nu există evaluări
- Proiect Statistica IDDocument4 paginiProiect Statistica IDBompa Calin Andrei100% (1)
- Analiza MultidimensionalaDocument4 paginiAnaliza MultidimensionalaAdrian DraghiciÎncă nu există evaluări
- AD Analiza CorespondentelorDocument20 paginiAD Analiza CorespondentelorBianca-Daniela PirvuÎncă nu există evaluări
- Analiza Datelor de MarketingDocument13 paginiAnaliza Datelor de MarketingAlexandru PepenicăÎncă nu există evaluări
- Cerinte Proiect Statis Manag Iarna 2014 Seria B CompressDocument6 paginiCerinte Proiect Statis Manag Iarna 2014 Seria B Compresstheo.maria3Încă nu există evaluări
- EXCELDocument7 paginiEXCELvasiu constantaÎncă nu există evaluări
- Excel ReferatDocument6 paginiExcel ReferatIrina Catrinescu100% (3)
- Spss-Aplicatie Analiza ClusterDocument11 paginiSpss-Aplicatie Analiza ClusterIoanaÎncă nu există evaluări
- Proiect SPSS MK IIIIDocument36 paginiProiect SPSS MK IIIIIleana LarisaÎncă nu există evaluări
- SUPORT CURS Proiectarea Si Organizarea CercetariiDocument58 paginiSUPORT CURS Proiectarea Si Organizarea CercetariicristinandronicÎncă nu există evaluări
- PrimariiDocument186 paginiPrimariiBogdan DelianÎncă nu există evaluări
- Volkswagen Final1Document26 paginiVolkswagen Final1Bogdan DelianÎncă nu există evaluări
- Proiect SPSSDocument38 paginiProiect SPSSBogdan DelianÎncă nu există evaluări
- VolkswagenDocument18 paginiVolkswagenBogdan DelianÎncă nu există evaluări
- COM10 - Limbajul Spatiului Si LucrurilorDocument10 paginiCOM10 - Limbajul Spatiului Si LucrurilorBogdan DelianÎncă nu există evaluări
- 1 EconomyDocument4 pagini1 EconomyBogdan DelianÎncă nu există evaluări
- Prezentarea OrganizatieiDocument19 paginiPrezentarea OrganizatieiBogdan DelianÎncă nu există evaluări
- VolkswagenDocument28 paginiVolkswagenBogdan Delian50% (2)
- Dedeman Proiect BunDocument19 paginiDedeman Proiect BunBogdan Delian100% (1)